Preface
Every JPA application that requires some kind of dynamic queries for e.g. filtering has to decide between duplicating parts of queries or building queries conditionally. JPA offers the Criteria API for constructing such dynamic queries, but using this API often results in unreadable and hard to maintain code. Concatenating query string parts is often an alternative that might even work for simple cases, but quickly falls apart in many real world scenarios. Implementing pagination with JPA and especially when fetching collections is hard to do efficiently and often sub-optimal ways are chosen for keeping maintainability.
Blaze Persistence is a library that lives on top of a JPA provider and tries to solve these and many more problems a developer faces when having complex requirements. It is composed of multiple modules that all depend on the core module which this documentation deals with.
The core module tries to ease the pain of writing dynamic queries by offering a fluent builder API that puts readability first. In addition to that, it also integrates deeply with the JPA provider to provide advanced SQL features that not even the JPA providers offer. The deep integration makes it possible to even workaround some known JPA provider bugs.
The entity view module builds on top of the core module and provides a way to define DTOs with mappings to the entity model. The mapping information is used in the query builder to generate projections that perfectly fit the DTO structure along with possible required joins.
The jpa-criteria module is an implementation of the JPA Criteria API based on the query builder of the core module. It offers extensions to the JPA Criteria API that enable the use of some of the concepts and advanced features that are also offered by the core module. The main intent of this module is to ease the migration of existing queries or to allow the use of advanced features in existing queries on a case by case basis.
Relation to JPA and implementations
You can view the Blaze Persistence core module as being a builder for query objects similar to the JPA Criteria API. The builder generally tries to check correctness as early as possible, but defers some checks to query generation time which allows to write query building code that looks almost like JPQL.
Behind the scenes Blaze Persistence core generates a JPQL query or a provider native query string. When advanced features like e.g. CTEs are used, the query string represents the logical query structure and looks very much like a possible future revision of JPQL.
The developers of Blaze Persistence see entity views as a better alternative to JPA 2.1 entity graphs which is why there is no special support for entity graphs. Nevertheless, using entity graph with queries produced by Blaze Persistence shouldn’t be a problem as long as no advanced features are used and can be applied as usual via query hints. Also note that entity graphs require a JPA 2.1 implementation whereas entity views also work with a provider that only implements JPA 2.0.
System requirements
Blaze Persistence core requires at least Java 1.7 and at least a JPA 2.0 implementation.
1. Getting started
This is a step-by-step introduction about how to get started with the core module of Blaze Persistence.
1.1. Setup
Every release comes with a distribution bundle named like blaze-persistence-dist-VERSION. This distribution contains the required artifacts for the Blaze Persistence core module as well as artifacts for integrations and other modules.
-
required - The core module artifacts and dependencies
-
entity-view - The entity view module artifacts and dependencies
-
jpa-criteria - The jpa-criteria module artifacts and dependencies
-
integration/hibernate - The integrations for various Hibernate versions
-
integration/datanucleus - The integration for DataNucleus
-
integration/eclipselink - The integration for EclipseLink
-
integration/openjpa - The integration for OpenJPA
-
integration/entity-view - Integrations for the entity view module
-
integration/querydsl - Integrations for using Blaze-Persistence through a QueryDSL like API
-
integration/quarkus - Integration for using Blaze-Persistence with Quarkus
The required artifacts are always necessary. Every other module builds up on that. Based on the JPA provider that is used, one of the integrations should be used. Other modules are optional and normally don’t have dependencies on each other.
For QueryDSL users there is an integration that is described in the QueryDSL integration chapter.
1.1.1. Maven setup
We recommend you introduce a version property for Blaze Persistence which can be used for all artifacts.
<properties>
<blaze-persistence.version>1.5.1</blaze-persistence.version>
</properties>
The required dependencies for the core module are
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-core-api</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-core-impl</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Depending on the JPA provider that should be used, one of the following integrations is required
Hibernate 5.4
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-hibernate-5.4</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Hibernate 5.3
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-hibernate-5.3</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Hibernate 5.2
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-hibernate-5.2</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Hibernate 5+
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-hibernate-5</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Hibernate 4.3
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-hibernate-4.3</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Hibernate 4.2
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-hibernate-4.2</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Datanucleus 5.1
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-datanucleus-5.1</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Datanucleus 4 and 5
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-datanucleus</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
EclipseLink
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-eclipselink</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
OpenJPA
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-openjpa</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
QueryDSL integration
When you work with QueryDSL you can additionally have first class integration by using the following dependencies.
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-querydsl-expressions</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
1.2. Environments
Blaze Persistence is usable in Java EE, Spring as well as in Java SE environments.
1.2.1. Java SE
An instance of CriteriaBuilderFactory can be obtained as follows:
CriteriaBuilderConfiguration config = Criteria.getDefault(); // optionally, perform dynamic configuration CriteriaBuilderFactory cbf = config.createCriteriaBuilderFactory(entityManagerFactory);
The Criteria.getDefault() method uses the java.util.ServiceLoader to locate
the first implementation of CriteriaBuilderConfigurationProvider on the classpath
which it uses to obtain an instance of CriteriaBuilderConfiguration.
The CriteriaBuilderConfiguration instance also allows dynamic configuration of the
factory.
The CriteriaBuilderFactory should only be built once.
|
| Creating the criteria builder factory eagerly at startup is required so that the integration can work properly. Initializing it differently might result in data races because at creation time e.g. custom functions are registered. |
1.2.2. Java EE
The most convenient way to use Blaze Persistence within a Java EE environment is by using a startup EJB and a CDI producer.
@Singleton // From javax.ejb
@Startup // From javax.ejb
public class CriteriaBuilderFactoryProducer {
// inject your entity manager factory
@PersistenceUnit
private EntityManagerFactory entityManagerFactory;
private CriteriaBuilderFactory criteriaBuilderFactory;
@PostConstruct
public void init() {
CriteriaBuilderConfiguration config = Criteria.getDefault();
// do some configuration
this.criteriaBuilderFactory = config.createCriteriaBuilderFactory(entityManagerFactory);
}
@Produces
@ApplicationScoped
public CriteriaBuilderFactory createCriteriaBuilderFactory() {
return criteriaBuilderFactory;
}
}
1.2.3. CDI
If EJBs aren’t available, the CriteriaBuilderFactory can also be configured in a CDI 1.1 specific way by creating a simple producer method like the following example shows.
@ApplicationScoped
public class CriteriaBuilderFactoryProducer {
// inject your entity manager factory
@PersistenceUnit
private EntityManagerFactory entityManagerFactory;
private volatile CriteriaBuilderFactory criteriaBuilderFactory;
public void init(@Observes @Initialized(ApplicationScoped.class) Object init) {
// no-op to force eager initialization
}
@PostConstruct
public void createCriteriaBuilderFactory() {
CriteriaBuilderConfiguration config = Criteria.getDefault();
// do some configuration
this.criteriaBuilderFactory = config.createCriteriaBuilderFactory(entityManagerFactory);
}
@Produces
@ApplicationScoped
public CriteriaBuilderFactory createCriteriaBuilderFactory() {
return criteriaBuilderFactory;
}
}
1.2.4. Spring
Within a Spring application the CriteriaBuilderFactory can be provided for injection like this.
@Configuration
public class BlazePersistenceConfiguration {
@PersistenceUnit
private EntityManagerFactory entityManagerFactory;
@Bean
@Scope(ConfigurableBeanFactory.SCOPE_SINGLETON)
@Lazy(false)
public CriteriaBuilderFactory createCriteriaBuilderFactory() {
CriteriaBuilderConfiguration config = Criteria.getDefault();
// do some configuration
return config.createCriteriaBuilderFactory(entityManagerFactory);
}
}
1.3. Supported Java runtimes
All projects are built for Java 7 except for the ones where dependencies already use Java 8 like e.g. Hibernate 5.2, Spring Data 2.0 etc. So you are going to need at least JDK 8 for building the project.
We also support building the project with JDK 9 and try to keep up with newer versions. Currently, we support building the project with Java 8 - 14. If you want to run your application on a Java 9+ JVM you need to handle the fact that JDK 9+ doesn’t export some APIs like the JAXB, JAF, javax.annotations and JTA anymore. In fact, JDK 11 removed these modules so command line flags that are sometimes advised to add modules to the classpath won’t work.
Since libraries like Hibernate and others require these APIs you need to make them available. The easiest way to get these APIs back on the classpath is to package them along with your application. This will also work when running on Java 8. We suggest you add the following dependencies.
<dependency>
<groupId>javax.xml.bind</groupId>
<artifactId>jaxb-api</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-core</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>2.2.11</version>
</dependency>
<dependency>
<groupId>javax.transaction</groupId>
<artifactId>javax.transaction-api</artifactId>
<version>1.2</version>
<!-- In a managed environment like Java EE, use 'provided'. Otherwise use 'compile' -->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.activation</groupId>
<artifactId>activation</artifactId>
<version>1.1.1</version>
<!-- In a managed environment like Java EE, use 'provided'. Otherwise use 'compile' -->
<scope>provided</scope>
</dependency>
<dependency>
<groupId>javax.annotation</groupId>
<artifactId>javax.annotation-api</artifactId>
<version>1.3.2</version>
<!-- In a managed environment like Java EE, use 'provided'. Otherwise use 'compile' -->
<scope>provided</scope>
</dependency>
Automatic module names for modules.
| Module | Automatic module name |
|---|---|
Core API |
com.blazebit.persistence.core |
Core Impl |
com.blazebit.persistence.core.impl |
Core Parser |
com.blazebit.persistence.core.parser |
JPA Criteria API |
com.blazebit.persistence.criteria |
JPA Criteria Impl |
com.blazebit.persistence.criteria.impl |
JPA Criteria JPA2 Compatibility |
com.blazebit.persistence.criteria.jpa2compatibility |
1.4. Supported environments/libraries
The bare minimum is JPA 2.0. If you want to use the JPA Criteria API module, you will also have to add the JPA 2 compatibility module. Generally, we support the usage in Java EE 6+ or Spring 4+ applications.
The following table outlines the supported library versions for the integrations.
| Module | Automatic module name | Minimum version | Supported versions |
|---|---|---|---|
Hibernate integration |
com.blazebit.persistence.integration.hibernate |
Hibernate 4.2 |
4.2, 4.3, 5.0, 5.1, 5.2, 5.3, 5.4 (not all features are available in older versions) |
EclipseLink integration |
com.blazebit.persistence.integration.eclipselink |
EclipseLink 2.6 |
2.6 (Probably 2.4 and 2.5 work as well, but only tested against 2.6) |
DataNucleus integration |
com.blazebit.persistence.integration.datanucleus |
DataNucleus 4.1 |
4.1, 5.0 |
OpenJPA integration |
com.blazebit.persistence.integration.openjpa |
N/A |
(Currently not usable. OpenJPA doesn’t seem to be actively developed anymore and no users asked for support yet) |
1.5. First criteria query
This section is supposed to give you a first feeling of how to use the criteria builder. For more detailed information, please see the subsequent chapters.
In the following we suppose cbf and em to refer to an instance of CriteriaBuilderFactory
and JPA’s EntityManager, respectively.
Take a look at the environments chapter for how to obtain a CriteriaBuilderFactory.
|
Let’s start with the simplest query possible:
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class);
This query simply selects all Cat objects and is equivalent to following JPQL query:
SELECT c FROM Cat c
Once the create() method is called the expression
returns a CriteriaBuilder<T> where T is specified via the second parameter of the
create() method and denotes the result type of the query.
The default behavior of create() is that the result type
is assumed to be the entity class from which to select. So if we would like to only select the cats' age we would have to write:
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class)
.select("cat.age");
Here we can see that the criteria builder assigns a default alias (the simple lower-case name of the entity class)
to the entity class from which we select (root entity) if we do not specify one. If we want to save some
writing, both the create() and
the from() method allow the specification of a custom alias for the root entity:
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class, "c")
.select("c.age");
Next we want to build a more complicated query. Let’s select all cats with an age between 5 and 10 years and with at least two kittens. Additionally, we would like to order the results by name ascending and by id in case of equal names.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "c")
.where("c.age").betweenExpression("5").andExpression("10")
.where("SIZE(c.kittens)").geExpression("2")
.orderByAsc("c.name")
.orderByAsc("c.id");
We have built a couple of queries so far but how can we retrieve the results? There are two possible ways:
-
List<Cat> cats = cb.getResultList();to retrieve all results -
PagedList<Cat> cats = cb.page(0, 10).getResultList();to retrieve 10 results starting from the first result (you must specify at least one unique column to determine the order of results)The
PagedList<Cat>features thegetTotalSize()method which is perfectly suited for displaying the results in a paginated table. Moreover thegetKeysetPage()method can be used to switch to keyset pagination for further paging.
2. Architecture
This is just a high level view for those that are interested about how Blaze Persistence works.
2.1. Interfaces
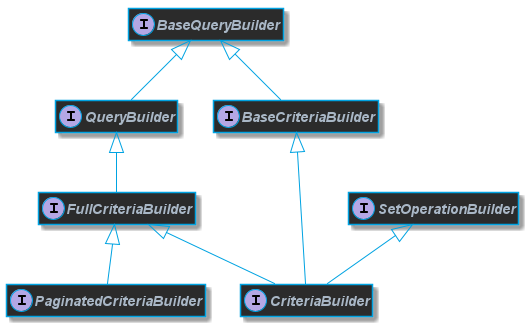
A quick overview that presents the interfaces that are essential for users and how they are related.
2.1.1. Basic functionality
Blaze Persistence has a builder API for building JPQL queries in a comfortable fashion.
The most important interfaces that a user should be concerned with are
The functionalities of the query builders are separated into base interfaces to avoid duplication where possible.
All functionality for the WHERE-clause for example can be found in com.blazebit.persistence.BaseWhereBuilder.
Analogous to that, there also exist interfaces for other clauses.
Unless some advanced features(e.g. CTEs) are used, the query string returned by every query builder is JPQL compliant and thus can also be directly compiled via EntityManager#createQuery(String).
In case of advanced features the query string that is returned might contain syntax elements which are not supported by JPQL. Some features like CTEs simply can not be modeled with JPQL,
therefore a syntax similar to SQL was used to visualize the query model. The query objects returned for such queries are custom implementations,
so beware that you can’t simply cast them to provider specific subtypes.
2.1.2. DML support
If a user uses Blaze Persistence for data manipulation too, then the following interfaces are unavoidable to know
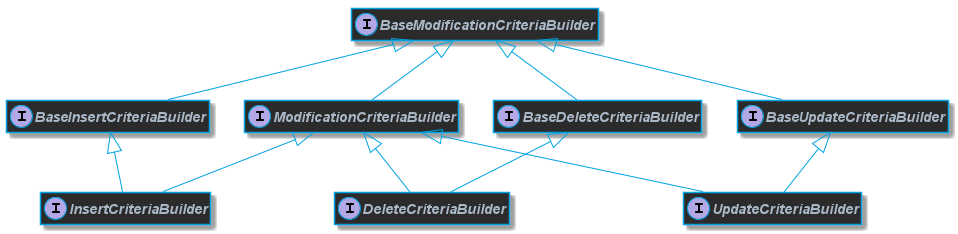
Every interface has a dual partner interface prefixed with Returning that is relevant for data manipulation queries that return results.
The Returning interfaces are only relevant when using CTEs (Common Table Expressions)
|

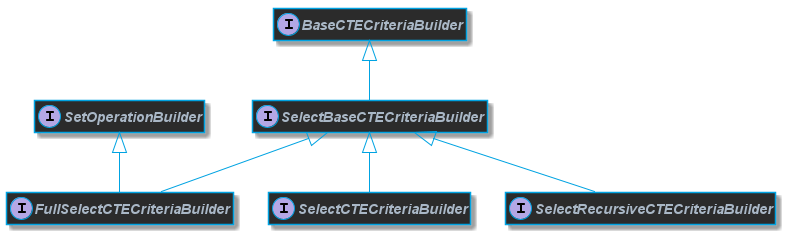
2.1.3. CTE support
CTE builders are split into two families of interface groups. One group is concerned with CTEs that do select queries, the other with DML queries.
Select CTE queries can either be recursive or non-recursive. Recursive CTEs always have a base part and a recursive part which is explicitly modeled in the API.
One starts with a com.blazebit.persistence.SelectRecursiveCTECriteriaBuilder for defining the base part
and then unions the recursive part of the query in a com.blazebit.persistence.SelectCTECriteriaBuilder.
The non-recursive builder is very similar but does not have an explicit notion of a base or recursive part. Although it supports set operations,
we do not recommend building recursive queries with the non-recursive builder especially because it’s not portable and less readable.
2.1.4. Set operations support
Every query builder has support for set operations as defined by the interface com.blazebit.persistence.SetOperationBuilder.
One can start a nested group of query builders concatenated with set operations. This group has to be ended and concatenated with another query build or another nested group.
When an empty set operation group is encountered during the query building, it is removed internally.

criteriaBuilder
.startSet(Cat.class) (1)
.startUnionAll() (2)
.endSetWith() (3)
.endSet() (4)
.unionAll() (5)
.endSet() (6)
.unionAll() (7)
.endSet() (8)
| 1 | Starting a builder with a nested set operation group returns StartOngoingSetOperationXXXBuilder |
| 2 | Starting any nested set operation group returns StartOngoingSetOperationXXXBuilder |
| 3 | Ending nested set operation group with endSetWith() to specify ordering and limiting returns OngoingFinalSetOperationXXXBuilder |
| 4 | Ending a nested set operation group with endSet() results in MiddleOngoingSetOperationXXXBuilder |
| 5 | Connecting a nested set operation group with a set operation results in OngoingSetOperationXXXBuilder |
| 6 | Ending a top level set operation nested group results in LeafOngoingFinalSetOperationXXXBuilder |
| 7 | Connecting a top level set operation group with a set operation results in LeafOngoingSetOperationXXXBuilder |
| 8 | Ending the top level set operation results in FinalSetOperationXXXBuilder |
Top-level query builder set operations
Invoking a set operation on a top level query builder results in a LeafOngoingSetOperationXXXBuilder type.
LeafOngoingSetOperationXXXBuilder types are the possible exit types for a top level set operation group.
Further connecting the builder via a set operation will produce a builder of the same type LeafOngoingSetOperationXXXBuilder.
criteriaBuilder.from(Cat.class)
.unionAll() (1)
| 1 | The set operation on a top level query builder produces LeafOngoingSetOperationXXXBuilder |
When ending such a builder via endSet(), a FinalSetOperationXXXBuilder is produced.
criteriaBuilder.from(Cat.class)
.unionAll()
.endSet() (1)
| 1 | The ending of a top level set operation builder produces FinalSetOperationXXXBuilder |
FinalSetOperationXXXBuilder types are the result of a top level set operation and once constructed only support specifying ordering or limiting.
Nested query builder set operations
Invoking a nested set operation on a query builder results in a StartOngoingSetOperationXXXBuilder type.
StartOngoingSetOperationXXXBuilder types represent a builder for a group of set operations within parenthesis.
With such a builder the normal query builder methods are available and additionally, it can end the group.
criteriaBuilder.from(Cat.class)
.startUnionAll() (1)
| 1 | The nested set operation on a query builder produces StartOngoingSetOperationXXXBuilder |
When connecting the builder with another set operation a OngoingSetOperationXXXBuilder is produced which essentially has the same functionality.
criteriaBuilder.from(Cat.class)
.startUnionAll()
.unionAll() (1)
| 1 | A set operation on a StartOngoingSetOperationXXXBuilder produces OngoingSetOperationXXXBuilder |
When ending such a top level nested builder via endSet(), a LeafOngoingFinalSetOperationXXXBuilder is produced.
criteriaBuilder.from(Cat.class)
.startUnionAll()
.endSet() (1)
| 1 | Results in LeafOngoingFinalSetOperationXXXBuilder |
Or when in a nested context, a MiddleOngoingSetOperationXXXBuilder is produced.
criteriaBuilder.from(Cat.class)
.startUnionAll()
.startUnionAll()
.endSet() (1)
| 1 | Results in MiddleOngoingSetOperationXXXBuilder |
The ending of the builder is equivalent to doing a closing parenthesis.
Since a nested group only makes sense when connecting the group with something else, the LeafOngoingFinalSetOperationXXXBuilder and MiddleOngoingSetOperationXXXBuilder only allow connecting
a new builder with a set operation or ending the whole query builder.
criteriaBuilder.from(Cat.class)
.startUnionAll()
.endSet()
.unionAll() (1)
| 1 | Results in LeafOngoingSetOperationXXXBuilder |
Or when in a nested context, a OngoingSetOperationXXXBuilder is produced.
criteriaBuilder.from(Cat.class)
.startUnionAll()
.startUnionAll()
.endSet()
.unionAll() (1)
| 1 | Results in OngoingSetOperationXXXBuilder |
Ending a nested group with endSetWith() allows to specify ordering and limiting for the group and returns a OngoingFinalSetOperationXXXBuilder.
criteriaBuilder.from(Cat.class)
.startUnionAll()
.endSetWith() (1)
| 1 | Results in OngoingFinalSetOperationXXXBuilder |
2.2. Query building
Every query builder has several clause specific managers that it delegates to. These managers contain the state for a clause and might interact with other clauses.
Depending on which query builder features are used, the query object that is produced by a query builder through getTypeQuery() or getQuery() is either the JPA provider’s native query or a custom query.
If no advanced features are used, nothing special happens. The query string is built and passed to EntityManager.createQuery() which is then returned.
When advanced features are used, an example query is built which most of the time is very similar to the original query except for advanced features.
This example query serves as a basis for execution of advanced SQL. It almost contains all the necessary parts, there is just some SQL that needs to be replaced.
If CTEs are involved, one query per CTE is built via the same mechanism and added to the participating queries list. This list is ordered and contains all query parts that are involved in an advanced query.
The ordering is important because in the end, parameters are positionally set in SQL and the order within the list represents the order of the query parts in the SQL.
All these query objects are then passed to a QuerySpecification which is capable of producing the SQL for the whole query from it’s query parts.
It serves as component that can be composed into a bigger query but also provides a method for creating a SelectQueryPlan or ModificationQueryPlan.
Such query plans represent the executable form of query specifications that are fixed. The reason for the separation between the two is that list parameters or calls to setFirstResult() and setMaxResults() could change the SQL.
The query specification is wrapped in an implementation of the JPA query interfaces javax.persistence.Query or javax.persistence.TypedQuery and a query plan is only created on demand just before executing.
Parameters, lock modes and flush modes are propagated to all necessary participating queries.
Set operations on top level queries essentially are special query specifications that contain multiple other query specifications.
To really execute such advanced queries, query plans use the ExtendedQuerySupport. It offers methods to run an JPA query with an SQL replacement and a list of participating queries.
The ExtendedQuerySupport is JPA provider specific and is responsible for proper query caching and giving access to SQL specifics of JPA query objects.
The integration of ObjectBuilder is done by introducing a query wrapper that takes results, passes them through the object builder and then returns the results.
2.3. JPA Provider Integration
The essential integration points with the JPA provider are encapsulated in EntityManagerFactoryIntegrator and ExtendedQuerySupport.
The EntityManagerFactoryIntegrator offers support for DBMS detection, function registration and
the construction of a JpaProvider through a JpaProviderFactory. The JpaProvider is a contract that can be used to query JPA provider specifics.
Some of those specifics are whether a feature like entity joins is supported but also metamodel specifics like whether an attribute has a join table.
The ExtendedQuerySupport is necessary for advanced SQL related functionality and might not be available for a JPA provider.
It provides access to SQL related information like the column names of an entity attribute or simply the SQL query for a JPA query.
3. From clause
The FROM clause contains the entities which should be queried.
Normally a query will have one root entity which is why Blaze Persistence offers a convenient factory for creating queries that select the root entity.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class);
The type Cat has multiple purposes in this case.
-
It defines the result type of the query
-
Creates an implicit query root with that type and the alias cat
-
Implicitly selects cat
This implicit logic will help to avoid some boilerplate code in most of the cases. The JPQL generated for such a simple query is just like you would expect
SELECT cat FROM Cat cat
As soon as a query root is added via from(), the implicitly created query root is removed.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Person.class, "person")
.select("person.kittens");
In such a query, the type Cat only serves the purpose of defining the query result type.
SELECT kittens_1 FROM Person person LEFT JOIN person.kittens kittens_1
Contrary to the described behavior, using the overload of the create method that allows to specify the alias for the query root will result in an explicit query root.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "myCat");
This is essentially a shorthand for
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class, "myCat");
A query can also have multiple root entities which are connected with the , operator that essentially has the semantics of a CROSS JOIN.
Beware that when having multiple root entities, path expression must use absolute paths.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "myCat")
.select("name");
The expression name in this case is interpreted as relative to the query root, so it is equivalent to myCat.name.
When having multiple query roots, the use of a relative path will lead to an exception saying that relative resolving is not allowed with multiple query roots!
3.1. Joins
JPQL offers support for CROSS, INNER, LEFT and RIGHT JOIN which are all well supported by Blaze Persistence.
In contrast to JPQL, Blaze Persistence also has a notion of implicit/default and explicit joins which makes it very convenient to write queries as can be seen a few sections later.
RIGHT JOIN support is optional in JPA so we recommend not using it at all.
|
| In addition to joins on mapped relations, Blaze Persistence also offers support for unrelated or entity joins offered by all major JPA providers. |
3.1.1. Implicit joins
An implicit or default join is a special join that can be referred to by
-
an absolute path from a root entity to an association
-
alias if an explicit alias has been defined via
joinDefault()means
| A path is considered absolute also if it is relative to the query root |
The following query builder will create an implicit join for the path kittens when inspecting the select clause and reuse that implicit join in the where clause because of the use of an absolute path.
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class)
.select("kittens.age")
.where("kittens.age").gt(1);
This will result in the following JPQL query
SELECT kittens_1.age FROM Cat cat LEFT JOIN cat.kittens kittens_1 WHERE kittens_1.age > 1
A relation dereference like alias.relation.property will always result in a JOIN being added for alias.relation.
The exception to that is when the accessed property is the identifier property of the type of relation and that identifier is owned by alias i.e. the column is contained in the owner’s table.
If the property is the identifier and the JpaProvider supports optimized id access,
no join is generated but instead the expression is rendered as it is alias.relation.identifier.
Model awareness
Implicit joins are a result of a path dereference or explicit fetching. A path dereference can happen in any place where an expression is expected.
An explicit fetch can be invoked on FullQueryBuilder instances which is the top type for
CriteriaBuilder and PaginatedCriteriaBuilder.
Every implicit join will result in a so called "model-aware" join. The model-awareness of a join is responsible for determining the join type to use.
Generally it is a good intuition to think of a model-aware join to always produce results, thus never restricting the result set but only extending it.
A model-aware join currently decides between INNER and LEFT JOIN. The INNER JOIN is only used if
-
The parent join is an
INNER JOIN -
The relation is non-optional e.g. the
optionalattribute of a@ManyToOneor@OneToOneis false
| This is different from how JPQL path expressions are normally interpreted but will result in a more natural output. |
If you aren’t happy with the join types you can override them and even specify an alias for implicit joins via the
joinDefault method and variants.
Consider the following example for illustration purposes of the implicit joins.
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class)
.select("kittens.age")
.where("kittens.age").gt(1)
.innerJoinDefault("kittens", "kitty");
The builder first creates an implicit join for kittens with the join type LEFT JOIN because a Collection can never be non-optional.
If you just had the SELECT clause, a NULL value would be produced for cats that don’t have kittens.
But in this case the WHERE clause filters out these cats, because any comparison with NULL will result in UNKNOWN and thus FALSE.
Null-aware predicates like IS NULL are obviously an exception to this.
|
The last statement will take the default/implicit join for the path kittens, set the join type to INNER and the alias to kitty.
| Although the generated aliases for implicit joins are deterministic, they might change over time so you should never use them to refer to implicit joins. Always use the full path to the join relation or define an alias and use that instead! |
3.1.2. Explicit joins
Explicit joins are different from implicit/default joins in a sense that they are only accessible through their alias. You can have only one default join which is identified by it’s absolute path, but multiple explicit joins as these are identified by their alias. This means that you can also join a relation multiple times with different aliases.
You can create explicit joins with the join() method and variants.
The following shows explicit and implicit joins used together.
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class)
.select("kittens.age")
.where("kitty.age").gt(1)
.innerJoin("kittens", "kitty");
This query will in fact create two joins. One for the explicitly inner joined kittens with the alias kitty and another for the implicitly left joined kittens used in the SELECT clause.
The resulting JPQL looks like the following
SELECT kittens_1.age FROM Cat cat INNER JOIN cat.kittens kitty LEFT JOIN cat.kittens kittens_1 WHERE kitty.age > 1
3.1.3. Fetched joins
Analogous to the FETCH keyword in JPQL, you can specify for every join node of a FullQueryBuilder if it should be fetched.
Every join() method variant comes with a partner method,
that does fetching for the joined path. In addition to that, there is also a simple fetch() method which can be provided with absolute paths to relations.
These relations are then implicit/default join fetched, i.e. a default join node with fetching enabled is created for every relation.
You can make use of deep paths like kittens.kittens which will result in fetch joining two levels of kittens.
|
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class)
.leftJoinFetch("father", "dad")
.whereOr()
.where("dad").isNull()
.where("dad.age").gt(1)
.endOr()
.fetch("kittens.kittens", "mother");
The father relation is left join fetched and given an alias which is then used in the WHERE clause. Two levels of kittens and the mother relation are join fetched.
SELECT cat FROM Cat cat LEFT JOIN FETCH cat.father dad LEFT JOIN FETCH cat.kittens kittens_1 LEFT JOIN FETCH kittens_1.kittens kittens_2 LEFT JOIN FETCH cat.mother mother_1 WHERE dad IS NULL OR dad.age > 1
| Although the JPA spec does not specifically allow aliasing fetch joins, every major JPA provider supports this. |
When doing a scalar select instead of a query root select, Blaze Persistence automatically adapts the fetches to the new fetch owners.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class)
.fetch("father.kittens")
.select("father");
In this case we fetch the father relation and the kittens of the father. By also selecting the father relation, the fetch owner changes from the query root to the father.
This has the effect, that the father is not fetch joined, as that would be invalid.
SELECT father_1 FROM Cat cat LEFT JOIN cat.father father_1 LEFT JOIN FETCH father_1.kittens kittens_1
3.1.4. Array joins
Array joins are an extension to the JPQL grammar which offer a convenient way to create joins with an ON clause condition.
An array join expression is a path expression followed by an opening bracket, the index expression and then the closing bracket e.g. arrayBase[indexPredicateOrExpression].
The type of the arrayBase expression must be an association. If it is an indexed List e.g. uses a @OrderColumn or a Map it is possible to use an expression.
In case of an indexed list, the type of the indexPredicateOrExpression must be numeric. For maps, the type must match the map key type as defined in the entity.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class)
.select("localizedName[:language]")
.where("localizedName[:language]").isNotNull();
Such a query will result in the following JPQL
SELECT localizedName_language
FROM Cat cat
LEFT JOIN cat.localizedName localizedName_language
ON KEY(localizedName_language) = :language
WHERE localizedName_language IS NOT NULL
The relation localizedName is assumed to be a map of type Map<String, String> which maps a language code to a localized name.
The more general approach is to use a predicate expression that allows to filter an association.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class)
.select("kittens[age > 18].id")
.select("kittens[age > 18].name");
Such a query will result in the following JPQL
SELECT kittens_age___18.id, kittens_age___18.name
FROM Cat cat
LEFT JOIN cat.kittens kittens_age___18
ON kittens_age___18.age > 18
Note that it is also possible to use an entity name as base expression for an array expression, which is called an entity array expression.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class)
.select("Cat[age > 18].id")
.select("Cat[age > 18].name");
Such a query will result in the following JPQL
SELECT kittens_age___18.id, kittens_age___18.name
FROM Cat cat
LEFT JOIN Cat Cat___age___18
ON kittens_age___18.age > 18
| In case of array expressions, the generated implicit/default join node is identified not only by the absolute path, but also by the index expression. |
3.1.5. Correlated joins
JPQL allows subqueries to refer to a relation based on a join alias of the outer query within the from clause, also known as correlated join. A correlated join in Blaze Persistence can be done when initiating a subquery or be added as cross join to an existing subquery builder.
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.from(Cat.class, "c")
.selectSubquery()
.from("c.kittens", "kitty")
.select("COUNT(kitty.id)")
.end();
Such a query will result in the following JPQL
SELECT
(
SELECT COUNT(kitty.id)
FROM c.kittens kitty
)
FROM Cat c
Although JPA does not mandate the support for subqueries in the SELECT clause, every major JPA provider supports it.
|
You can even use the OUTER function or macros within the correlation join path!
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.from(Cat.class, "c")
.selectSubquery()
.from("OUTER(kittens)", "kitty")
.select("COUNT(kitty.id)")
.end();
This will result in the same JPQL as before as OUTER will refer to the query root of the outer query.
SELECT
(
SELECT COUNT(kitty.id)
FROM c.kittens kitty
)
FROM Cat c
3.1.6. Entity joins
An entity join is a type of join for unrelated entities, in the sense that no JPA mapping is required to join the entities. Entity joins are quite useful, especially when information from separate models(i.e. models that have no static dependency on each other) should be queried.
| Entity joins are only supported in newer versions of JPA providers(Hibernate 5.1+, EclipseLink 2.4+, DataNucleus 5+) |
Imagine a query that reports the count of people that are older than a cat for each cat
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.from(Cat.class, "c")
.leftJoinOn(Person.class, "p")
.on("c.age").ltExpression("p.age")
.end()
.select("c.name")
.select("COUNT(p.id)")
.groupBy("c.id", "c.name");
The JPQL representation looks just as expected
SELECT c.name, COUNT(p.id)
FROM Cat c
LEFT JOIN Person p
ON c.age < p.age
GROUP BY c.id, c.name
Entity joins normally require a base alias but default to the query root when only a single query root is available.
INNER entity joins don’t need support from the JPA provider because these are rewritten to a JPQL compliant CROSS JOIN if necessary.
|
3.2. On clause
The ON clause is a filter predicate similar to the WHERE clause, but is evaluated while joining to restrict the joined elements.
In case of INNER joins the ON clause has the same effect as when putting the predicate into the WHERE clause.
However LEFT joins won’t filter out objects from the source even if the predicate doesn’t match any joinable object, but instead will produce a NULL value for the joined element.
The ON clause is used when using array joins to restrict the key of a join to the index expression.
Since the ON clause is only supported as of JPA 2.1, the usage with JPA 2.0 providers that have no equivalent vendor extension will fail.
|
The ON clause can be constructed by setting a JPQL predicate expression with setOnExpression() or by using the predicate builder>, Predicate Builder API.
| setOnExpression() | Predicate Builder API |
|---|---|
CriteriaBuilder<String> cb =
cbf.create(em, String.class)
.from(Cat.class)
.select("l10nName")
.leftJoinOn("localizedName", "l10nName")
.setOnExpression("KEY(l10nName) = :lang")
.where("l10nName").isNotNull();
|
CriteriaBuilder<String> cb =
cbf.create(em, String.class)
.from(Cat.class)
.select("l10nName")
.leftJoinOn("localizedName", "l10nName")
.on("KEY(l10nName)").eq(":lang")
.end()
.where("l10nName").isNotNull();
|
The resulting JPQL looks as expected
SELECT localizedNameForLanguage
FROM Cat cat
LEFT JOIN cat.localizedName l10nName
ON KEY(l10nName) = :lang
WHERE l10nName IS NOT NULL
3.3. VALUES clause
The VALUES clause is similar to the SQL VALUES clause in the sense that it allows to define a temporary set of objects for querying.
There are 3 different types of values for which a VALUES clause can be created
-
Basic values (Integer, String, etc.)
-
Managed values (Entities, Embeddables, CTEs)
-
Identifiable values (Entities, CTEs)
For query caching reasons, a VALUES clause has a fixed number of elements. If you bind a collection that has a smaller size, behind the scenes the rest is filled up with NULL values which are filtered out by a WHERE clause automatically.
Trying to bind a collection with a larger size will lead to an exception at bind time.
The VALUES clause is a feature that can be used for doing efficient batching. The number of elements can serve as batch size. Processing a collection iteratively and binding subsets to a query efficiently reuses query caches.
For one-shot or rarely executed queries it might not be necessary to implement batching.
In such cases use one of the overloads that use the collection size as number of elements.
The join alias that must be defined for a VALUES clause is reused as alias for the parameter to bind values.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.fromValues(String.class, "myValue", 10)
.select("myValue")
.setParameter("myValue", valueCollection);
For some cases it might be better to make use of entity functions instead of a VALUES
|
3.3.1. Basic values
The following basic value types are supported
-
Boolean -
Byte -
Short -
Integer -
Long -
Float -
Double -
Character -
String -
BigInteger -
BigDecimal -
java.sql.Time -
java.sql.Date -
java.sql.Timestamp -
java.util.Date -
java.util.Calendar
via the fromValues(Class elementType, String alias, int size) method.
Collection<String> valueCollection = Arrays.asList("value1", "value2");
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.fromValues(String.class, "myValue", valueCollection)
.select("myValue");
The resulting logical JPQL doesn’t include individual parameters, but specifies the count of the values. The alias of the values clause from item also represents the parameter name.
SELECT myValue FROM String(2 VALUES) myValue
Behind the scenes, a type called ValuesEntity is used to be able to implement the VALUES clause.
For further information on TREAT functions, take a look at the JPQL functions chapter.
3.3.2. Non-Standard basic values
To support non-standard basic types the fromValues(Class entityType, String attribute, String alias, int size) method has to be used which will determine the proper SQL type based on the SQL type of the specified entity attribute.
Collection<String> valueCollection = Arrays.asList("value1", "value2");
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.fromValues(Cat.class, "name", "myValue", valueCollection)
.select("myValue");
The logical JPQL encodes this as
SELECT myValue FROM String(2 VALUES LIKE Cat.name) myValue
3.3.3. Managed values
Managed values are objects of a JPA managed type i.e. entities or embeddables. A VALUES clause for such types will include all properties of that type,
so be careful when using this variant. For using only the id part of a managed type, take a look at the identifiable values variant.
If using all properties of an entity or embeddable is not appropriate for you, you should consider creating a custom CTE entity that covers only the subset of properties you are interested in
and finally convert your entity or embeddable object to that new type so it can be used with the VALUES clause.
Let’s look at an example
@Embeddable
class MyEmbeddable {
private String property1;
private String property2;
}
The embeddable defines 2 properties and a VALUES query for objects of that type might look like this
Collection<MyEmbeddable> valueCollection = ...
CriteriaBuilder<MyEmbeddable> cb = cbf.create(em, MyEmbeddable.class)
.fromValues(MyEmbeddable.class, "myValue", valueCollection)
.select("myValue");
The JPQL for such a query looks roughly like the following
SELECT myValue FROM MyEmbeddable(1 VALUES) myValue
3.3.4. Identifiable values
Identifiable values are also objects of a JPA managed type, but restricted to identifiable managed types i.e. no embeddables.
Every entity and CTE entity is an identifiable managed type and can thus be used in
fromIdentifiableValues().
The main difference to the managed values variant is that only the identifier properties of the objects are bound instead of all properties.
Let’s look at an example
Collection<Cat> valueCollection = ...
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.fromIdentifiableValues(Cat.class, "cat", valueCollection)
.select("cat.id");
The JPQL for such a query looks roughly like the following
SELECT cat.id FROM Cat.id(1 VALUES) cat
The values parameter "cat" will still expect instances of the type Cat, but will only bind the id attribute values.
This also works for embedded ids and access to the embedded values works just like expected, by dereferencing the embeddable further i.e. alias.embeddable.property
| When using the identifiable values, only the id values are available for the query. Using any other property will lead to an exception. |
3.4. Before and after DML in CTEs
When using DML in CTEs it depends on the DBMS what state a FROM element might give.
Normally this is not problematic as it is rarely necessary to do DML and a SELECT for the same entity in one query.
When it is necessary to do that, it is strongly advised to make use of fromOld()
or fromNew() to use the state before or after side-effects happen.
For example usage and further information, take a look into the Updatable CTEs chapter
3.5. Subquery in FROM clause
In SQL, a from clause item must be a relation which is usually a table name but can also be a subquery, yet most ORMs do not support that directly.
Blaze Persistence implements support for subqueries in the FROM clause by requiring the return type of a subquery to be an entity or CTE type.
This is similar to how inlined CTEs work and in fact, under the hood, CTE builders are used to make this feature work. For more information about CTEs, go to the CTE documentation section.
Before a subquery can be constructed, one has to think of an entity or CTE type that represents the result of the subquery. Consider the following CTE entity as an example.
@CTE
@Entity
class ResultCte {
@Id
private Long id;
private String name;
}
This CTE entity can then be used as result type for a subquery in fromSubquery().
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.fromSubquery(ResultCte.class, "r")
.from(Cat.class, "subCat")
.bind("id").select("id")
.bind("id").select("name")
.orderByDesc("age")
.orderByDesc("id")
.setMaxResults(5)
.end()
.select("r.id");
The example doesn’t really make sense, it just tries to show off the possibilities. The JPQL for such a query looks roughly like the following
SELECT r.id
FROM ResultCte(
SELECT subCat.id, subCat.name
FROM Cat subCat
ORDER BY subCat.age DESC, subCat.id DESC
LIMIT 5
) r(id, name)
Using a dedicated entity or CTE class for a subquery result and binding every attribute might make sense for some cases,
but most of the time, it is sufficient to re-bind all entity attributes again i.e. the result type matches the query root type Cat.
To help with writing such queries, the fromEntitySubquery() method can be used.
Databases are pretty good at eliminating unnecessary/unused projections in such scenarios, so it’s no big deal to use this short-cut if applicable.
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.fromEntitySubquery(Cat.class, "r")
.orderByDesc("age")
.orderByDesc("id")
.setMaxResults(5)
.end()
.select("r.id");
will result in something like the following:
SELECT r.id
FROM Cat(
SELECT r_1.age, r_1.father.id, r_1.id, r_1.mother.id, r_1.name
FROM Cat r_1
ORDER BY r_1.age DESC, r_1.id DESC
LIMIT 5
) r(age, father.id, id, mother.id, name)
As can be seen, all owned entity attributes of the type Cat are bound again.
Apart from the fromXXX methods there is also support for joining such subqueries via
the joinOnSubquery()
and joinOnEntitySubquery()
methods or the join type specific variants.
3.6. Lateral subquery join
Blaze Persistence offers support for doing lateral joins via the methods
joinLateralOnSubquery()
and joinLateralOnEntitySubquery().
A lateral join, which might also be known as cross apply or outer apply, allows to refer to aliases on the left side of the subquery i.e. the alias of the join base.
Such a join is like a correlated subquery for the FROM clause.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "c")
.leftJoinLateralOnEntitySubquery("c.kittens", "topKitten", "kitten")
.orderByDesc("age")
.orderByDesc("id")
.setMaxResults(5)
.end()
.on("1").eqExpression("1")
.end()
.select("c.name")
.select("COUNT(topKitten.id)");
The example query shows a special feature of lateral joins, which is the possibility to correlate a collection for a lateral join.
This could also have been written by correlating an entity type and defining the correlation for the collection in the WHERE clause manually.
The resulting JPQL might look like the following:
SELECT c.name, COUNT(topKitten.id)
FROM Cat c
LEFT JOIN LATERAL Cat(
SELECT kitten.age, kitten.father.id, kitten.id, kitten.mother.id, kitten.name
FROM Cat kitten
ORDER BY kitten.age DESC, kitten.id DESC
LIMIT 5
) topKitten(age, father.id, id, mother.id, name) ON 1=1
GROUP BY c.name
Note that lateral joins only work for inner and left joins. Also, not all databases support lateral joins. H2 and HSQL do not support that feature. MySQL only supports this since version 8. Oracle supports this since version 12.
4. Predicate Builder
The Predicate Builder API tries to simplify construction but also the reuse of predicates. There are multiple clauses and expressions that support entering the API:
Every predicate builder follows the same scheme:
-
An entry method can be used to start the builder with the left hand side of a predicate
-
Entry methods are additive, and finishing a predicate results in adding that to the compound predicate
-
Once a predicate has been started, it must be properly finished
-
On the top level, a method to directly set a JPQL predicate expression is provided
| Subqueries are not supported to be directly embedded into expressions but instead have to be built with the builder API. |
There are multiple different entry methods to cover all possible usage scenarios. The entry methods are mostly named after the clause in which they are defined
e.g. in the WHERE clause the entry methods are named where(), whereExists() etc.
The following list of possible entry methods refers to WHERE clause entry methods for easier readability.
where(String expression)-
Starts a builder for a predicate with the given expression on the left hand side.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.where("name").eq("Felix");
SELECT cat FROM Cat cat WHERE cat.name = :param_1
whereExists()&whereNotExists()-
Starts a subquery builder for an exists predicate.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.whereExists()
.from(Cat.class, "subCat")
.select("1")
.where("subCat").notEqExpression("cat")
.where("subCat.name").eqExpression("cat.name")
.end();
SELECT cat FROM Cat cat WHERE EXISTS (SELECT 1 FROM Cat subCat WHERE subCat <> cat AND subCat.name = cat.name)
whereCase()-
Starts a general case when builder for a predicate with the resulting case when expression on the left hand side.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.whereCase()
.when("cat.name").isNull()
.then(1)
.when("LENGTH(cat.name)").gt(10)
.then(2)
.otherwise(3)
.eqExpression(":someValue");
SELECT cat FROM Cat cat
WHERE CASE
WHEN cat.name IS NULL THEN :param_1
WHEN LENGTH(cat.name) > 10 THEN :param_2
ELSE :param_3
END = :someValue
whereSimpleCase(String expression)-
Starts a general case when builder for a predicate with the resulting case when expression on the left hand side.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.whereSimpleCase("SUBSTRING(cat.name, 1, 2)")
.when("'Dr.'", "'Doctor'")
.when("'Mr'", "'Mister'")
.otherwise("'Unknown'")
.notEqExpression("cat.fullTitle");
SELECT cat FROM Cat cat
WHERE CASE SUBSTRING(cat.name, 1, 2)
WHEN 'Dr.' THEN 'Doctor'
WHEN 'Mr.' THEN 'Mister'
ELSE 'Unknown'
END <> cat.fullTitle
whereSubquery()-
Starts a subquery builder for a predicate with the resulting subquery expression on the left hand side.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.whereSubquery()
.from(Cat.class, "subCat")
.select("subCat.name")
.where("subCat.id").eq(123)
.end()
.eqExpression("cat.name");
SELECT cat FROM Cat cat WHERE (SELECT subCat.name FROM Cat subCat WHERE subCat.id = :param_1) = cat.name
whereSubquery(String subqueryAlias, String expression)-
Like
whereSubquery()but instead theexpressionis used on the left hand side. Occurrences of subqueryAlias in the expression will be replaced by the subquery expression.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.whereSubquery("subQuery1", "subQuery1 + 10")
.from(Cat.class, "subCat")
.select("subCat.age")
.where("subCat.id").eq(123)
.end()
.gt(10);
SELECT cat FROM Cat cat WHERE (SELECT subCat.age FROM Cat subCat WHERE subCat.id = :param_1) + 10 > 10
whereSubqueries(String expression)-
Starts a subquery builder capable of handling multiple subqueries and uses the given
expressionon the left hand side of the predicate. Subqueries are started withwith(String subqueryAlias)and aliases occurring in the expression will be replaced by the respective subquery expressions.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.whereSubqueries("subQuery1 + subQuery2")
.with("subQuery1")
.from(Cat.class, "subCat")
.select("subCat.age")
.where("subCat.id").eq(123)
.end()
.with("subQuery2")
.from(Cat.class, "subCat")
.select("subCat.age")
.where("subCat.id").eq(456)
.end()
.end()
.gt(10);
SELECT cat FROM Cat cat
WHERE (SELECT subCat.age FROM Cat subCat WHERE subCat.id = :param_1)
+ (SELECT subCat.age FROM Cat subCat WHERE subCat.id = :param_2) > 10
whereOr()&whereAnd()-
Starts a builder for a nested compound predicate. Elements of that predicate are connected with
ORorANDrespectively.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.whereOr()
.where("cat.name").isNull()
.whereAnd()
.where("LENGTH(cat.name)").gt(10)
.where("cat.name").like().value("F%").noEscape()
.endAnd()
.endOr();
SELECT cat FROM Cat cat WHERE cat.name IS NULL OR LENGTH(cat.name) > :param_1 AND cat.name LIKE :param_2
setWhereExpression(String expression)-
Sets the
WHEREclause to the given JPQL predicate expression overwriting existing predicates.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.setWhereExpression("cat.name IS NULL OR LENGTH(cat.name) > 10 AND cat.name LIKE 'F%'");
SELECT cat FROM Cat cat WHERE cat.name IS NULL OR LENGTH(cat.name) > 10 AND cat.name LIKE 'F%'
setWhereExpressionSubqueries(String expression)-
A combination of
setWhereExpressionandwhereSubqueries. Sets theWHEREclause to the given JPQL predicate expression overwriting existing predicates. Subqueries replace aliases in the expression.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.setWhereExpressionSubqueries("cat.name IS NULL AND subQuery1 + subQuery2 > 10")
.with("subQuery1")
.from(Cat.class, "subCat")
.select("subCat.age")
.where("subCat.id").eq(123)
.end()
.with("subQuery2")
.from(Cat.class, "subCat")
.select("subCat.age")
.where("subCat.id").eq(456)
.end()
.end();
SELECT cat FROM Cat cat
WHERE cat.name IS NULL
AND (SELECT subCat.age FROM Cat subCat WHERE subCat.id = :param_1)
+ (SELECT subCat.age FROM Cat subCat WHERE subCat.id = :param_2) > 10
4.1. Restriction Builder
The restriction builder is used to build a predicate for an existing left hand side expression and chains to the right hand side expression. It supports all standard predicates from JPQL and expressions can be of the following types:
- Value/Parameter
-
The actual value will be registered as parameter value and a named parameter expression will be added instead. Methods that accept values typical accept arguments of type
Object. - Expression
-
A JPQL scalar expression can be anything. A path expression, literal, parameter expression, etc.
- Subquery
-
A subquery is always created via a subquery builder. Variants for replacing aliases in expressions with subqueries also exist.
Available predicates
BETWEEN&NOT BETWEEN-
The
betweenmethods expect the start value and chain to the between builder which is terminated with the end value.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.where("cat.age").between(1).and(10)
.where("cat.age").notBetween(5).and(6);
SELECT cat FROM Cat cat WHERE cat.age BETWEEN :param_1 AND :param_2 AND cat.age NOT BETWEEN :param_3 AND :param_4
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.where("cat.age").notEq(10)
.where("cat.age").ge().all()
.from(Cat.class, "subCat")
.select("subCat.age")
.end();
SELECT cat FROM Cat cat
WHERE cat.age <> :param_1
AND cat.age >= ALL(
SELECT subCat.age
FROM Cat subCat
)
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.where("cat.age").in(1, 2, 3, 4)
.where("cat.age").notIn()
.from(Cat.class, "subCat")
.select("subCat.age")
.where("subCat.name").notEqExpression("cat.name")
.end();
SELECT cat FROM Cat cat
WHERE cat.age IN (:param_1, :param_2, :param_3, :param_4)
AND cat.age NOT IN(
SELECT subCat.age
FROM Cat subCat
WHERE subCat.name <> cat.name
)
IS NULL&IS NOT NULL-
A simple null check.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.where("cat.age").isNotNull();
SELECT cat FROM Cat cat WHERE cat.age IS NOT NULL
IS EMPTY&IS NOT EMPTY-
Checks if the left hand side is empty. Only valid for path expressions that evaluate to collections.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.where("cat.kittens").isNotEmpty();
SELECT cat FROM Cat cat WHERE cat.kittens IS NOT EMPTY
MEMBER OF&NOT MEMBER OF-
Checks if the left hand side is a member of the collection typed path expression.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.where("cat.father").isNotMemberOf("cat.kittens");
SELECT cat FROM Cat cat WHERE cat.father NOT MEMBER OF cat.kittens
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.where("cat.name").like().value("Bill%").noEscape()
.where("cat.name").notLike(false).expression("'%abc%'").noEscape();
SELECT cat FROM Cat cat
WHERE cat.name LIKE :param_1
AND UPPER(cat.name) NOT LIKE UPPER('%abc%')
4.2. Case When Expression Builder
The binary predicates EQ, NOT EQ, LT, LE, GT & GE also allow to create case when expressions for the right hand side via a builder API.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.where("cat.name").eq()
.caseWhen("cat.father").isNotNull()
.thenExpression("cat.father.name")
.caseWhen("cat.mother").isNotNull()
.thenExpression("cat.mother.name")
.otherwise("Billy");
SELECT cat
FROM Cat cat
LEFT JOIN cat.father father_1
LEFT JOIN cat.mother mother_1
WHERE cat.name = CASE
WHEN father_1 IS NOT NULL
THEN father_1.name
WHEN mother_1 IS NOT NULL
THEN mother_1.name
ELSE
:param_1
END
5. Where clause
The WHERE clause has mostly been described already in the Predicate Builder chapter.
The clause is applicable to all statement types, but implicit joins are only possible in SELECT statements,
therefore it is advised to move relation access to an exists subquery in DML statements like
CriteriaBuilder<Integer> cb = cbf.update(em, Cat.class, "c")
.setExpression("age", "age + 1")
.whereExists()
.from(Cat.class, "subCat")
.where("subCat.id").eqExpression("c.id")
.where("subCat.father.name").like().value("Bill%").noEscape()
.end();
Which will roughly render to the following JPQL
UPDATE Cat c
SET c.age = c.age + 1
WHERE EXISTS(
SELECT 1
FROM Cat subCat
LEFT JOIN subCat.father father_1
WHERE subCat.id = c.id
AND father_1.name LIKE :param_1
)
5.1. Keyset pagination support
Keyset pagination or scrolling/filtering is way to efficiently paginate or scroll through a large data set. The idea of a keyset is, that every tuple can be uniquely identified by that keyset. Pagination only makes sense when the tuples in a data set are ordered and keyset pagination in contrast to offset pagination makes efficient use of the ordering property of the data set. By remembering the highest and lowest keysets of a page, it is possible to query the previous and next pages efficiently.
Apart from the transparent keyset pagination support, it is also possible to implement keyset scrolling/filtering manually.
A keyset consists of the values of the ORDER BY expressions of a tuple and the last expression must uniquely identify a tuple.
The id of an entity is not only a good candidate in general for the last expression, but also currently the only possible expression to satisfy this constraint.
The following query will order cats by their birthday and second by their id.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class, "cat")
.orderByAsc("cat.birthday")
.orderByAsc("cat.id")
SELECT cat FROM Cat cat ORDER BY cat.birthday ASC, cat.id ASC
5.1.1. Positional keyset pagination
In order to receive only the first 10 cats you would do
List<Cat> cats = cb.setMaxResults(10)
.getResultList();
In order to receive the next cats after the last seen cat (highest keyset) with positional keyset elements you would do
Cat lastCat = cats.get(cats.size() - 1);
List<Cat> nextCats = cb.afterKeyset(lastCat.getBirthday(), lastCat.getId())
.getResultList();
which roughly translates to the following JPQL
SELECT cat FROM Cat cat
WHERE cat.birthday > :_keysetParameter_0 OR (
cat.birthday = :_keysetParameter_0 AND
cat.id > :_keysetParameter_1
)
ORDER BY cat.birthday ASC NULLS LAST, cat.id ASC NULLS LAST
The positional part roughly means that the keyset element as passed into afterKeyset()
or beforeKeyset() must match the order of the corresponding ORDER BY expressions.
Note that this is in general much more efficient than an OFFSET based paging/scrolling because this approach can scroll to the next and previous page in O(log n),
whereas using OFFSET results in a complexity of O(n), thus making it harder to get to latter pages in big data sets.
This is due to how a keyset paginated query can efficiently traverse an index on the DBMS side. Using OFFSET paging requires actually counting tuples that should be skipped which is less efficient.
Similarly to scrolling to a page that comes after a keyset, it is also possible to scroll to a page that comes before a keyset
Cat firstCat = nextCats.get(0);
List<Cat> previousCats = cb.beforeKeyset(firstCat.getBirthday(), firstCat.getId())
.getResultList();
// cats and previousCats are equal
but this time the JPQL looks differently
SELECT cat FROM Cat cat
WHERE cat.birthday < :_keysetParameter_0 OR (
cat.birthday = :_keysetParameter_0 AND
cat.id < :_keysetParameter_1
)
ORDER BY cat.birthday DESC NULLS FIRST, cat.id DESC NULLS FIRST
This is how keyset pagination works, but still, the DBMS can use the same index as before. This time, it just traverses it backwards!
5.1.2. Expression based keyset pagination
This is just like positional keyset pagination but instead of relying on the order of keyset elements and ORDER BY expressions,
this makes use of the KeysetBuilder which matches by the expression.
Cat firstCat = nextCats.get(0);
List<Cat> previousCats = cb.beforeKeyset()
.with("cat.birthday", firstCat.getBirthday())
.with("cat.id", firstCat.getId())
.end()
.getResultList();
// cats and previousCats are equal
This results in the same JPQL as seen above. It’s a matter of taste which style to choose.
5.1.3. Keyset page based keyset pagination
When using the transparent keyset pagination support through the PaginatedQueryBuilder API
with keyset extraction it is possible to get access to an extracted
KeysetPage and thus also to the highest
and lowest keysets.
These keysets can also be used for paging/scrolling although when already having access to a KeysetPage it might be better to use the
PaginatedQueryBuilder API instead.
6. Group by and having clause
The GROUP BY and HAVING clause are closely. Logically the HAVING clause is evaluated after the GROUP BY clause.
A HAVING clause does not make sense without a GROUP BY clause.
6.1. Group by
When a GROUP BY clause is used, most DBMS require that every non-aggregate expression that appears in the following clauses must also appear in the GROUP BY clause
-
SELECT -
ORDER BY -
HAVING
This is due to the fact that these clauses are logically executed after the GROUP BY clause.
Some DBMS even go as far as not allowing expressions of a certain complexity in the GROUP BY clause. For such expressions,
the property/column references have to be extracted and put into the GROUP BY clause instead, so that the composite expressions can be built after grouping.
By default, the use of complex expressions is allowed in groupBy(),
but can be disabled by turning on the compatible mode.
OpenJPA only supports path expressions and simple function expression in the GROUP BY clause
|
Currently it is not possible to have a HAVING clause when using the PaginatedCriteriaBuilder API or count query generation. Also see #616
|
6.1.1. Implicit group by generation
Fortunately all these issues with different DBMS and the GROUP BY clause is handled by Blaze Persistence through implicit group by generation.
Implicit group by generation adds just the expressions that are necessary for a query to work on a DBMS without changing it’s semantics.
The generation will kick in as soon as
-
The
GROUP BYclause is used -
An aggregate function is used
If you don’t like the group by generation or you run into a bug, you can always disable it on a per-query and per-clause basis if you like.
Let’s look at an example
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class)
.select("age")
.select("COUNT(*)");
This will result in the following JPQL query
SELECT cat.age, COUNT(*) FROM Cat cat GROUP BY cat.age
The grouping is done based on the non-aggregate expressions, in this case, it is just the age of the cat.
If you disabled the implicit group by generation for the SELECT clause, the GROUP BY clause would be missing and you’d have to add it manually like
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class)
.select("age")
.select("COUNT(*)")
.groupBy("age");
which isn’t too painful at first, but can get quite cumbersome when having many expressions.
Not using implicit group by generation for the HAVING clause when using non-trivial expression like e.g. age + 1 might lead to problems on some DBMS. MySQL for example can only handle column references in the GROUP BY and doesn’t match complex expressions for the HAVING clause.
|
Subqueries are generally not allowed in the GROUP BY clause, thus correlated properties/columns have to be extracted. Implicit group by generation also takes care of that.
|
Due to the fact that subqueries are not allowed, the SIZE() function can’t be used in this clause.
|
6.1.2. Group by Entity
Although the JPA spec mandates that a JPA provider must support grouping by an entity, it is apparently not asserted by the JPA TCK.
Some implementations don’t support this feature which is why Blaze Persistence expands an entity in the GROUP BY clause automatically for you.
This also works when relying on implicit group by generation i.e.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "c")
.leftJoin("c.kittens", "kitty")
.select("c")
.select("COUNT(*)");
will result in the following logical JPQL query
SELECT c, COUNT(*) FROM Cat c LEFT JOIN c.kittens kitty GROUP BY c
but will expand c to all singular attributes of it’s type.
| Hibernate still lacks support for this feature which is one of the reasons for doing the expansion within Blaze Persistence |
6.2. Having clause
The HAVING clause is similar to the WHERE clause and most of the inner workings are described in the Predicate Builder chapter.
The only difference is that the HAVING clause in contrast to the WHERE clause can contain aggregate functions and is logically executed after the GROUP BY clause.
The API for using the HAVING clause is the same as for the WHERE clause, except that it uses having instead of the where prefix.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class)
.select("age")
.select("COUNT(*)")
.groupBy("age")
.having("COUNT(*)").gt(2);
SELECT cat.age, COUNT(*) FROM Cat cat GROUP BY cat.age HAVING COUNT(*) > :param_1
7. Order by clause
An ORDER BY clause can be used to order the underlying result list.
Depending on the mapping and the collection type in an entity, the order of elements contained in collection may or may not be preserved.
Contrary to what the JPA spec allows, Blaze Persistence also allows to use the ORDER BY clause in subqueries.
|
By default, the use of complex expressions is allowed in orderBy(),
but can be disabled by turning on the compatible mode.
Also note that by default, Blaze Persistence chose to use the NULLS LAST behavior instead of relying on the DBMS default, in order to provide better portability.
It is strongly advised to always define the null precedence in order to get deterministic results.
For convenience Blaze Persistence also offers you shorthand methods for ordering ascending or descending that make use of the default null precedence.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class)
.select("age")
.select("id")
.orderByAsc("age")
.orderByDesc("id");
SELECT cat.age, cat.id
FROM Cat cat
ORDER BY
cat.age ASC NULLS LAST,
cat.id DESC NULLS LAST
Apart from specifying the expression itself for an ORDER BY element, you can also refer to a select alias.
This is also the only way to order by the result of a subquery. Many DBMS do not support the occurrence of a subquery in ORDER BY directly, so Blaze Persistence dos not allow to do that either.
|
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class)
.selectSubquery("olderCatCount")
.from(Cat.class, "subCat")
.select("COUNT(*)")
.where("subCat.age").gtExpression("cat.age")
.end()
.select("id")
.orderByAsc("olderCatCount")
.orderByDesc("id");
SELECT
(
SELECT COUNT(*)
FROM Cat subCat
WHERE subCat.age > cat.age
) AS olderCatCount,
cat.id
FROM Cat cat
ORDER BY
olderCatCount ASC NULLS LAST,
cat.id DESC NULLS LAST
8. Select clause
The SELECT clause can be used to specify projections that should be returned by a query.
Blaze Persistence completely aligns with JPQL regarding the support of the SELECT clause,
except for constructor expressions. The reason for this is
-
Since select items are defined separately, there is no easy syntax that could be supported
-
Classes that users would like to use, might not be available on the classpath
-
The use of a fully qualified class name and pass elements by position makes the query hard to read
Instead of constructor expressions, Blaze Persistence introduces the concept of an ObjectBuilder
which, as you will see in the Select new support and Object builder chapters, are a lot mightier.
Note that by default most types of queries have a default select clause that fits most of the needs.
- Query with single root
-
Such queries have the alias of the root as default select item which has the effect that entities of the query root type are selected.
- Subquery in
EXISTS -
Uses the scalar value
1as default select item.
The defaults are replaced by the first call to one of the select() variants.
8.1. Distinct support
Distinct can be applied on any query by calling distinct().
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class)
.distinct()
.select("age");
SELECT DISTINCT cat.age FROM Cat cat
Currently it is not possible to do a distinct when using the PaginatedCriteriaBuilder API.
|
In addition to that, all aggregate functions as defined per JPQL support aggregating distinct values.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class)
.select("COUNT(DISTINCT age)");
SELECT COUNT(DISTINCT cat.age) FROM Cat cat
| This even works with embedded ids with Hibernate on DBMS that don’t support a distinct count for tuple. Also see HHH-11042 |
8.2. Tuple select
When selecting multiple expressions, you can decide between the query return types Object[] and javax.persistence.Tuple.
Some persistence providers might return the object directly when having just a single select item, even if you pass Object[]. This will not happen when using javax.persistence.Tuple as query return type.
|
You can define aliases for select items and access the tuple elements by name or by a 0-based index.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class)
.select("name", "catName")
.select("age", "catAge");
Tuple firstTuple = cb.getResultList().get(0);
// Access tuple element by alias
String name = firstTuple.get("catName", String.class);
// Access tuple element by index
Long age = firstTuple.get(1, Long.class);
SELECT cat.name, cat.age FROM Cat cat
8.3. Case expressions
The builder API for CASE WHEN in the SELECT clause is the same as for predicate builders except for different entry points.
All entry methods take an optional select alias too.
Although there is an API for constructing CASE WHEN expressions, you can also just make use of them in a normal expression of
select()
8.3.1. Searched case expression (simple case)
Simple case expressions can be done with selectSimpleCase()
and support matching a case expression by equality with an expression for every WHEN branch.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "cat")
.selectSimpleCase("SUBSTRING(cat.name, 1, 2)")
.when("'Dr'", "'Doctor'")
.when("'Mr'", "'Mister'")
.otherwise("'Unknown'")
.select("cat.age");
SELECT
CASE SUBSTRING(cat.name, 1, 2)
WHEN 'Dr.' THEN 'Doctor'
WHEN 'Mr.' THEN 'Mister'
ELSE 'Unknown'
END,
cat.age
FROM Cat cat
8.3.2. Conditional case expression
The more general form of a CASE WHEN supports arbitrary conditions in the WHEN part.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class)
.selectCase()
.when("cat.name").isNull()
.then(1)
.when("LENGTH(cat.name)").gt(10)
.then(2)
.otherwise(3)
.select("cat.age");
SELECT
CASE
WHEN cat.name IS NULL THEN :param_1
WHEN LENGTH(cat.name) > 10 THEN :param_2
ELSE :param_3
END,
cat.age
FROM Cat cat
8.4. Subqueries
Although the JPA spec does mandate support for subqueries in the SELECT clause, every major JPA provider supports it,
which is why Blaze Persistence also allows it. A subquery is the only type of expression that has to be created through the builder API, all other expressions can be created by passing the expression as string.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "cat")
.selectSubquery()
.from(Cat.class, "subCat")
.select("COUNT(*)")
.where("subCat.age").gtExpression("cat.age")
.end();
SELECT
(
SELECT COUNT(*)
FROM Cat subCat
WHERE subCa.age > cat.age
)
FROM Cat cat
8.4.1. Wrapping expression
Sometimes you might want to have more complex expressions that contain one or multiple subqueries. For such cases there are variants that accept
-
a single subquery through
selectSubquery(String, String) -
multiple subqueries through
selectSubqueries(String)
The single subquery variant requires a temporary alias for the subquery and an expression containing it. Every occurrence of the so called subqueryAlias will be replaced logically by the subquery itself.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "cat")
.selectSubquery("mySubqueryAlias", "1 + mySubqueryAlias")
.from(Cat.class, "subCat")
.select("COUNT(*)")
.where("subCat.age").gtExpression("cat.age")
.end();
SELECT
1 + (
SELECT COUNT(*)
FROM Cat subCat
WHERE subCa.age > cat.age
)
FROM Cat cat
As you can see, the subquery alias mySubqueryAlias in the expression 1 + mySubqueryAlias has been replaced by the subquery.
The multiple subquery variant is very similar, except that you first have to define the expression i.e. 1 + mySubqueryAlias1 + mySubqueryAlias2 and then,
subsequently define for each alias the respective subquery.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "cat")
.selectSubqueries("1 + mySubqueryAlias1 + mySubqueryAlias2")
.with("mySubqueryAlias1")
.from(Cat.class, "subCat")
.select("COUNT(*)")
.where("subCat.age").gtExpression("cat.age")
.end()
.with("mySubqueryAlias2")
.from(Cat.class, "subCat")
.select("COUNT(*)")
.where("subCat.age").ltExpression("cat.age")
.end()
.end();
SELECT
1 + (
SELECT COUNT(*)
FROM Cat subCat
WHERE subCa.age > cat.age
) + (
SELECT COUNT(*)
FROM Cat subCat
WHERE subCa.age < cat.age
)
FROM Cat cat
8.5. Select new support
Like already explained in the beginning, constructor expressions are supported differently in Blaze Persistence. Instead of having to use the fully qualified class name in the query, Blaze Persistence offers a concept called Object builder. On top of that API, it implements features similar to the constructor expression of JPQL.
The selectNew(Constructor) variant is probably the one that comes closest
to the constructor expression. That method allows to pass in a constructor object which will be used to construct objects when building the result list.
The argument types of the constructor must match the types of the select items.
class CatModel {
public CatModel(String name, Long age) {
//...
}
}
CriteriaBuilder<CatModel> cb = cbf.create(em, Tuple.class) (1)
.from(Cat.class, "cat")
.selectNew(CatModel.class.getConstructor(String.class, Long.class)) (2)
.with("cat.name")
.with("cat.age")
.end();
| 1 | Query type is Tuple |
| 2 | Query type changed to CatModel |
See how the query type changed because of the call to selectNew()?
The JPQL contains no information about the constructor, just the scalar selects.
SELECT cat.name, cat.age FROM Cat cat
Having to explicitly declare the parameter types for retrieving the constructor is not very convenient. That’s why there is the variant which accepts the Class instead.
That way the constructor selection is deferred to the runtime and is done based on the tuple elements types. The selection is done once based on the types of the first tuple.
CriteriaBuilder<CatModel> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "cat")
.selectNew(CatModel.class)
.with("cat.name")
.with("cat.age")
.end();
Not only looks like the one from before, but also does the same. It’s just less code that is required.
The only difference is the point in time where errors can happen. By choosing an explicit constructor at query building time,
errors like non-accessible or non-existing constructors can show up earlier. By using the Class approach, errors would only show up when processing the query results.
This behavior might change in the future i.e. due to improvements we might be able to determine the constructor already at query building time. Such a behavior could then of course be disabled if required.
8.6. Object builder
As mentioned before, the selectNew() approaches with Class and Constructor both build on top of the more general approach of ObjectBuilder.
An ObjectBuilder instance can be provided to a CriteriaBuilder
and PaginatedCriteriaBuilder via selectNew(ObjectBuilder).
It is responsible for
-
providing the JPQL expressions for select items
-
build objects of the target type from an object array representing the tuple for the select items
-
reduce the result list or simply return it
The following example should illustrate the functionality
CriteriaBuilder<CatModel> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "cat")
.selectNew(new ObjectBuilder<CatModel>() {
@Override
public <X extends SelectBuilder<X>> void applySelects(X queryBuilder) {
queryBuilder
.select("name")
.select("age");
}
@Override
public CatModel build(Object[] tuple) {
return new CatModel(
(String) tuple[0],
(Long) tuple[1]
);
}
@Override
public List<CatModel> buildList(List<CatModel> list) {
return list;
}
});
Looks like boilerplate for this simple query?
SELECT cat.name, cat.age FROM Cat cat
You are right, but keep in mind, this isn’t an API that a simple user should directly implement.
This API allows to keep the select item providing and consuming parts together, but decouple it from the actual query.
You can have one ObjectBuilder for multiple queries of the same query root.
In real life applications it is often required to have some sort of view model i.e. a model specifically for the UI. Without an API that allows to decouple the projection from the rest, you would
-
Duplicate querying code and adapt only necessary projection parts
-
Implement dynamic queries through string concatenation and essentially implement a custom query builder
-
Stick with using just the entity model and try to cope with limitations and problems
The ObjectBuilder API helps you in all these regards
-
No need to copy querying code, only need to make use of object builders and depending on the needs, use a different builder
-
Blaze Persistence already is a dynamic query builder API and strictly works with the JPA metamodel to catch errors early
-
As long as you stick to using basic values lazy loading won’t bite you
Although this simple example doesn’t do anything fancy in buildList(), you could do anything in there
-
Build nested structures
-
Filter/Sort objects
-
Query other data stores
-
etc.
The best example for a consumer of this API is the entity-view module which makes use of the ObjectBuilder interface to implement efficient projection.
Before you start building a sophisticated ObjectBuilder, take a look at entity views to see if it fits your needs.
|
9. Polymorphism
In JPA, every query is by default polymorphic. This means that whenever a FROM clause element might have subtypes, all subtypes are queried.
The JPA spec only requires providers to support polymorphic querying for entity types, but some providers allow querying also for non-managed types like interfaces.
Querying an interface is like querying all entities that implement that particular interface.
JPA 2.1 introduced the TREAT operator to downcast a polymorphic FROM clause element to a subtype so that properties of that subtype can be accessed.
Some JPA providers implemented support for an implicit or automatic downcast, but that doesn’t always work as expected, which is why Blaze Persistence only supports explicit downcasts via the TREAT operator.
Unfortunately the TREAT operator implementations of the JPA providers often do the wrong thing. This is due to the JPA spec not being explicit enough about the expected behavior and apparently the TCK not testing enough use cases.
Blaze Persistence tries hard to workaround the problems where possible so that you can make use of the TREAT operator without worrying too much.
Regardless of what the JPA spec says, Blaze Persistence allows the use of the TREAT operator in any clause, although you should note that some providers have limitations.
9.1. Limitations
Apart from Hibernate, all JPA providers have severe limitations regarding the TREAT operator support.
The only way to reliably workaround these limitations is to introduce separate joins for the desired subtypes.
Blaze Persistence currently does not implement a transparent translation to the described workaround, but may soon do.
Also see #123 for more information.
9.1.1. Hibernate
Hibernate itself does not support the treat operator very well but instead has support for implicit/automatic downcasting which is very powerful.
Blaze Persistence emulates the TREAT operator on top of Hibernate by applying type constraints to surrounding predicates or wrapping in CASE statements.
The only problems that might arise are related to Hibernate bugs.
-
multiple joins to associations that use the table per class inheritance strategy will result in ambiguous SQL
-
treat joining relations with a type that uses the table per class inheritance strategy will not work because of ambiguous SQL
-
subquery correlations that use inverse mappings only work as of Hibernate 5
-
map key associations can only be de-referenced as of Hibernate 5.2.8
-
determining the type of a map key in a subquery doesn’t work
-
multiple inner treat joins of an association with a type that uses the single table inheritance strategy, results in type constraint sharing
9.1.2. EclipseLink
EclipseLink unfortunately does not support implicit or automatic downcasting and it’s implementation of the TREAT operator is partly broken.
Blaze Persistence tries to help as good as possible by throwing exceptions for usages that are known to be broken but mostly renders through the uses of the TREAT operator.
The following limitations and problems are known
-
no support for
TREATin subquery correlations -
no support for
TREATof join alias in a join path i.e.JOIN TREAT(alias AS Subtype).propertyis not possible -
no support for
TREATof join alias in a treat join path i.e.JOIN TREAT(TREAT(alias AS Subtype).property AS Subtype)is not possible -
the
TREAToperator is not supported with the table per class inheritance strategy -
any use of the
TREAToperator will result in global filter being applied breaking left treat join semantics -
using the
TREAToperator on associations of typeMapis not supported -
using the
TREAToperator to downcast a join alias from an outer query is not supported
9.1.3. DataNucleus
DataNucleus unfortunately does not support the TREAT operator in any meaningful way. It has limited support for implicit/automatic downcasting in join paths.
Blaze Persistence tries to help as good as possible by throwing exceptions for usages that are known to be broken but mostly renders through the uses of the TREAT operator.
The following limitations and problems are known
-
no support for
TREATin subquery correlations -
no support for
TREATof join alias in a treat join path i.e.JOIN TREAT(TREAT(alias AS Subtype).property AS Subtype)is not possible -
the
TREAToperator is not supported with the joined inheritance strategy -
any use of the
TREAToperator will result in global filter being applied breaking left treat join semantics -
many more issues
9.2. Subtype property access
Every join alias and property of an alias can be polymorphic and therefore the TREAT operator can be applied to the expression.
Since every FROM element in JPA is polymorphic by default, the TREAT operator merely gives access to the subtype properties.
When the operator is used in an expression context like in a select item, the expression will return NULL if the treated element is not of the desired subtype.
Similarly the use of the operator in a conditional context like in a WHERE predicate, will make the parent predicate evaluate to false if the treated element is not of the desired subtype.
Every use of a TREAT operator has to be followed up by a de-reference i.e. TREAT(alias AS Subtype) is illegal, but TREAT(alias AS Subtype).property is legal.
|
Consider the following simple model
@Entity
class Animal {
@Id
Long id;
String name;
}
@Entity
class Cat extends Animal {
String kittyName;
}
@Entity
class Dog extends Animal {
String doggyName;
}
For simplicity this uses single table inheritance strategy but applies to all strategies. Consider the following test data.
id |
dtype |
name |
kittyName |
doggyName |
1 |
Cat |
A |
A |
NULL |
2 |
Dog |
B |
NULL |
B |
A query for animals and optionally selecting the kittyName would roughly look like this
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Animal.class, "a")
.select("name")
.select("TREAT(a AS Cat).kittyName");
The resulting query might look like the following, but might differ depending on the actual support of the JPA provider.
SELECT
a.name,
CASE WHEN TYPE(a) = Cat THEN a.kittyName END
FROM Animal a
The result list will contain 2 tuples.
Querying for a specific name i.e. using the kittyName in the WHERE clause like
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Animal.class, "a")
.select("name")
.where("TREAT(a AS Cat).kittyName").eq("A");
will actually filter the result set by adding a type restriction predicate to the parent predicate
SELECT
a.name
FROM Animal a
WHERE TYPE(a) = Cat AND a.kittyName = :param_0
The part about the parent predicate is very important. The JPA spec didn’t test for this which is why most JPA implementations got this wrong.
When the TREAT operator is for example used within an OR predicate, Blaze Persistence will handle this correctly.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Animal.class, "a")
.select("name")
.whereOr()
.where("TREAT(a AS Cat).kittyName").eq("A")
.where("a.name").eq("B")
.endOr();
This will correctly render to
SELECT
a.name
FROM Animal a
WHERE (TYPE(a) = Cat AND a.kittyName = :param_0)
OR a.name = :param_1
which will return as expected 2 tuples, the cat and the dog.
If Blaze Persistence were rendering the TREAT operator through to the JPA provider as is, most JPA implementations will behave as if the following query was written
SELECT
a.name
FROM Animal a
WHERE TYPE(a) = Cat AND (
a.kittyName = :param_0
OR a.name = :param_1
)
This will filter out the dog thus resulting in only 1 tuple in the result list which is mostly undesired.
9.3. Subtype relation join
Apart from accessing the properties of subtypes, JPA also specifies the use of the TREAT operator in a join path which allows to restrict the join scope and cast to specific subtypes.
A treat join is just like a normal join, except that it additionally uses a predicate like TYPE(alias) = Subtype in the ON clause condition and hints the runtime to restrict the joined tables.
Consider the following simple model
@Entity
class Person {
@Id
Long id;
String name;
@ManyToOne
Animal favoritePet;
}
@Entity
class Animal {
@Id
Long id;
String name;
}
@Entity
class Cat extends Animal {
String kittyName;
}
@Entity
class Dog extends Animal {
String doggyName;
}
For simplicity this uses single table inheritance strategy but applies to all strategies. Consider the following test data.
id |
name |
favoritePet |
1 |
P1 |
1 |
2 |
P2 |
NULL |
3 |
P3 |
2 |
id |
dtype |
name |
kittyName |
doggyName |
1 |
Cat |
A |
A |
NULL |
2 |
Dog |
B |
NULL |
B |
A query for cat people would roughly look like this
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Person.class, "p")
.select("p.name")
.select("c.name")
.innerJoin("TREAT(p.favoritePet AS Cat)", "c");
The resulting query might look like the following, but might differ depending on the actual support of the JPA provider.
SELECT p.name, c.name FROM Person p JOIN TREAT(p.favoritePet AS Cat) c
The result list will contain 1 tuple, that is the cat person’s name and the name of the cat.
When doing a left treat join, all people are retained.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Person.class, "p")
.select("p.name")
.select("c.name")
.leftJoin("TREAT(p.favoritePet AS Cat)", "c");
The resulting query might look like the following, but again might differ depending on the actual support of the JPA provider.
SELECT p.name, c.name FROM Person p LEFT JOIN TREAT(p.favoritePet AS Cat) c
The result list will contain 3 tuples. Note that only the tuple of the cat person P1 will have a non-null name for the favoritePet.
9.4. Querying non-managed types
Currently there is no direct support for this type of querying, but this will change soon. Also see #204
10. Expressions
Blaze Persistence supports almost all expressions that are also valid JPQL expressions and in addition to that also has some extensions. Keywords are case insensitive and optional parenthesis are ignored i.e. not reflected in the expression tree model. Expression optimizations like double invert signum and double negation simplifications can be configured via a configuration property and are enabled by default.
Almost all APIs of Blaze Persistence accept expressions as strings. A few like setWhereExpression(String), setHavingExpression(String), setOnExpression(String) require predicates as strings as they replace the whole predicate.
Predicates are a subtype of expressions that produce a boolean value. Until #340 is resolved, it is necessary to wrap predicates in a CASE WHEN expression for producing boolean values for a SELECT clause.
10.1. Identification variables
Identification variables are aliases of FROM clause elements. Since FROM clause aliases and SELECT aliases have to be unique,
you can use SELECT aliases just like FROM clause aliases. The only exception to this are ON clauses of FROM clause elements.
10.2. Path expressions
Path expressions use the navigation operator . to navigate to properties of an object. A path expression has the form of identificationVariable.attribute
where attribute is the name of an attribute which is part of the type of identificationVariable. Path expressions can also use multiple navigation operators like identificationVariable.association.attribute
where association is an object typed attribute. In general, the use of a navigation operator will result in a model aware join of the attributes.
In some cases the join will be omitted
-
The attribute is not joinable i.e. it has a basic type like
String,Integer -
The attribute has a managed type and is used in a predicate
-
The path is a single valued id expression and the JPA provider supports that. A single valued id expression is given when
-
The expression has the form
identificationVariable.association.id -
The
associationis an attribute with an entity type -
The
idis the identifier of the association’s entity type -
The column for the identifier is physically located in the table that is backing the type of
identificationVariable
10.3. Array expressions
The array expression syntax is an extension to the JPQL grammar that allows to filter an association or dedicated entity join by a predicate.
Associations that are mapped as java.util.Map and indexed java.util.List i.e. lists that use @OrderColumn, also allow to use a simple expression.
A normal path expression like identificationVariable.collection.name will create an unconditional join for the attribute collection i.e. it refers to all collection elements.
An array expression like identificationVariable.collection[:someParam].name on the other hand joins the attribute collection with a ON clause condition KEY(collection) = :someParam
if the collection is a java.util.Map and INDEX(collection) = :someParam if it is a java.util.List. So an array expression refers to a single collection element.
Since array expressions by default use the join type LEFT, the expression result is either the value for the specific element or NULL if no collection element for the key or index exists.
The array expression syntax can be used anywhere within a path expression. Even multiple uses like this are ok identificationVariable.collection1[:param1].association.collection2[:param2].attribute.
The use of a predicate like in identificationVariable.collection[LENGTH(name) <> 0].name will cause a join like LEFT JOIN identificationVariable.collection alias ON LENGTH(alias.name) <> 0.
Within an array expression, the identifier _ can be used to refer to the join alias of the array expression which is useful for using the KEY and INDEX functions
like in identificationVariable.collection[KEY(_) = :someParam].name.
10.4. Entity array expressions
An array expression can use an entity name as base expression which is called an entity array expression.
An expression like Cat[age > 18] will cause a join like LEFT JOIN Cat alias ON alias.age > 18. Repeated uses with the same predicate will resolve to the same join alias.
The implicit root node for path expressions in the predicate expression is the joined entity. To refer to the entity directly, one can use the special identifier _.
One example where this is useful is when wanting to restrict by the concrete entity type. The expression Animal[TYPE(_) = Cat] will result in LEFT JOIN Animal alias ON TYPE(alias) = Cat.
The entity array expression, just like other array expressions, can of course be de-referenced.
10.5. Treat expressions
Every expression in JPQL has a static type that can be determined through the metamodel. Since associations can refer to polymorphic types, it might be necessary to downcast identification variables or path expressions.
JPA 2.1 introduced the concept of a TREAT expression to actually downcast to a specific subtype. Blaze Persistence follows the strict rules of JPQL regarding static type resolving and thus requires the use of TREAT when accessing subtype properties.
A TREAT expression can be used in any clause and the result of such an expression is either the casted object or NULL if the object is not an instance of the requested type.
If TREAT is used as part of a predicate and an object is not of the requested type, the predicate will evaluate to FALSE.
The use of TREAT will not necessarily result in a filter for that subtype.
|
10.6. Qualified expressions
JPQL has the concept of qualified expressions for collections which is also supported in Blaze Persistence.
By default, a join for a collection or an expression using an attribute referring to a collection type, will have the collection value as type.
For allowing access to the key of a java.util.Map or the index of an indexed java.util.List, JPQL has a notion of qualification expressions.
10.6.1. VALUE
The VALUE qualification expression is used to refer to the value of a collection explicitly. Since an identification variable by default has this type, the use of VALUE can always be omitted.
10.6.2. KEY
The KEY qualification expression is used to refer to the key of a java.util.Map. If the key type is an entity type, it can be further navigated on.
WARN: Further navigation might not be supported by all JPA providers.
10.7. Parameter and Literal expressions
Blaze Persistence only supports named parameters i.e. the :parameterName notation. There are multiple reasons for not supporting positional parameters but the main one being,
that positional parameters were never needed by the authors of Blaze Persistence in any of their projects.
Values can used in a query either through a parameter expression or by rendering it as literal expression. The syntaxes for literals depend on the data type of the value
and roughly align with the syntax of EclipseLink and Hibernate.
Next to the normal literals, Blaze Persistence also has support for a NULL literal. Behind the scenes it renders as NULLIF(1,1).
10.7.1. String literals
Just like in JPQL, the values for literals of string types are enclosed in single quotes. To escape a single quote within the value, a single quote is prefixed.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.whereOr()
.where("owner.name").like().expression("'Billy'").noEscape()
.where("name").like().expression("'Billy''s cat'").noEscape()
.endOr();
SELECT cat FROM Cat cat LEFT JOIN cat.owner owner_1 WHERE owner_1.name LIKE 'Billy' OR cat.name LIKE 'Billy''s cat'
10.7.2. Numeric literals
By default, an integer literal has the type int or Integer and a decimal literal has the type double or Double. If you need other types, you can use the type suffixes.
-
LforlongorLongi.e.1L -
FforfloatorFloati.e.1.1F -
DfordoubleorDoublei.e.0D -
BIforbigintorBigIntegeri.e.1BI -
BDfordecimalorBigDecimali.e.0BD
There are no literal suffixes for the types byte and short.
10.7.3. Boolean literals
Boolean literals TRUE and FALSE are case insensitive and can appear as expression directly or as predicate.
10.7.4. Date & Time literals
Date & Time literals work with the JDBC escape syntax just like in JPQL.
Date literal::{d 'yyyy-mm-dd'}
Time literal::{t 'hh:mm:ss'}
Timestamp literal::{ts 'yyyy-mm-dd hh:mm:ss(.millis)?'} with optional milliseconds
10.7.5. Entity type literals
Whenever you compare against a TYPE() expression, you can use entity type literals.
An entity type literal is either the entity name or the fully qualified class name of the entity.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.where("TYPE(owner)").eqExpression("Student");
SELECT cat FROM Cat cat LEFT JOIN cat.owner owner_1 WHERE TYPE(owner_1) = Student
10.7.6. Enum literals
An enum literal can be used by writing the fully qualified class name of the enum followed by the enum key.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.where("cat.status").eqExpression("org.mypackage.Status.ALIVE");
SELECT cat FROM Cat cat WHERE TYPE(cat.status) = org.mypackage.Status.ALIVE
10.8. Arithmetic expressions
Arithmetic operators (+, -, *, /) are available on numeric types.
The type rules follow the JPQL rules which roughly say that if any operand in an arithmetic expression is of type …
* Double, then the result is of type Double
* Float, then the result is of type Float
* BigDecimal, then the result is of type BigDecimal
* BigInteger, then the result is of type BigInteger
* Long, then the result is of type Long
In all other cases, the result is of the type Integer.
The only exception to all of these rules is the division operator / for which the result type is undefined.
The operators can’t be used for date arithmetic. Instead the date diff functions have to be used.
10.9. Function expressions
Blaze Persistence supports a direct function call syntax FUNCTION_NAME ( (args)* ) for all functions and translates that to the JPA provider specific syntax.
Non-standard functions may also use the FUNCTION ( function_name (, args)* ) syntax that got introduced in JPA 2.1 and are handled equally.
10.9.1. String functions
Functions that return a result of type string.
CONCAT ( string1, string2 (, args)* )-
Concatenates the arguments to one string. Contrary to JPQL, this function allows varargs.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("CONCAT(cat.name, ' the cat')");
SELECT CONCAT(cat.name, ' the cat') FROM Cat cat
SUBSTRING ( string, start (, length)? )-
Returns the subsequence of the first argument beginning at
startwhich is 1-based. The length is optional.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("SUBSTRING(cat.name, 1, 2)");
SELECT SUBSTRING(cat.name, 1, 2) FROM Cat cat
TRIM ( ( (LEADING | TRAILING | BOTH)? trimChar? FROM)? string )-
Trims a character from the string. By default the whitespace character is trimmed from BOTH sides.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("TRIM(BOTH ' ' FROM cat.name)");
SELECT TRIM(BOTH ' ' FROM cat.name) FROM Cat cat
LOWER ( string )-
Returns the string in all lower case form.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("LOWER(cat.name)");
SELECT LOWER(cat.name) FROM Cat cat
UPPER ( string )-
Returns the string in all upper case form.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("UPPER(cat.name)");
SELECT UPPER(cat.name) FROM Cat cat
10.9.2. Numeric functions
Functions that return a numeric result.
LENGTH ( string )-
Returns the length of the string.
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class, "cat")
.select("LENGTH(cat.name)");
SELECT LENGTH(cat.name) FROM Cat cat
LOCATE ( string1, string2, start? )-
Returns the first position of
string2withinstring1from left to right, starting atstart. By default starts at the beginning.
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class, "cat")
.select("LOCATE(cat.name, ' ')");
SELECT LOCATE(cat.name, ' ') FROM Cat cat
ABS ( numeric )-
Returns the absolute value of the numeric value.
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class, "cat")
.select("ABS(cat.age / 3)");
SELECT ABS(cat.age / 3) FROM Cat cat
SQRT ( numeric )-
Returns the square root of the numeric value.
CriteriaBuilder<Double> cb = cbf.create(em, Double.class)
.from(Cat.class, "cat")
.select("SQRT(cat.age)");
SELECT SQRT(cat.age) FROM Cat cat
MOD ( numeric1, numeric2 )-
Returns the remainder for the division
numeric1 / numeric2.
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class, "cat")
.select("MOD(cat.age, 3)");
SELECT MOD(cat.age, 3) FROM Cat cat
The functions SIZE and INDEX also return numeric values but are described in Collection functions
10.9.3. Date & Time functions
Functions that return a result with a date or time type.
CURRENT_DATE-
Returns the databases current date.
CriteriaBuilder<java.sql.Date> cb = cbf.create(em, java.sql.Date.class)
.from(Cat.class, "cat")
.select("CURRENT_DATE");
SELECT CURRENT_DATE FROM Cat cat
CURRENT_TIME-
Returns the databases current time.
CriteriaBuilder<java.sql.Time> cb = cbf.create(em, java.sql.Time.class)
.from(Cat.class, "cat")
.select("CURRENT_TIME");
SELECT CURRENT_TIME FROM Cat cat
CURRENT_TIMESTAMP-
Returns the databases current timestamp.
CriteriaBuilder<java.sql.Timestamp> cb = cbf.create(em, java.sql.Timestamp.class)
.from(Cat.class, "cat")
.select("CURRENT_TIMESTAMP");
SELECT CURRENT_TIME FROM Cat cat
10.9.4. Collection functions
Functions that operate on collection mappings.
INDEX ( collection_join_alias )-
Returns the index of a collection element. The collection must be a
java.util.Listand have a@OrderColumn.
CriteriaBuilder<Integer> cb = cbf.create(em, Integer.class)
.from(Cat.class, "cat")
.select("INDEX(cat.favouriteKittens)");
SELECT INDEX(favouriteKittens_1) FROM Cat cat LEFT JOIN cat.favouriteKittens favouriteKittens_1
KEY ( collection_join_alias )-
Returns the key of a collection element. The collection must be a
java.util.Map.
CriteriaBuilder<AddressType> cb = cbf.create(em, AddressType.class)
.from(Person.class, "p")
.select("KEY(p.addresses)");
SELECT KEY(addresses_1) FROM Person p LEFT JOIN p.addresses addresses_1
SIZE ( collection_path )-
Returns the size of a collection.
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.from(Cat.class, "cat")
.select("SIZE(cat.favouriteKittens)");
SELECT COUNT(KEY(favouriteKittens_1)) FROM Cat cat LEFT JOIN cat.favouriteKittens favouriteKittens_1 GROUP BY cat.id
The implementation for SIZE is highly optimized and tries to avoid subqueries to improve performance. It does not delegate to the SIZE implementation of the JPA provider.
|
For more information go to the SIZE function chapter.
10.9.5. Aggregate functions
Blaze Persistence supports all aggregates as defined by JPQL and some non-standard aggregates. On top of that, it also has support for defining custom aggregate functions. For further information on custom aggregates take a look at the Custom JPQL functions chapter.
COUNT ( DISTINCT? arg )-
Returns the number of elements that are not null as
Long.
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.from(Cat.class, "cat")
.leftJoin("cat.favouriteKittens", "fav")
.select("COUNT(KEY(fav))");
SELECT COUNT(KEY(fav)) FROM Cat cat LEFT JOIN cat.favouriteKittens fav
Blaze Persistence has a custom implementation for COUNT(DISTINCT) to support counting tuples even when the JPA provider and/or DBMS do not support it natively.
|
COUNT ( * )-
Returns the number of elements as
Long.
WARN: This is a non-standard function that is not specified by JPQL but supported by all major JPA providers.
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.from(Cat.class, "cat")
.leftJoin("cat.favouriteKittens", "fav")
.select("COUNT(*)");
SELECT COUNT(*) FROM Cat cat LEFT JOIN cat.favouriteKittens fav
AVG ( DISTINCT? numeric )-
Returns the average numeric value as
Double.
CriteriaBuilder<Double> cb = cbf.create(em, Double.class)
.from(Cat.class, "cat")
.select("AVG(cat.age)");
SELECT AVG(cat.age) FROM Cat cat
MAX ( arg )-
Returns the maximum element.
CriteriaBuilder<Double> cb = cbf.create(em, Double.class)
.from(Cat.class, "cat")
.select("MAX(cat.age)");
SELECT MAX(cat.age) FROM Cat cat
MIN ( arg )-
Returns the minimum element.
CriteriaBuilder<Double> cb = cbf.create(em, Double.class)
.from(Cat.class, "cat")
.select("MIN(cat.age)");
SELECT MIN(cat.age) FROM Cat cat
SUM ( numeric )-
Returns the sum of all elements. Integral argument types have the result type
Long, except forBigIntegerwhich has the result typeBigInteger. Decimal argument types have the result typeDouble, except forBigDecimalwhich has the result typeBigDecimal.
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.from(Cat.class, "cat")
.select("SUM(cat.age)");
SELECT SUM(cat.age) FROM Cat cat
GROUP_CONCAT ( ('DISTINCT' )? , string (, 'SEPARATOR', separatorString)? (, 'ORDER BY', ( orderByExpr, ( 'ASC' | 'DESC' ) )+ ) )-
Concatenates elements to a single string connected with the
separatorStringin the requested order.
WARN: This is a non-standard function that might not be supported on all DBMS. See JPQL functions for further information.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("GROUP_CONCAT(cat.name, 'SEPARATOR', ' - ', 'ORDER BY', cat.name, 'ASC')");
SELECT GROUP_CONCAT(cat.name, 'SEPARATOR', ' - ', 'ORDER BY', cat.name, 'ASC') FROM Cat cat
10.9.6. Cast and treat functions
The cast functions offered by Blaze Persistence allow to do an SQL cast. The following data types are supported
-
Boolean-CAST_BOOLEAN -
Byte-CAST_BYTE -
Short-CAST_SHORT -
Integer-CAST_INTEGER -
Long-CAST_LONG -
Float-CAST_FLOAT -
Double-CAST_DOUBLE -
Character-CAST_CHARACTER -
String-CAST_STRING -
BigInteger-CAST_BIGINTEGER -
BigDecimal-CAST_BIGDECIMAL -
java.sql.Time-CAST_TIME -
java.sql.Date-CAST_DATE -
java.sql.Timestamp-CAST_TIMESTAMP -
java.util.Calendar-CAST_CALENDAR
The SQL type for a java type can be customized in the DBMS dialect globally. If you need to cast to other types, you need to create a custom function.
Although JPQL is strictly typed, it might not always be possible to determine an appropriate type for an expression.
For such cases Blaze Persistence created various TREAT_ functions that allow to give a subexpression an explicit type within the JPQL expression.
Normally, users shouldn’t get in touch with this directly. It is currently used internally to implement the VALUES clause and is only mentioned for completeness.
10.9.7. Function function
As of JPA 2.1 it is possible to invoke non-standard functions via the FUNCTION ( function_name (, args)* ).
By default, all non-standard functions of the JPA provider are imported. This means that you can make use of functions provided by the JPA provider with the FUNCTION ( function_name (, args)* ) syntax
as well as with the direct function call syntax function_name ( args* ) and it will get rendered into the JPA provider specific way of invoking such functions automatically.
A list of functions provided by Blaze Persistence and information on how to implement a custom function can be found in the JPQL functions chapter.
10.10. Subquery expressions
Since subqueries aren’t supported to be written as a whole but only through a builder API, Blaze Persistence offers a special API to construct complex expressions that contain subqueries. The API was explained for predicates and select expressions already. The general idea is that you introduce aliases for subqueries in a complex expression that later get replaced with the actual subquery in the expression tree.
Within subqueries, Blaze Persistence supports a function called OUTER() which can be used to refer to attributes of the parent query’s root.
By using OUTER you can avoid introducing the query root alias of the outer query into the subquery directly.
For further information on OUTER take a look into the JPQL functions chapter.
10.11. Nullif expressions
NULLIF ( arg1, arg2 )-
Returns
NULLifarg1andarg2are equal and the value ofarg1if they are not.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("NULLIF(cat.name, cat.owner.name)");
SELECT NULLIF(cat.name, owner_1.name) FROM Cat cat LEFT JOIN cat.owner owner_1
10.12. Coalesce expressions
COALESCE ( arg1, arg2 (, args)* )-
Returns the first non-
NULLargument orNULLif all arguments areNULL.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("COALESCE(cat.name, cat.owner.name, 'default')");
SELECT COALESCE(cat.name, owner_1.name, 'default') FROM Cat cat LEFT JOIN cat.owner owner_1
10.13. Case expressions
Although Blaze Persistence already supports building CASE WHEN expressions via a builder API, it also supports an expression form.
The API was explained for predicates and select expressions already.
10.13.1. Simple case expressions
CASE operand (WHEN valueN THEN resultN)+ ELSE resultOther END-
Tests if the
operandequals one ofvalueNand if so, returns the respectiveresultN, otherwise returnsresultOther.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("CASE cat.age WHEN 1 THEN 'Baby' ELSE 'Other' END");
SELECT CASE cat.age WHEN 1 THEN 'Baby' ELSE 'Other' END FROM Cat cat
10.13.2. Searched case expressions
CASE (WHEN conditionN THEN resultN)+ ELSE resultOther END-
Tests if any
conditionNevaluates to true and if so, returns the respectiveresultN, otherwise returnsresultOther.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("CASE WHEN cat.age < 2 THEN 'Baby' ELSE 'Other' END");
SELECT CASE WHEN cat.age < 2 THEN 'Baby' ELSE 'Other' END FROM Cat cat
10.14. Predicate expressions
Blaze Persistence supports constructing predicates via a builder API as has been shown in the Predicate Builder chapter,
but sometimes it is necessary to define predicates as strings.
It is necessary for CASE WHEN expressions or when wanting to replace a whole predicate via e.g. setWhereExpression(String).
Predicates can be connected with the logical operators AND and OR and form a compound predicate. Predicates can be grouped by using parenthesis and
can be prefixed with the unary operator NOT for negating the predicate.
All predicates except for null-aware predicates like e.g. IS NULL that compare against NULL, will result in UNKNOWN which is intuitively equal to FALSE.
10.15. Relational comparison predicate
expression1 ( = | <> | > | >= | < | <= | != ) ( expression2 | ( ( ALL | ANY | SOME ) subquery_alias ) )-
Compares same typed operands with one of the operators
=,<>,>,>=,<,<=. Blaze Persistence also defines the!=as synonym for the<>operator. In addition to normal comparison, relational predicates can also have a quantifier to do comparisons againstALLorANY/SOMEelements of a set.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.setWhereExpressionSubqueries("cat.age < 2 AND LENGTH(cat.name) >= ALL catNameLengths")
.with("catNameLengths")
.from(Cat.class, "subCat")
.select("LENGTH(subCat.name)")
.end()
.end();
SELECT cat
FROM Cat cat
WHERE cat.age < 2
AND LENGTH(cat.name) >= ALL (
SELECT LENGTH(subCat.name)
FROM Cat subCat
)
10.16. Nullness predicate
expression IS NOT? NULL-
Evaluates whether a value is
NULL.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.setWhereExpression("cat.owner IS NOT NULL");
SELECT cat FROM Cat cat WHERE cat.owner IS NOT NULL
10.17. Like predicate
string NOT? LIKE pattern (ESCAPE escape_character)?-
Tests if
stringmatchespattern. Theescape_charactercan be used to escape usages of the single char wildcard_and multi-char wildcard%characters inpattern.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.setWhereExpression("cat.name LIKE 'Mr.%'");
SELECT cat FROM Cat cat WHERE cat.name LIKE 'Mr.%'
10.18. Between predicate
expression1 NOT? BETWEEN expression2 AND expression3-
Between is a shorthand syntax for the tests
expression1 >=expression2 AND expression1 <= expression3.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.setWhereExpression("cat.age BETWEEN 1 AND 2");
SELECT cat FROM Cat cat WHERE cat.age BETWEEN 1 AND 2
10.19. In predicate
expression1 NOT? IN ( subquery_alias | collection_parameter | ( '(' item1 (, itemN)* ')' ) )-
The
INpredicate checks ifexpression1is contained in any of the values on the right hand side i.e. item1..itemN. Items can be parameters or literals. If just one item is given, the IN predicate is rewritten to anEQpredicate and thus allows the single item to be any expression.
When the collection value for collection_parameter is bound on the query builder of Blaze Persistence, empty collections will work as expected. Behind the scenes the IN predicate is replace by a TRUE or FALSE predicate.
|
The subquery_alias is replaced with the subquery defined via the builder API as explained in the predicates chapter and the builder section for the IN predicate.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.setWhereExpression("cat.age IN (1L, 2L, 3L, :param)");
SELECT cat FROM Cat cat WHERE cat.age IN (1L, 2L, 3L, :param)
Some JPA providers support a row-value constructor syntax which is not supported by Blaze Persistence. Consider rewriting queries that use that syntax to the EXISTS equivalent.
|
10.20. Exists predicate
NOT? EXISTS subquery_alias-
The
EXISTSpredicate checks if the subquery forsubquery_aliashas rows.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.setWhereExpressionSubqueries("EXISTS subquery_alias")
.with("subquery_alias")
.from(Cat.class, "subCat")
.where("cat").notEqExpression("subCat")
.end()
.end();
SELECT cat
FROM Cat cat
WHERE EXISTS(
SELECT 1
FROM Cat subCat
WHERE cat <> subCat
)
10.21. Empty predicate
collection_path IS NOT? EMPTY-
The
IS EMPTYpredicate checks if the collection for an element as specified bycollection_pathis empty i.e. contains no elements.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.setWhereExpression("cat.kittens IS EMPTY");
SELECT cat FROM Cat cat WHERE cat.kittens IS EMPTY
10.22. Member-of predicate
expression NOT? MEMBER OF? collection_path-
The
MEMBER OFpredicate checks ifexpressionis an element of the collection as specified bycollection_path.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.setWhereExpression("cat MEMBER OF cat.kittens");
SELECT cat FROM Cat cat WHERE cat MEMBER OF cat.kittens
11. Query API
The central element to the construction of criteria or query builders is the CriteriaBuilderFactory.
The factory provides methods for constructing DML statements, left nested set operations and
CriteriaBuilder instances for SELECT statements.
The top level query builders allow access to the query string and also to construct JPA javax.persistence.Query or javax.persistence.TypedQuery instances through the interfaces
String queryString = cbf.create(em, Cat.class, "cat")
.getQueryString();
TypedQuery<Cat> query = em.createQuery(queryString, Cat.class);
The possibility to access the query string is a convenience for debugging or monitoring, but queries should always be constructed via the respective query construction methods.
If advanced features like CTEs, Set-Operations or others are used, the query string returned really is just a logical representation of the query structure,
so don’t rely on the query string being compilable through EntityManager#createQuery().
| The constructed JPA query instances for queries that use some of the advanced features currently do not support query hints or unwrapping. |
TypedQuery<Cat> query = cbf.create(em, Cat.class, "cat")
.getTypedQuery();
Queries should always be created that way and also can be reused for the transaction just like any other query.
Blaze Persistence also offers convenience methods on the top level query builder interfaces to execute the queries
-
getSingleResult()is equivalent togetTypedQuery().getSingleResult() -
getResultList()is equivalent togetTypedQuery().getResultList() -
executeUpdate()is equivalent togetQuery().executeUpdate()
List<Cat> query = cbf.create(em, Cat.class, "cat")
.getResultList();
11.1. Parameter binding
Apart from support for binding parameters on the constructed JPA query, Blaze Persistence also allows to bind parameters on the query builder itself.
All query builders(including subquery and other builders) support setting parameters through the same setParameter() API that is offered by the JPA query API.
In addition to that, it is also possible to inspect the parameters and the bound values while building through getParameters().
List<Cat> query = cbf.create(em, Cat.class, "cat")
.where("name").eqExpression(":nameParam")
.setParameter("nameParam", "Billy")
.getResultList();
11.2. Count query
A CriteriaBuilder allows to render and create a count query variant via getCountQuery() which can be used to count the results of a query.
This count query is rather simple. Most of the time, it’s just the original query, except that it has just COUNT(*) in the SELECT clause and drops the ORDER BY clause.
If a GROUP BY clause is involved, the count query will count the number of distinct groups instead.
Invoking getCountQuery() on a PaginatedCriteriaBuilder will return the count query used for the paginated query which is based on it’s identifier expressions.
On top of that, CriteriaBuilder also offers a getQueryRootCountQuery() which will count the number of query roots similar to what the count query of a PaginatedCriteriaBuilder does.
The benefit of this count query is that it will omit joins that are only relevant for the SELECT and ORDER BY clauses.
CriteriaBuilder<Cat> criteriaBuilder = cbf.create(em, Cat.class, "cat")
.select("cat.id")
.select("kittens.id")
.where("name").eq("Billy");
When using getCountQuery(), this will count the result set size and produce the following JPQL
SELECT COUNT(*) FROM Cat cat LEFT JOIN cat.kittens WHERE cat.name = :param_0
When using getQueryRootCountQuery(), this will count the number of cats instead, which allows to omit joins and will produce the following JPQL
SELECT COUNT(*) FROM Cat cat WHERE cat.name = :param_0
Note that the use of the HAVING clause is currently unsupported when used with count queries. Also see #616
11.3. Query properties
As mentioned in the configuration chapter, a query builder can be further configured via the setProperty(String, String) method.
This allows for disabling optimizations when encountering bugs or fine tuning on a case by case basis.
If you encounter, that you make use of a configuration very often, you should consider configuring the property globally via the CriteriaBuilderConfiguration
and only switch to a different value when needed.
11.4. Query result caching
Query result caching can be enabled by invoking the setCacheable(boolean) method on a query builder.
Note that additional configuration might be required for the caching to work properly. For details, refer to the documentation of your JPA provider.
12. Pagination
Pagination is often used to make large data sets consumable. It requires an ordered set of elements/rows to be able to deterministically split the data into pages. Imagine the following ordered data set

If we split it up into pages of the size of 5 elements we get 6 pages and the last one only containing 1 element
Blaze Persistence provides two ways to do pagination.
-
Conventional pagination via
setFirstResult()andsetMaxResults() -
Extended pagination support via the
PaginatedCriteriaBuilderAPI
Conventional pagination in JPA only works on the main query which is also possible with Blaze Persistence.
List<Cat> secondCat = cbf.create(em, Cat.class)
.orderByAsc("id")
.setFirstResult(1)
.setMaxResults(1)
.getResultList();
SELECT cat FROM Cat cat ORDER BY cat.id ASC NULLS LAST --LIMIT 1 OFFSET 1
In addition to that, offset pagination for subqueries is also possible.
List<Cat> secondCat = cbf.create(em, Cat.class)
.fetch("kittens")
.where("id").in()
.from(Cat.class, "subCat")
.select("subCat.id")
.orderByAsc("id")
.setFirstResult(1)
.setMaxResults(1)
.end()
.getResultList();
SELECT cat
FROM Cat cat
LEFT JOIN FETCH cat.kittens kittens_1
WHERE cat.id IN LIMIT(( (1)
SELECT subCat.id
FROM Cat cat
ORDER BY cat.id ASC NULLS LAST
),1 ,1) --LIMIT 1 OFFSET 1
| 1 | Uses the LIMIT function to apply a LIMIT/OFFSET clause on the subquery |
The extended pagination support comes via the criteria builder’s page() methods which come in three flavours:
page(int firstResult, int maxResults)-
Performs offset pagination by skipping
firstResultelements and from there on, showmaxResultselements. page(KeysetPage keysetPage, int firstResult, int maxResults)-
Performs keyset pagination if possible and falls back to offset pagination otherwise.
pageAndNavigate(Object entityId, int maxResults)-
Navigates to the page containing the entity with the given
entityId. Falls back to the first page if no entity for the id exists.
12.1. Under the hood
In Blaze Persistence we have followed a more involved approach for implementing pagination than plainly using JPA standard
methods like javax.persistence.Query.setMaxResults() or javax.persistence.Query.setFirstResult() to steer the result set
dimensions. This is due to deficiencies in some JPA providers when it comes to handling paginated queries containing
join fetches for collections, but also to support custom pagination that is necessary for reporting queries or entity views.
| By default, when using fetch joins for collections with Hibernate, all results are fetched instead of only the selected page. |
The approach used in Blaze Persistence consists of up to three queries executed consecutively:
-
The count query is used to fetch the total element count which is needed to populate
com.blazebit.persistence.PagedList.getTotalSize()andcom.blazebit.persistence.PagedList.getTotalPages(). If this query returns 0, no further queries are executed. -
The ID query is used to fetch the entity ids that are contained in the target page. In this step, the previously mentioned
javax.persistence.Query.setMaxResults()andjavax.persistence.Query.setFirstResult()are used to select the target ID set. Only selecting the IDs allows to omit all fetch joins, especially collection joins that might trigger inefficient jpa provider strategies. The ID query is omitted if no collection fetch joins are done, because in that case JPA providers tend to do the right thing when paginating directly. -
Finally, the object query is used to fetch the entities as described by the original query specified by the user. This query uses an
INpredicate for the ID set retrieved in the previous step to restrict the fetched entities to the target page.
You can disable the count query by passing false to PaginatedCriteriaBuilder.withCountQuery(boolean).
By default, a required ID query is embedded into the object query as subquery if the JPA Provider and DBMS dialect supports that.
The inlining can be forced or disabled by passing true or false to PaginatedCriteriaBuilder.withInlineIdQuery(boolean) or globally by configuring the INLINE_ID_QUERY property.
By default, the count query is embedded into the ID query or object query as select item if the JPA Provider and DBMS dialect supports that.
The inlining can be forced or disabled by passing true or false to PaginatedCriteriaBuilder.withInlineCountQuery(boolean) or globally by configuring the INLINE_COUNT_QUERY property.
You can inspect the query strings by using getPageCountQueryString(),
getPageIdQueryString() and getQueryString()
|
12.2. Offset pagination
As already laid out in the introduction, pagination works on an ordered set of elements/rows.
Offset pagination basically looks at the ordered set from left to right and counts elements until the count reaches firstResult.
From that point on elements are collected until maxResults of elements have been collected or no more elements are available.
This basically means that the OFFSET i.e. firstResult part forces a DBMS to actually determine an element/row is visible for a transaction and then ignore/skip it.
The bigger the firstResult value, the more resources the DBMS has to waste for skipping elements/rows.
This essentially means that when employing offset pagination, accessing the latter pages will become more and more expensive.
In order for this approach to be actually usable with larger data sets, a DBMS index that can be used for the ordering is required to avoid constantly loading and sorting data.
In addition to that, the DBMS should have enough RAM to keep the index fully in-memory to avoid costly disk fetches.
Although offset pagination works in every case, it should be avoided if possible because of the performance implications. As you will see in the keyset pagination part there is a more efficient approach to pagination that almost uses the same API.
The following example illustrates the usage and what happens behind the scenes
PagedList<Cat> page2 = cbf.create(em, Cat.class)
.fetch("kittens")
.orderByAsc("id") // unique ordering is required for pagination
.page(5, 5)
.getResultList();
Executes the following queries
SELECT COUNT(*) FROM Cat cat
Note that the ID query is necessary because of the join fetched collection kittens
SELECT cat.id FROM Cat cat ORDER BY cat.id ASC NULLS LAST --LIMIT 1 OFFSET 1
SELECT cat FROM Cat cat LEFT JOIN FETCH cat.kittens kittens_1 WHERE cat.id IN :idParams ORDER BY cat.id ASC NULLS LAST
12.3. Keyset pagination
Keyset pagination is a way to efficiently paginate or scroll through a large data set by querying for elements that come before or after a reference point. The idea of a keyset is, that every tuple can be uniquely identified by that keyset. So a keyset essentially is a reference point of a tuple in a data set ordered by keysets. Keyset pagination in contrast to offset pagination makes efficient use of the ordering property of the data set. By remembering the highest and lowest keysets of a page, it is possible to query the previous and next pages efficiently.
A keyset in terms of query results consists of the values of the ORDER BY expressions of a tuple.
In order to satisfy the uniqueness constraint, it is generally a good idea to use an entity’s id as last expression in the ORDER BY clause.
| Currently entity ids are the only possible expressions that satisfies the uniqueness constraint. At some later point, unique expressions might be allowed as well. |
Keyset pagination just like offset pagination requires index support on the DBMS side to work efficiently. A range-scan enabled index like provided by a b-tree index is required for keyset pagination to work best.
In contrast to offset pagination, an index does not have to be traversed like a list in order to ignore/skip a certain amount of elements/rows. Instead, a DBMS can make use of the structure of the index
and traverse it in O(log N) as compared to O(N) to get to the firstResult. This characteristic makes keyset pagination especially useful for accessing latter pages.
| Don’t allow too many different sort combinations as every combination requires a custom index to work efficiently. |
One of the obvious requirements for keyset pagination to work, is the need for a reference point i.e. a keyset from which point on the next or previous elements should be queried.
The API in Blaze Persistence tries to allow making use of keyset pagination in a transparent and easy manner without compromises.
// In the beginning we don't have a keyset page
KeysetPage oldPage = null;
PagedList<Cat> page2 = cbf.create(em, Cat.class)
.orderByAsc("birthday")
.orderByAsc("id") // unique ordering is required for pagination
.page(oldPage, 5, 5) (1)
.getResultList();
// Query the next page with the keyset page of page2
PagedList<Cat> page3 = cbf.create(em, Cat.class)
.orderByAsc("birthday")
.orderByAsc("id") // unique ordering is required for pagination
.page(page2.getKeysetPage(), 10, 5) (2)
.getResultList();
// Query the previous page with the keyset page of page2
PagedList<Cat> page1 = cbf.create(em, Cat.class)
.orderByAsc("birthday")
.orderByAsc("id") // unique ordering is required for pagination
.page(page2.getKeysetPage(), 0, 5) (3)
.getResultList();
| 1 | The oldPage in this case is null, so internally it falls back to offset pagination |
| 2 | When querying the next page of page2, it can use the upper bound of the keyset page |
| 3 | When querying the previous page of page2, it can use the lower bound of the keyset page |
Since we are not fetching any collections, the ID query is avoided. For brevity, we skip the count query. So let’s look at the object queries generated
SELECT cat, cat.id (1) FROM Cat cat ORDER BY cat.birthday ASC NULLS LAST, cat.id ASC NULLS LAST --LIMIT 5 OFFSET 5
| 1 | The expression cat.id is for constructing the keyset and contains all expressions of the ORDER BY clause |
As you can see, nothing fancy, except for the additional select that is used for extracting the keyset.
SELECT cat, cat.id
FROM Cat cat
WHERE cat.birthday > :_keysetParameter_0 OR (
cat.birthday = :_keysetParameter_0 AND
cat.id > :_keysetParameter_1
)
ORDER BY cat.birthday ASC NULLS LAST, cat.id ASC NULLS LAST
--LIMIT 5
This time the query made efficient use of the keyset by filtering out elements/rows that come before the reference point
SELECT cat, cat.id
FROM Cat cat
WHERE cat.birthday < :_keysetParameter_0 OR (
cat.birthday = :_keysetParameter_0 AND
cat.id < :_keysetParameter_1
)
ORDER BY cat.birthday DESC NULLS FIRST, cat.id DESC NULLS FIRST
--LIMIT 5
Before the query filtered out elements/rows that came before the reference point, this time it does the opposite. It filters out elements/rows coming after the reference point. Another interesting thing to notice, the ordering was reversed too. This has the effect that the DBMS can traverse the index backwards and essentially is how keyset pagination works. The ordering is reversed again in-memory, so you don’t notice anything of these details.
Note that in the following situations, the implementation automatically falls back to offset pagination
-
The keyset is invalid i.e. it is
null -
The ordering of the query changed
-
The page to navigate to is arbitrary i.e. not the next or previous page of a
keysetPage
To be able to make use of keyset pagination either via the PaginatedCriteriaBuilder API or the manual keyset filter API,
the KeysetPage or the respective Keyset elements have to be preserved across page requests.
Applications that can retain state between requests(i.e. via a session) can just preserve the KeysetPage object itself. Applications that try to avoid server side state have to serialize and deserialize the state somehow.
Since the keyset state is available through getter methods, it shouldn’t be too hard to do the serialization and deserialization.
When implementing a custom Keyset, the equals() and hashCode() contracts have to make use of just the tuple. A custom KeysetPage implementation has to provide access to the lowest and highest keysets,
as well as the firstResult and maxResults values used for querying that page.
Beware that keyset pagination isn’t perfect. If entries can be prepended relative to the current keyset/reference point, it might happen that the page number calculation becomes wrong over time. Most of the time this is negligible as it kind of gives the illusion that the user works on a snapshot of the data.
12.4. Navigate to entity page
The navigation to the page on which an entity with a specific id is involves finding out the position of the entity.
Blaze Persistence offers a custom function named PAGE_POSITION which determines the absolute position of an entity in an ordered set.
Cat knownCat = //...
PagedList<Cat> page3 = cbf.create(em, Cat.class)
.orderByAsc("birthday")
.orderByAsc("id") // unique ordering is required for pagination
.pageAndNavigate(knownCat.getId(), 3)
.getResultList();
SELECT COUNT(*), PAGE_POSITION((
SELECT _page_position_cat.id
FROM Cat _page_position_cat
GROUP BY _page_position_cat.id, _page_position_cat.birthday
ORDER BY _page_position_cat.birthday DESC NULLS FIRST, _page_position_cat.id DESC NULLS FIRST
), :_entityPagePositionParameter)
FROM Cat cat
The count query contains the page position determination logic. It essentially passes an ID query as subquery to the PAGE_POSITION function.
The concrete SQL implementation of that function depends on the DBMS, but they all follow the same main idea.
Wrap the ID query and count the row numbers. In another wrapper around that, filter for the row with the matching id and return the row number as position.
The element/row number of the first element on that page is calculated and used as firstResult. Apart from this speciality, the rest of the query is just like a normal offset pagination query.
12.5. Custom identifier expressions
By default, a query will be paginated by the query root’s id or group by keys, but that might not always be desirable.
If the query should rather be paginated based on the identifier of a uniqueness preserving association or unique key rather than primary key or group by keys,
the pageBy() variants that accept identifier expressions can be used.
PagedList<Cat> page = cbf.create(em, Cat.class)
.orderByAsc("birthday")
.orderByAsc("someOneToOne.id")
.pageBy(0, 1, "someOneToOne.id")
.getResultList();
This will paginate based on the identifier of the one-to-one association instead, which is considered uniqueness preserving.
12.6. Paginate aggregate queries
Apart from paginating object graphs it is also possible to paginate aggregate results via this API.
The use of groupBy() or an aggregate function will make it necessary to render a GROUP BY clause.
It doesn’t matter if grouping is done explicitly or implicitly, pagination will always be done based on the GROUP BY clause if available, unless a custom identifier expression is specified.
This means that the count query, will count the number distinct groups. The id query will select the distinct groups and the object query will finally do the aggregation based on a filter on the groups.
PagedList<Cat> page = cbf.create(em, Cat.class)
.select("cat.name")
.select("SUM(kittens.age)")
.orderByAsc("name")
.page(0, 1)
.getResultList();
Note that we didn’t specify a groupBy("c.name") because it can be implicitly determined.
Also note that using just the name in the orderByAsc is not a violation of the uniqueness properties.
This is because through implicit group by collection, we know that name is going to be part of the GROUP BY clause
and when a tuple of expressions is contained in the group by, it is considered unique.
SELECT COUNT(DISTINCT cat.name) FROM Cat cat
Since we don’t fetch collections, there is no need for an id query.
SELECT cat.name, SUM(kittens_1.age) FROM Cat cat LEFT JOIN cat.kittens kittens_1 GROUP BY cat.name ORDER BY cat.name --LIMIT 1
12.7. Extracting page id query
There are certain cases when the PaginatedCriteriaBuilder API is not a perfect fit.
It might be desirable to reuse the ids of a page in multiple contexts or in a subquery or CTE.
Blaze Persistence provides some createPageIdQuery() method variants for this purpose that are analogous to the various pageBy method variants.
The method creates a new CriteriaBuilder that represents the id query that would normally be executed when using the PaginatedCriteriaBuilder API.
Imagine you take an existing query
CriteriaBuilder<Cat> baseBuilder = cbf.create(em, Cat.class)
.select("cat.name")
.select("kittens.name")
.orderByAsc("name")
.orderByAsc("id");
and turn that into an id query
CriteriaBuilder<Cat> idBuilder = baseBuilder.createPageIdQuery(0, 10, "id");
executing this query would produce the expected id query
SELECT cat.id FROM Cat cat --LIMIT 10
and when embedding this query into e.g. a subquery like
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.select("cat.name")
.select("kittens.name")
.orderByAsc("name")
.orderByAsc("id")
.where("id").in(idBuilder);
this will execute like
SELECT cat.name, kittens_1.name
FROM Cat cat
LEFT JOIN cat.kittens kittens_1
WHERE cat.id IN (LIMIT(
SELECT cat.id
FROM Cat cat
),10)--LIMIT 10
ORDER BY cat.name, cat.id
12.8. Bounded counting
Oftentimes it is not necessary to determine an exact row count so it would be better to determine the count up to a certain threshold.
Blaze Persistence supports bounded counting in the PaginatedCriteriaBuilder API through the
withBoundedCount(long maximumCount) method
which will count up to the given value, but not further. This improves performance drastically for large data sets because the database
has to do less work. A query like the following
PagedList<Cat> page = cbf.create(em, Cat.class)
.fetch("kittens")
.orderByAsc("id") // unique ordering is required for pagination
.page(0, 5)
.getResultList();
will execute a count query that looks similar to this
SELECT
COUNT_WRAPPER((
SELECT 1
FROM Cat cat
LIMIT 10
))
FROM Long(1 VALUES) dual_
which results in SQL simialar to this
SELECT
(SELECT COUNT(*) FROM (
SELECT 1
FROM Cat cat
LIMIT 10
) tmp)
FROM VALUES(1) v
12.9. Limitations
Since the PaginatedCriteriaBuilder API pagination produces inherently distinct results the use of distinct() on a PaginatedCriteriaBuilder is disallowed and will result in an exception.
Also note that there is currently no support for the HAVING clause along with a PaginatedCriteriaBuilder. Also see #616
If these limitations are not ok for your use case, you will have to implement a custom pagination strategy via setFirstResult() and setMaxResults().
13. DML statements
Next to the support for SELECT statements, Blaze Persistence also has support for
-
UPDATE -
DELETE -
INSERT ... SELECT
Apart from support for DML for JPA entity types, there is also support for DML for entity collections.
The construction of query builders for such statements works through the CriteriaBuilderFactory API.
Apart from supporting DML queries for entity collections, the biggest feature provided by Blaze Persistence is the support for joins!
When joins are involved through explicit join calls or implicit joins, Blaze Persistence will make use of the DBMS native mechanism to implement join support.
13.1. DELETE statement
The DELETE statement deletes entities that satisfy the WHERE clause of the statement.
A delete builder can be created via CriteriaBuilderFactory.delete().
DeleteCriteriaBuilder<Cat> cb = cbf.delete(em, Cat.class, "cat")
.where("cat.name").isNull();
DELETE FROM Cat cat WHERE cat.name IS NULL
You can immediately execute the query by calling executeUpdate()
or create a JPA Query by calling getQuery().
Delete builders can have joins as well as implicit joins that are translated to a join mechanism the underlying DBMS supports.
Currently you can’t make use of advanced SQL features like CTEs when having a polymorphic DELETE except for single table inheritance. Also see #345
|
| If your DBMS supports it, cascading deletes will be implemented as CTEs when deleting entities through this API. |
13.2. DELETE collection statement
The DELETE collection statement deletes collection entries of entities that satisfy the WHERE clause of the statement.
A collection delete builder can be created via CriteriaBuilderFactory.deleteCollection().
The statement only works on collections that have a join or collection table.
DeleteCriteriaBuilder<Cat> cb = cbf.deleteCollection(em, Cat.class, "cat", "kittens")
.whereExists()
.from(Cat.class, "subCat")
.where("cat.id").eqExpression("subCat.id")
.where("subCat.name").isNull()
.end();
The alias cat, or in general a delete collection statement alias, only allows access to the join or collection table related attributes.
Generally, these attributes are
-
The source id i.e.
cat.id -
The target id i.e.
cat.kittens.idor target embeddable attributes -
The collection index/key i.e.
KEY(cat.kittens)
DELETE FROM Cat(kittens) cat
WHERE EXISTS(
SELECT 1 FROM Cat subCat
WHERE cat.id = subCat.id
AND cat.name IS NULL
)
You can immediately execute the query by calling executeUpdate()
or create a JPA Query by calling getQuery().
13.3. UPDATE statement
The UPDATE statement updates attributes as specified in the SET clause on entities that satisfy the WHERE clause of the statement.
An update builder can be created via CriteriaBuilderFactory.update().
UpdateCriteriaBuilder<Cat> cb = cbf.update(em, Cat.class, "cat")
.set("name")
.from(Person.class, "p")
.where("p").eqExpression("cat.owner")
.select("CONCAT(p.name, '''s cat')")
.end()
.where("name").isNull();
UPDATE Cat cat
SET cat.name = (
SELECT CONCAT(p.name, '''s cat')
FROM Person p
WHERE p = cat.owner
)
WHERE cat.name IS NULL
There are multiple set() variants to be able to cover all possible expressions.
set(String, Object)-
Set the attribute to the given value. This will create an implicit parameter expression and set the value.
UpdateCriteriaBuilder<Cat> cb = cbf.update(em, Cat.class, "cat")
.set("name", "Billy2")
.where("name").eq("Billy");
UPDATE Cat cat SET cat.name = :param_1 WHERE cat.name = :param_2
set(String)-
Starts a subquery builder for the attribute.
UpdateCriteriaBuilder<Cat> cb = cbf.update(em, Cat.class, "cat")
.set("name")
.from(Person.class, "p")
.where("p").eqExpression("cat.owner")
.select("CONCAT(p.name, '''s cat')")
.end()
.where("cat.name").eq("Billy");
UPDATE Cat cat
SET cat.name = (
SELECT CONCAT(p.name, '''s cat')
FROM Person p
WHERE p = cat.owner
)
WHERE cat.name = :param_1
setExpression(String, String)-
Uses the given expression for the assignment to the attribute.
UpdateCriteriaBuilder<Cat> cb = cbf.update(em, Cat.class, "cat")
.setExpression("name", "UPPER(name)")
.where("cat.name").eq("Billy");
UPDATE Cat cat SET cat.name = UPPER(cat.name) WHERE cat.name = :param_1
setSubqueries(String, String)-
Starts a subquery builder capable of handling multiple subqueries and assigns the given
expressionto the attribute. Subqueries are started withwith(String subqueryAlias)and aliases occurring in the expression will be replaced by the respective subquery expressions.
UpdateCriteriaBuilder<Cat> cb = cbf.update(em, Cat.class, "cat")
.setSubqueries("name", "CONCAT(ownerSubquery, ' the cat'")
.with("ownerSubquery")
.from(Person.class, "p")
.where("p").eqExpression("cat.owner")
.select("p.name")
.end()
.end()
.where("cat.name").eq("Billy");
UPDATE Cat cat
SET cat.name = CONCAT((
SELECT p.name
FROM Person p
WHERE p = cat.owner
), '''s cat')
WHERE cat.name = :param_1
Currently there is no possibility to do a VERSIONED update like you could do with e.g. Hibernate.
|
You can immediately execute the query by calling executeUpdate()
or create a JPA Query by calling getQuery().
Update builders can have joins as well as implicit joins that are translated to a join mechanism the underlying DBMS supports.
Currently you can’t make use of advanced SQL features like CTEs when having a polymorphic UPDATE except for single table inheritance. Also see #345
|
13.4. UPDATE collection statement
The UPDATE collection statement updates attributes as specified in the SET clause on entries of a collection of entities that satisfy the WHERE clause of the statement.
A collection update builder can be created via CriteriaBuilderFactory.updateCollection().
The statement only works on collections that have a join or collection table.
UpdateCriteriaBuilder<Cat> cb = cbf.updateCollection(em, Cat.class, "cat", "kittens")
.set("id", 2)
.where("cat.id").eq(1);
You can only set attributes of the join or collection table, which generally are
-
The source id i.e.
id -
The target id i.e.
kittens.idor target embeddable attributes -
The collection index/key i.e.
KEY(kittens)
The logical SQL for this re-parenting query looks like
UPDATE Cat(kittens) cat SET cat.id = :param_1 WHERE cat.id = :param_2
This will cause all kittens that previously were associated with the cat with id 1 now to be the kittens of the cat with id 2.
13.5. INSERT-SELECT statement
The INSERT-SELECT statement allows to create new entities based on result of a SELECT query.
An insert builder can be created via CriteriaBuilderFactory.insert().
| This feature is currently only supported with Hibernate! |
Let’s consider a simple entity class for INSERT statement examples
@Entity
public class Pet {
@Id
@GeneratedValue
private Long id;
@ManyToOne(optional = false)
private Cat cat;
}
InsertCriteriaBuilder<Cat> cb = cbf.insert(em, Pet.class)
.from(Cat.class, "c")
.bind("cat").select("c")
.where("owner").isNotNull();
INSERT INTO Pet(cat) SELECT c FROM Cat c WHERE c.owner IS NOT NULL
The bind() method allows to bind any select expression to an attribute of the Pet entity.
You can also bind values directly with bind(String, Object) if you want.
Hibernate 4.2 does not support parameters in the SELECT clause, so you will have to render values as literals instead.
|
As you can see, we didn’t specify the id attribute. This is because it’s value is going to be generated by the database.
| When using Hibernate with embedded ids, you must map all the columns as basic values(no relations) directly into the entity itself, otherwise you won’t be able to assign a value to the attributes/columns. |
| When using Oracle, generated identifiers currently don’t work. Also see #306 |
13.6. INSERT-SELECT collection statement
The INSERT-SELECT collection statement inserts new collection entries.
A collection insert builder can be created via CriteriaBuilderFactory.insertCollection().
The statement only works on collections that have a join or collection table.
InsertCriteriaBuilder<Cat> cb = cbf.insertCollection(em, Cat.class, "kittens")
.from(Cat.class, "c")
.bind("id", 2)
.bind("kittens.id").select("c.kittens.id")
.where("c.id").eq(1);
You can only bind attributes of the join or collection table, which generally are
-
The source id i.e.
id -
The target id i.e.
kittens.idor target embeddable attributes -
The collection index/key i.e.
KEY(kittens)
The logical SQL for this kittens copying query looks like
INSERT INTO Cat.kittens(id, kittens.id) SELECT :param_1, kittens_1.id FROM Cat c LEFT JOIN c.kittens kittens_1 WHERE c.id = :param_2
This will copy all kittens that are associated with the cat with id 1 to the kittens of the cat with id 2.
13.7. CTE support
If the underlying DBMS does not support the use of CTEs on modification statements, the CTE’s are inlined into the query.
You can make use of those by defining them via with().
For further information on this, check out the CTE chapter.
13.8. RETURNING clause support
The RETURNING clause allows to return values to the client based on the modified entities of a DML statement.
Every DML statement can return any attributes of the entities that the statement modified.
All query builders for DML statements provide getWithReturningQuery() variants
for creating a JPA TypedQuery from specifiable attributes which should be returned for modified entities.
The TypedQuery instance always returns a single ReturningResult. Calling getResultList() will just wrap the result of getSingleResult() in a list.
Although the builder returns a TypedQuery which normally doesn’t require a transaction, you have to execute such a query within an active transaction since it actually modifies entities.
|
For every getWithReturningQuery() variant, there exists a executeWithReturning() variant that can be used as a short hand for getWithReturningQuery().getSingleResult().
|
A ReturningResult basically gives you access to the update count via getUpdateCount()
and a result list, representing the attributes of modified entities that were requested to be returned, via getResultList().
In addition to that, it also offers access to the last returned result via getLastResult(), but this might get removed in the future.
| As you will see in the next chapter, on some DBMS you can even pipe data returned by DML into other queries. |
The following examples will show how the different executeWithReturning() variants can be used.
13.8.1. RETURNING from DELETE statement
Let’s see how we can retrieve the names of cats that have been deleted.
DeleteCriteriaBuilder<Cat> cb = cbf.delete(em, Cat.class, "cat")
.where("cat.name").like().value("Billy%").noEscape();
ReturningResult<String> result = cb.executeWithReturning("name", String.class);
List<String> names = result.getResultList();
Make sure your DBMS supports returning non-generated columns in the DBMS compatibility matrix.
DELETE FROM Cat cat WHERE cat.name LIKE :param_1 RETURNING name
13.8.2. RETURNING from UPDATE statement
UpdateCriteriaBuilder<Cat> cb = cbf.update(em, Cat.class, "cat")
.setExpression("cat.name", "UPPER(cat.name)")
.where("cat.name").like().value("Billy%").noEscape();
ReturningResult<Tuple> result = cb.executeWithReturning("id", "name");
List<Tuple> updatedCatIdAndNames = result.getResultList();
Also make sure your DBMS supports returning multiple modified rows in the DBMS compatibility matrix.
UPDATE Cat cat SET cat.name = UPPER(cat.name) WHERE cat.name LIKE :param_1 RETURNING id, name
13.8.3. RETURNING from INSERT-SELECT statement
InsertCriteriaBuilder<Cat> cb = cbf.insert(em, Pet.class)
.from(Cat.class, "c")
.bind("cat").select("c")
.where("owner").isNotNull();
ReturningResult<Pet> result = cb.executeWithReturning(new ReturningObjectBuilder<Pet>() {
@Override
public <X extends ReturningBuilder<X>> void applyReturning(X returningBuilder) {
returningBuilder.returning("id");
}
@Override
public Pet build(Object[] tuple) {
return new Pet((Long) tuple[0]);
}
@Override
public List<T> buildList(List<T> list) {
return list;
}
});
List<Pet> createdPetIds = result.getResultList();
Although not very useful, this will return pet objects with the ids of the inserted pet entities set.
INSERT INTO Pet(cat) SELECT c FROM Cat c WHERE c.owner IS NOT NULL RETURNING id
13.9. DBMS compatibility
Although it might be possible to retrieve other columns based on identifiers for DBMS that don’t support RETURNING all columns natively, there is no emulation implemented yet.
| DBMS | RETURNING generated | RETURNING multiple rows | RETURNING all |
|---|---|---|---|
PostgreSQL |
yes |
yes |
yes |
MySQL |
yes |
no |
no |
H2 |
yes |
no |
no |
Oracle |
yes |
yes |
yes |
SQL Server |
yes |
yes |
yes |
DB2 |
yes |
yes |
yes |
14. CTEs
CTEs provide a way to introduce statements into a larger query that can be reused. CTEs are like temporary entity sets/tables that are created for the scope of the query and then deleted.
A CTE normally contains a SELECT statement, but depending on the DBMS support, can also contain INSERT, UPDATE and DELETE statements.
| This feature is currently only supported with Hibernate! |
Before you can define a query for a CTE, the structure of the it has to be defined in a similar manner as an entity is defined. Don’t forget to also add it to your persistence.xml so that the JPA provider can discover it.
@CTE // from com.blazebit.persistence
@Entity // from javax.persistence
public class MyCte {
private Long id;
@Id // from javax.persistence
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
}
The difference to a normal entity is that in addition to that, the CTE annotation is applied which treats it like a view i.e. no DDL is generated for it.
A CTE can be defined on a top level query builder by using with(Class<?>)
or with(Class<?>, CriteriaBuilder<?> cb).
The created CTE builder has to be finished by calling end() on it.
All attributes of a CTE must be bound to expressions with bind() like in the following.
CriteriaBuilder<MyCte> cb = cbf.create(em, MyCte.class)
.with(MyCte.class)
.from(Cat.class, "cat")
.bind("id").select("cat.id")
.end();
| Since you can map columns multiple times in the CTE entity, it is sufficient to make sure that all columns have values bound through attribute bindings. If a column is left out, you will get an exception. |
As you can see from the example, the API tries to look as much as possible like the CTE syntax as defined in the SQL-99 standard.
As for all advanced features, the query string returned by getQueryString() only represents the logical structure of the whole query in a syntax that might be used one day by JPA providers to support this feature natively.
WITH MyCte(id) AS(
SELECT cat.id FROM Cat cat
)
SELECT myCte FROM MyCte myCte
14.1. Implementation notes
Currently the CTE support is only implemented for Hibernate because of the deep integration that is needed for it to work.
The integration with the persistence provider happens in the implementation of com.blazebit.persistence.spi.ExtendedQuerySupport
which tries to focus on the minimal necessary methods needed for the integration to work.
In case of Hibernate, a CTE entity class is treated as if org.hibernate.annotations.Subselect was annotated.
Hibernate generally generates from clause elements of the form ( select * from MyCTE ) for Subselect entities which we replace simply by the name of the CTE.
The current implementation extracts the SQL from various template JPQL queries that are created behind the scenes. After applying different transformations on the SQL and merging it together to a single SQL query, the new SQL replaces is used in a special JPQL query object. The special JPQL query object is what you can finally execute. It will make use of the SQL query that was created before.
Every CTE will result in a separate JPQL query behind the scenes from which the SQL is extracted. The SQL from the main query, together with the SQLs from the CTEs are put together to form the full SQL query. It is that SQL, the special JPQL query receives for later execution.
In order to support the org.hibernate.FetchMode.SUBSELECT this library ships with custom implementations of org.hibernate.persister.collection.CollectionPersister.
Custom persister implementations should be made aware of CTEs in a similar fashion to be able to make use of the fetch mode.
|
14.2. Recursive CTEs
CTEs not only provide a way to extract subqueries or use subqueries in the FROM clause, but also to implement recursive queries.
A recursive CTE is normally composed of two parts, a base query(non-recursive query) and a recursive query connected with the SET operator UNION or UNION ALL.
The recursive part is allowed to refer to the CTE itself.
A recursive CTE is normally evaluated in iterations
-
The base query is evaluated and the result put into a temporary work set/table
-
The recursive query operates on the work set/table data and replaces it with the newly produced data
-
When the recursive query didn’t produce data, the recursion and thus the query is finished
The following illustrates how the ancestor hierarchy of an entity can be retrieved.
@CTE // from com.blazebit.persistence
@Entity // from javax.persistence
public class CatCte {
private Long id;
private Cat ancestor;
@Id // from javax.persistence
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
@ManyToOne
public Cat getAncestor() { return ancestor; }
public void setAncestor(Cat ancestor) { this.ancestor = ancestor; }
}
CriteriaBuilder<CatCte> cb = cbf.create(em, CatCte.class)
.withRecursive(CatCte.class)
.from(Cat.class, "cat") (1)
.bind("id").select("cat.id")
.bind("ancestor").select("cat.ancestor")
.where("id").eq(someCatId)
.unionAll()
.from(Cat.class, "cat")
.from(CatCte.class, "parentCat") (2)
.bind("id").select("cat.id")
.bind("ancestor").select("cat.ancestor")
.where("id").eqExpression("parentCat.ancestor.id") (3)
.end();
| 1 | We start with the non-recursive query and just bind the cat attributes of the desired cat |
| 2 | We refer to the CTE itself in the recursive query to be able to join data with data of the previous iteration |
| 3 | Only join the cats that are an ancestor of the cats from the previous iteration |
WITH RECURSIVE CatCte(id, ancestor) AS(
SELECT cat.id, cat.ancestor FROM Cat cat WHERE cat.id = :someCatId
UNION ALL
SELECT cat.id, cat.ancestor FROM Cat cat, CatCte parentCat WHERE cat.id = parentCat.ancestor.id
)
SELECT catCte FROM CatCte catCte
This will return all the ancestors of the Cat with an id equal to someCatId.
14.3. Updatable CTEs
An updatable CTE is like a normal CTE, but the data comes from returned attributes of a DML statement.
| At this point, only PostgreSQL and DB2 support this feature. |
You can start an updatable CTE with the withReturning() method and subsequently decide the DML statement type.
The query builder for the DML statement provides a returning() method for binding attributes of the DML statement to a CTE attribute.
CriteriaBuilder<MyCte> cb = cbf.create(em, MyCte.class)
.withReturning(MyCte.class)
.delete(Cat.class, "cat")
.where("cat.name").isNull()
.returning("id", "cat.id")
.end();
WITH MyCte(id) AS(
DELETE FROM Cat cat
WHERE cat.name IS NULL
RETURNING id
)
SELECT myCte FROM MyCte myCte
The query deletes cats with a NULL name. For every deleted cat, a temporary MyCte entity with the cat’s id bound is created. Finally the deleted cats are queried through MyCte.
As you can imagine, this can be used to define very efficient data pipelines.
One problem with updatable CTEs that might come up is, that you might want to query an entity in one CTE, while also wanting to do a modification in a different CTE. Since the visibility of changes that are done in updatable CTEs might differ from one to another DBMS, Blaze Persistence offers a way to resolve this special case.
Let’s consider the following example:
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.withReturning(MyCte.class)
.delete(Cat.class, "cat")
.where("cat.name").isNull()
.returning("id", "cat.id")
.end()
.from(Cat.class, "theCat");
WITH MyCte(id) AS(
DELETE FROM Cat cat
WHERE cat.name IS NULL
RETURNING id
)
SELECT theCat FROM Cat theCat
Although the CTE MyCte is never used, it is still executed. Depending on the DBMS you are on, the SELECT statement will return the state before or after the DELETE statement happened.
| Multiple updatable CTEs for the same entity in a single query are not supported. |
In order to make the SELECT statement portable, Blaze Persistence provides a way to qualify a FROM clause element to use the old or new state i.e. before or after modifications happened.
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class)
.withReturning(MyCte.class)
.delete(Cat.class, "cat")
.where("cat.name").isNull()
.returning("id", "cat.id")
.end()
.fromOld(Cat.class, "theCat");
WITH MyCte(id) AS(
DELETE FROM Cat cat
WHERE cat.name IS NULL
RETURNING id
)
SELECT theCat FROM OLD(Cat) theCat
The fromOld() method qualifies the FROM element in the query as old.
In the same way does fromNew() qualify the FROM element as new.
In general, we advise you to rethink how you do the querying when having a need for this feature. It should only be used as a last resort.
14.4. DBMS compatibility
If a DBMS does not support CTEs natively, the queries are inlined as subqueries in the FROM clause. Note that recursive CTEs can’t be emulated. CTEs are well tested with PostgreSQL, DB2, Oracle and Microsoft SQL Server. Many of the basic features work with H2, but beware that H2 support for CTEs is still experimental.
We do not recommend using non-inlined CTEs with H2 because of some very serious limitations. Using a non-inlined CTE in an IN predicate or using LIMIT within the non-inlined CTE have proven to produce wrong results. You also can’t have multiple non-inlined CTEs per query.
|
| DB2 does not support JOINs in the recursive part of a CTE: https://www.ibm.com/support/knowledgecenter/SSEPEK_10.0.0/com.ibm.db2z10.doc.codes/src/tpc/n345.dita |
CTEs in DML are uses of a CTE where the top level statement is a DML. In contrast, Updatable CTEs are CTEs that contain DML and get their values from a RETURNING clause of the DML.
| DBMS | Normal CTEs | Recursive CTEs | CTEs in DML | Updatable CTEs |
|---|---|---|---|---|
PostgreSQL |
yes |
yes |
yes |
yes |
MySQL |
yes(inlined) |
no |
yes(inlined) |
no |
MySQL 8+ |
yes |
yes |
yes(inlined) |
no |
H2 |
yes/partly |
partly |
yes(inlined) |
no |
Oracle |
yes |
partly |
yes |
no |
SQL Server |
yes |
yes |
yes |
no |
DB2 |
yes |
yes |
yes |
yes |
15. Set operations
A set operation connects result lists of queries. The most well-known set operations are UNION and UNION ALL which merge the result lists of two queries.
Apart from that, there is an operation that produces the commonalities of two result lists i.e. the intersection and an operation that subtracts commonalities i.e. minus/except.
All operations require that the connected queries must have the same number of select items with the same data types.
| This feature is currently only supported with Hibernate! |
The SQL standard defines the following set operations for connecting two queries query1 and query2 which is also what Blaze Persistence adopts
-
UNION- Merges results from query1 and query2 but filters out duplicates. -
UNION ALL- Merges results from query1 and query2 without filtering duplicates. -
INTERSECT- Creates a result based on distinct elements that appear in both query1 and query2 -
INTERSECT ALL- Creates a result based on all elements that appear in both query1 and query2 i.e. not filtering out duplicates -
EXCEPT- Creates a result based on distinct elements of query1 that don’t appear in query2 -
EXCEPT ALL- Creates a result based on all elements of query1 that don’t appear in query2
These set operations are not only useful for scalar queries, but can also be used when querying for entities.
| There are some limitations to using set operations with polymorphic queries. |
15.1. Normal set operations
A set operation ends the source query builder and starts a new query builder. This new builder then has to be explicitly ended.
FinalSetOperationCriteriaBuilder<Cat> cb = (1)
cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.where("name").eq("Billy")
.unionAll() (2)
.from(Cat.class, "cat")
.where("name").eq("Johnny")
.endSet(); (3)
| 1 | The query builder has a different type, since it represents the builder for the set operation query |
| 2 | Use any set operation here |
| 3 | You must end the set operation explicitly |
The call to unionAll() ends the previous query builder making any operations on it fail with an exception.
Finally endSet() ends the last query builder.
SELECT cat FROM Cat cat WHERE cat.name = :param_1 UNION ALL SELECT cat FROM Cat cat WHERE cat.name = :param_2
You can chain as many queries with set operations with the following methods
-
union()-query1 UNION query2 -
unionAll()-query1 UNION ALL query2 -
intersect()-query1 INTERSECT query2 -
intersectAll()-query1 INTERSECT ALL query2 -
except()-query1 EXCEPT query2 -
exceptAll()-query1 EXCEPT ALL query2
All operations have the same precedence i.e. they are executed from left to right. The only way to order the operations is by grouping them with parenthesis as shown in the next chapter.
You can also make use of set operations in CTEs like the following example shows.
@CTE // from com.blazebit.persistence
@Entity // from javax.persistence
public class MyCte {
private Long id;
@Id // from javax.persistence
public Long getId() { return id; }
public void setId(Long id) { this.id = id; }
}
CriteriaBuilder<Cat> cb =
cbf.create(em, Cat.class)
.with(MyCte.class)
.from(Cat.class, "cat1")
.bind("id").select("cat1.id")
.where("name").eq("Billy")
.unionAll()
.from(Cat.class, "cat2")
.bind("id").select("cat2.id")
.where("name").eq("Johnny")
.unionAll()
.from(Cat.class, "cat3")
.bind("id").select("cat3.id")
.where("name").eq("Franky")
.endSet() (1)
.end()
.from(Cat.class, "cat")
.where("id").in()
.from(MyCte.class, "myCte")
.select("myCte.id")
.end();
| 1 | The result of endSet() allows to apply sorting and limiting |
The API is the same, and produces the expected query.
WITH MyCte(id) AS (
SELECT cat1.id FROM Cat cat1 WHERE cat1.name = :param_1
UNION ALL
SELECT cat2.id FROM Cat cat2 WHERE cat2.name = :param_2
UNION ALL
SELECT cat3.id FROM Cat cat3 WHERE cat3.name = :param_3
)
SELECT cat FROM Cat cat WHERE cat.id IN (
SELECT myCte.id FROM MyCte myCte
)
Finally, there is also support for set operations within subqueries.
CriteriaBuilder<Cat> cb =
cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.where("id").in()
.from(Cat.class, "cat1")
.select("cat1.id")
.where("name").eq("Billy")
.unionAll()
.from(Cat.class, "cat2")
.select("cat2.id")
.where("name").eq("Johnny")
.unionAll()
.from(Cat.class, "cat3")
.select("cat3.id")
.where("name").eq("Franky")
.endSet()
.end();
SELECT cat FROM Cat cat WHERE cat.id IN (
SET_UNION_ALL(
(SELECT cat1.id FROM Cat cat1 WHERE cat1.name = :param_1),
(SELECT cat2.id FROM Cat cat2 WHERE cat2.name = :param_2),
(SELECT cat3.id FROM Cat cat3 WHERE cat3.name = :param_3)
)
)
As you can see, this is rendered differently. It makes use of custom JPQL functions that could even be directly executed by the JPA provider. This is possible because Blaze Persistence registers the JPQL functions for the entire persistence unit. These functions produce the necessary SQL in-place which is more efficient than a complete SQL replacement. The following set operation functions are registered by default:
15.2. Right nested set operations
In order to support grouping of set operations, Blaze Persistence has a special API for grouping the left and right hand sides of set operations.
Normally in SQL, the grouping can be achieved by using parenthesis which you can see in the logical query. Unfortunately it is not so easy to provide support
for such a grouping in a builder API which is why there are special methods for starting and connecting such a group with set operations.
Applying a set operation on such a parenthesis is possible with one of the startXXX() methods:
-
startUnion()-query1 UNION (...) -
startUnionAll()-query1 UNION ALL (...) -
startIntersect()-query1 INTERSECT (...) -
startIntersectAll()-query1 INTERSECT ALL (...) -
startExcept()-query1 EXCEPT (...) -
startExceptAll()-query1 EXCEPT ALL (...)
FinalSetOperationCriteriaBuilder<Cat> cb =
cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.where("name").eq("Billy")
.startUnionAll()
.from(Cat.class, "cat")
.where("name").eq("Johnny")
.union()
.from(Cat.class, "cat")
.where("name").eq("Franky")
.endSet() (1)
.endSet(); (2)
| 1 | Ends the nested set operation group started by startUnionAll() |
| 2 | The second endSet() might feel weird, but is actually necessary to end the implicitly started set operation on the main query |
You can imagine any startXXX() being the opening parenthesis that must be ended with a endSet() representing the closing parenthesis.
Since you could apply other set operations on that group, you are required to signal that you are done with the builder by calling endSet().
SELECT cat FROM Cat cat WHERE cat.name = :param_1
UNION ALL
(
SELECT cat FROM Cat cat WHERE cat.name = :param_2
UNION
SELECT cat FROM Cat cat WHERE cat.name = :param_3
)
15.3. Left nested set operations
Similarly you can also have a left nested group for set operations.
FinalSetOperationCriteriaBuilder<Cat> cb =
cbf.startSet(em, Cat.class) (1)
.from(Cat.class, "cat")
.where("name").eq("Billy")
.unionAll()
.from(Cat.class, "cat")
.where("name").eq("Johnny")
.endSet()
.union()
.from(Cat.class, "cat")
.where("name").eq("Franky")
.endSet();
(
SELECT cat FROM Cat cat WHERE cat.name = :param_1
UNION ALL
SELECT cat FROM Cat cat WHERE cat.name = :param_2
)
UNION
SELECT cat FROM Cat cat WHERE cat.name = :param_3
The left nesting is started by startSet() which
more or less represents the open parenthesis. The parenthesis is then closed by calling endSet().
At the beginning of every nesting group, you can start as many left nestings as you want by calling startSet()
and doing so intuitively always results in an open parenthesis that has to be closed by a endSet().
15.4. Empty nested set operations
As a convenience, Blaze Persistence allows to have empty nested set operation groups like the following.
FinalSetOperationCriteriaBuilder<Cat> cb =
cbf.startSet(em, Cat.class)
.endSet()
.union()
.from(Cat.class, "cat")
.where("name").eq("Franky")
.endSet();
Contrary to what you might think, this is allowed and results in the following query.
SELECT cat FROM Cat cat WHERE cat.name = :param_1
This is done to make it possible to pass the result of startSet() to consumers which may or may not add set operands.
15.5. Ordering and limiting with set operations
Since set operations might change the order of elements in the overall result, they also allow to define an ORDER BY clause for the result of a set operation group.
The order by elements are resolved against the first set operand. This means that you can only order by select aliases of the first query in the set operation. If the order by element does not refer to a select alias, it is implicitly resolved against the query root like in the following example.
FinalSetOperationCriteriaBuilder<Cat> cb =
cbf.create(em, Cat.class)
.from(Cat.class, "cat")
.where("name").eq("Billy")
.unionAll()
.from(Cat.class, "cat")
.where("name").eq("Johnny")
.endSet()
.orderByAsc("name")
.setFirstResult(1)
.setMaxResults(1);
SELECT cat FROM Cat cat WHERE cat.name = :param_1 UNION ALL SELECT cat FROM Cat cat WHERE cat.name = :param_2 ORDER BY name ASC NULLS LAST LIMIT 1 OFFSET 1
Apart from the ordering by name, this query will also skip the first element and limit the elements to be returned to one.
Note that LIMIT and OFFSET operate on the scalar results and not on entity elements. A collection joins might result in multiple elements per entity.
|
Ordering and limiting is also possible for nested set operation groups and can be realized by invoking the endSetWith() operation.
Calling endSetWith() is necessary to end the current query builder i.e. switch the context to the whole set operation group.
After applying ordering and limiting the set operation group has to be closed with endSet().
FinalSetOperationCriteriaBuilder<Cat> cb =
cbf.startSet(em, Cat.class) (1)
.from(Cat.class, "cat")
.where("name").eq("Billy")
.unionAll()
.from(Cat.class, "cat")
.where("name").eq("Johnny")
.endSetWith()
.orderByAsc("name")
.setMaxResults(1)
.endSet()
.union()
.from(Cat.class, "cat")
.where("name").eq("Franky")
.endSet();
(
SELECT cat FROM Cat cat WHERE cat.name = :param_1
UNION ALL
SELECT cat FROM Cat cat WHERE cat.name = :param_2
ORDER BY name
LIMIT 1
)
UNION
SELECT cat FROM Cat cat WHERE cat.name = :param_3
15.6. DBMS compatibility
Currently there is no emulation implemented for databases that do not support set operations natively.
One type of emulation that is implemented however is for the non-distinct variants INTERSECT ALL and EXCEPT ALL in case the distinct variant is supported.
The emulation for the non-distinct variants is implemented by adding the ROW_NUMBER to an operand which is removed afterwards.
The DBMS support for set operations is quite good.
| DBMS | UNION ALL | UNION | INTERSECT ALL | INTERSECT | EXCEPT ALL | EXCEPT |
|---|---|---|---|---|---|---|
PostgreSQL |
yes |
yes |
yes |
yes |
yes |
yes |
MySQL |
yes |
yes |
no 1 |
no 1 |
no 1 |
no 1 |
H2 |
yes |
yes |
no 2 |
yes |
no 2 |
yes |
Oracle |
yes |
yes |
yes 3 |
yes |
yes 3 |
yes |
SQL Server |
yes |
yes |
yes 3 |
yes |
yes 3 |
yes |
DB2 |
yes |
yes |
yes |
yes |
yes |
yes |
-
MySQL only supports the
UNIONandUNION ALLoperator -
For implementing the
ALLvariant, a row number for a grouping is required i.e.ROW_NUMER() OVER()which isn’t supported by H2 -
Emulated via
ROW_NUMBER
Except for H2 the operations can also be used in almost any context.
| DBMS | Use in CTE | In Subquery with LIMIT |
|---|---|---|
PostgreSQL |
yes |
yes |
MySQL |
no |
yes |
H2 |
no 1 |
no |
Oracle |
yes |
yes |
SQL Server |
yes |
yes |
DB2 |
yes |
yes |
-
Since CTEs are pretty much experimental in H2, you might encounter problems like with parameters
16. Entity functions
Entity functions are the equivalent of table-valued or table-generating functions in the ORM realm.
Currently, entity functions aren’t implemented but are about to be. See #181 for further information.
17. JPQL functions
JPQL offers many built-in functions as you can see in the expressions chapter and as of JPA 2.1 has a syntax for calling database specific functions.
Normally when using the function syntax FUNCTION ( function_name (, args)* ), the JPA provider puts a function call into the SQL like function_name ( args* ).
Instead of simply passing through the function invocation to the SQL, Blaze Persistence decided to reuse the function syntax but also allows the direct function call syntax function_name ( args* )
to allow calling custom JpqlFunction implementations that can be registered.
JPQL functions are registered at configuration time and are integrated into a persistence unit, so you could even use the functions by using the JPA provider specific invocation syntax directly.
Except for a few special built-in functions, every function has DBMS specific implementations of the JpqlFunction interface
that are registered through a JpqlFunctionGroup on the
CriteriaBuilderConfiguration.
Depending on the DBMS that is encountered at runtime, Blaze Persistence selects the appropriate functions during configuration and registers them in the persistence unit.
17.1. Special built-in functions
These functions have a deeper integration with the query building process and do not directly generate SQL.
17.1.1. SIZE function
The SIZE function, which was already briefly explained in the Collection functions section, returns the number of elements of a mapped collection.
This function is defined by JPQL and Blaze Persistence chose to improve the performance by applying custom query transformations when encountering it.
Normally, a JPA provider will not care to optimize the SIZE function for you and will simply generate a correlated subquery for any uses.
Blaze Persistence currently has transformations for SIZE invocations in the SELECT and ORDER BY clauses.
These transformations happen during query generation, so you can see the result by calling getQueryString() on your query builder.
The transformation will
-
add a
LEFT JOINfor the collection of theSIZEinvocation -
add a
GROUP BYfor the entity that owns the collection -
and replace the
SIZEinvocation with aCOUNTorCOUNT_TUPLEexpression
This transformation also works when having multiple SIZE invocations. If an invocation can’t be transformed that way, a simple correlated subquery is generated.
There are different reasons why a transformation could fail, but the most common are
-
The collection is a bag
-
The query has multiple query roots
-
Multiple
SIZEinvocations with different collection owners
If you prefer subqueries or have problems with the transformation, you can turn the transformation off via a configuration property.
Since the transformation introduces aggregate expressions into the query, it is necessary to have implicit group by generation enabled
if other expressions appear in the SELECT, ORDER BY or HAVING clause. By default implicit group by generation is enabled
and we recommend you don’t turn it off.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "cat")
.select("cat.name")
.select("SIZE(kittens)")
.orderByDesc("id");
SELECT cat.name, COUNT_TUPLE(kittens_1.id) FROM Cat cat LEFT JOIN cat.kittens kittens_1 GROUP BY cat.id, cat.name ORDER BY cat.id DESC NULLS LAST
As you can see, the expressions cat.name and id of the SELECT and ORDER BY clause are implicitly added to the GROUP BY because of the aggregate function COUNT_TUPLE being used.
17.1.2. OUTER function
The OUTER function is an extension provided by Blaze Persistence that can be used to refer to attributes of the parent query’s root.
By using OUTER you can avoid introducing the query root alias of the outer query into the subquery directly.
CriteriaBuilder<Tuple> cb = cbf.create(em, Tuple.class)
.from(Cat.class, "cat")
.whereExists()
.from(Cat.class, "subCat")
.where("subCat.name").notEqExpression("OUTER(name)")
.end();
SELECT cat
FROM Cat cat
WHERE EXISTS (
SELECT 1
FROM Cat subCat
WHERE subCat.name <> cat.name
)
The OUTER invocation is replaced by the absolute path expression.
Currently it is not allowed to have nested OUTER invocations, but this is already planned. For more information see #317
17.2. Built-in functions
These functions are provided by Blaze Persistence and are registered by default in every CriteriaBuilderConfiguration.
They can be overridden at configuration time if desired.
Every of the following functions has to be invoked with the JPA 2.1 function syntax.
17.2.1. COUNT_TUPLE function
Syntax: COUNT_TUPLE ( ('DISTINCT')?, args+ )
The COUNT_TUPLE function is like the regular COUNT function, but in addition allows to do distinct counting on multiple and embeddable attributes.
Some JPA providers ignore that some DBMS don’t support distinct counts on multiple columns and generate broken SQL.
This function will transform the distinct count for DBMS that don’t have native support to something equivalent.
The emulation is based on the idea, that the NUL character \0 is a valid character in any text type on the DBMS but won’t ever appear in real data.
A distinct count for two columns can be emulated by doing the following expression instead
COUNT(DISTINCT
COALESCE(
NULLIF(
COALESCE(
COL1 || '', (1)
'\0' (2)
),
'' (3)
),
'\01' (4)
) ||
'\0' || (5)
COALESCE(
NULLIF(
COALESCE(
COL2 || '',
'\0'
),
''
),
'\02'
)
)
| 1 | Concat with empty string to get implicit conversion to text type |
| 2 | NULL values are replaced by the NUL character |
| 3 | Produce NULL if the value is an empty string for the next step |
| 4 | The NULL is required so we can transform empty strings to the text NUL character concatenated with the column number i.e. '\0' || '1' |
| 5 | Separate the column values with a NUL character |
By doing a distinct count on the resulting string, the ANSI SQL distinct counting can be fully emulated.
17.2.2. CAST functions
Syntax: CAST_XXX ( argument (, sqlCastTypeOverride)? )
There are multiple different cast functions for different data types.
-
Boolean-CAST_BOOLEAN -
Byte-CAST_BYTE -
Short-CAST_SHORT -
Integer-CAST_INTEGER -
Long-CAST_LONG -
Float-CAST_FLOAT -
Double-CAST_DOUBLE -
Character-CAST_CHARACTER -
String-CAST_STRING -
BigInteger-CAST_BIGINTEGER -
BigDecimal-CAST_BIGDECIMAL -
java.sql.Time-CAST_TIME -
java.sql.Date-CAST_DATE -
java.sql.Timestamp-CAST_TIMESTAMP -
java.util.Calendar-CAST_CALENDAR
A cast invocation will always generate a ANSI SQL cast. The SQL data type for a Java type is determined by DbmsDialect.getSqlType()
and can be overridden using the optional sqlCastTypeOverride parameter that is passed as string, e.g. 'varchar(100)'.
By providing a custom DBMS dialect you can override these types.
CriteriaBuilder<String> cb = cbf.create(em, String.class)
.from(Cat.class, "cat")
.select("CAST_STRING(cat.age)");
SELECT CAST_STRING(cat.age) FROM Cat cat
17.2.3. TREAT functions
Syntax: TREAT_XXX ( argument )
| This function is used internally and no user should ever have the need for this! |
There are multiple different treat functions for different data types.
-
Boolean-TREAT_BOOLEAN -
Byte-TREAT_BYTE -
Short-TREAT_SHORT -
Integer-TREAT_INTEGER -
Long-TREAT_LONG -
Float-TREAT_FLOAT -
Double-TREAT_DOUBLE -
Character-TREAT_CHARACTER -
String-TREAT_STRING -
BigInteger-TREAT_BIGINTEGER -
BigDecimal-TREAT_BIGDECIMAL -
java.sql.Time-TREAT_TIME -
java.sql.Date-TREAT_DATE -
java.sql.Timestamp-TREAT_TIMESTAMP -
java.util.Calendar-TREAT_CALENDAR
A treat invocation will only adjust the type of the expression in the JPQL expression and not cause an explicit cast on the DBMS side. This can be used for cases when the type of an expression is actually known but can’t be inferred.
This is an internal function that is used to implement the VALUES clause for basic types. It is not intended for direct use and might change without notice.
|
17.2.4. Temporal DIFF functions
Syntax: XXX_DIFF ( start, end )
Calculates the difference between the two given temporals like end - start and returning the difference in the requested unit as truncated integer.
The possible units and the respective function names are:
-
Microsecond -
MICROSECOND_DIFF- Extract EPOCH_MICROSECOND and subtract -
Millisecond -
MILLISECOND_DIFF- Extract EPOCH_MILLISECOND and subtract -
Second -
SECOND_DIFForEPOCH_DIFF- Extract EPOCH and subtract -
Minute -
MINUTE_DIFF- Extract EPOCH and subtract divided by 60 -
Hour -
HOUR_DIFF- Extract EPOCH and subtract divided by 60 * 60 -
Day -
DAY_DIFF- Extract days and subtract -
Week -
WEEK_DIFF- Extract days and subtract dived by 7 -
Month -
MONTH_DIFF- Extract months and subtract -
Quarter -
QUARTER_DIFF- Extract months and subtract divided by 3 -
Year -
YEAR_DIFF- Extract months and subtract divided by 12
If end < start i.e. the value of end is before start, the result is negative. You are advised to explicitly handle this case or use the ABS function.
17.2.5. Temporal extract functions
Syntax: XXX ( argument )
Extracts the requested field of temporal argument like specified by the ANSI SQL EXTRACT expression.
The possible fields and the respective function names are:
-
Microsecond -
MICROSECOND -
Millisecond -
MILLISECOND -
Second -
SECOND -
Minute -
MINUTE -
Hour -
HOUR -
Day -
DAY -
Day of week -
DAYOFWEEK- an integer between 1 (Sunday) and 7 (Saturday) -
Day of week -
ISODAYOFWEEK- an integer between 1 (Monday) and 7 (Sunday) -
Day of year -
DAYOFYEAR- an integer between 1 and 366 -
Week -
WEEKorISO_WEEK- an integer between 1 and 53 -
Year week -
YEAR_WEEK- a string with the formatIYYY-IW -
Week of year -
WEEK_OF_YEAR -
Year of week -
YEAR_OF_WEEK -
Month -
MONTH -
Year -
YEAR -
Epoch -
EPOCHorEPOCH_SECONDS -
Epoch days -
EPOCH_DAYS -
Epoch milliseconds -
EPOCH_MILLISECONDS -
Epoch microseconds -
EPOCH_MICROSECONDS
WEEK and ISO_WEEK return the ISO based week number, which may be in the previous year, whereas WEEK_IN_YEAR returns the week number counting from the first day of the year. To determine the year of that the ISO based week started on, use the YEAR_OF_WEEK, or use the YEAR_WEEK which returns the week and its year as a string in IYYY-IW format.
|
17.2.6. Temporal truncate functions
Syntax: TRUNC_XXX ( argument )
Truncate to specified precision.
The possible units and the respective function names are:
-
Microseconds -
TRUNC_MICROSECONDS -
Millisecond -
TRUNC_MILLISECONDS -
Second -
TRUNC_SECOND -
Minute -
TRUNC_MINUTE -
Hour -
TRUNC_HOUR -
Day -
TRUNC_DAY -
ISO Week -
TRUNC_WEEK -
Month -
TRUNC_MONTH -
Quarter -
TRUNC_QUARTER -
Year -
TRUNC_YEAR
17.2.7. Temporal addition functions
Syntax: ADD_XXX ( date, number )
This function takes a timestamp and an integer value representing the value to be added as unit as defined by the function name. The return type is a timestamp. The value obviously can be negative which allows to subtract a value.
The possible units and the respective function names are:
-
Microseconds -
ADD_MICROSECONDS -
Millisecond -
ADD_MILLISECONDS -
Second -
ADD_SECOND -
Minute -
ADD_MINUTE -
Hour -
ADD_HOUR -
Day -
ADD_DAY -
ISO Week -
ADD_WEEK -
Month -
ADD_MONTH -
Quarter -
ADD_QUARTER -
Year -
ADD_YEAR
17.2.8. GREATEST function
Syntax: GREATEST ( argument1, argument2 (, ...)? )
Returns the greatest value of all given arguments.
17.2.9. LEAST function
Syntax: LEAST ( argument1, argument2 (, ...)? )
Returns the smallest value of all given arguments.
17.2.10. REPEAT function
Syntax: REPEAT ( argument1, argument2 )
Returns a string with the argument1 repeated for argument2 times.
17.2.11. LIMIT function
Syntax: LIMIT ( subquery, limit (, offset )? )
Applies the DBMS native way of doing LIMIT and OFFSET with the given values limit and offset on the given subquery.
The function makes use of the DbmsLimitHandler provided by the DbmsDialect.
Normally, you don’t need to use this function directly as the subquery builder API offers direct support for setFirstResult() and setMaxResults(). It is not intended for direct use and might change without notice.
|
| This is an internal function which is not intended for direct use and might change without notice. |
If you use this function directly, beware that for some DBMS it might not be possible to use parameters in LIMIT and OFFSET so if you really require a parameter, make sure it works for your database.
|
17.2.12. PAGE_POSITION function
Syntax: PAGE_POSITION ( id_query, entity_id )
Returns the absolute 1-based position of the entity with the given id within the result produced by the given id query. The id query must select only the id of an entity and must be of a basic type. The entity id can be a parameter or plain value.
This is an internal function that is used to implement pageAndNavigate(Object entityId, int maxResults). It is not intended for direct use and might change without notice.
|
17.2.13. GROUP_CONCAT function
Syntax: GROUP_CONCAT ( ('DISTINCT')?, expression (, 'SEPARATOR', separator_expression)? (, 'ORDER BY' (, order_by_expression (, order_specification ) )+ )? )
Where order_specification is one of 'ASC', 'DESC', 'ASC NULLS FIRST', 'ASC NULLS LAST', 'DESC NULLS FIRST', 'DESC NULLS LAST' and separator_expression by is ',' by default.
Aggregates/concatenates the values produced by expression to a single string separated by separator_expression in the order defined by the ORDER BY clause.
Example: GROUP_CONCAT('DISTINCT', d.name, 'SEPARATOR', ', ', 'ORDER BY', d.name, d.id, 'DESC')
| This function might not be supported by all DBMS, so make sure your target database does before using it |
WINDOW functions
Syntax: WINDOW_XXX ( arguments+, (, 'FILTER' (, filter_by_expression)+ )? (, 'PARTITION BY' (, partition_by_expression)+ )? (, 'ORDER BY' (, order_by_expression (, order_specification ) )+ )? ((, 'RANGE' | 'ROWS' | 'GROUPS') (, ( 'UNBOUNDED PRECEDING' | ( number_expression, 'PRECEDING') | 'CURRENT ROW'), 'AND', ( 'UNBOUNDED FOLLOWING' | ( number_expression, 'FOLLOWING') | 'CURRENT ROW' ) ) )
Where order_specification is one of 'ASC', 'DESC', 'ASC NULLS FIRST', 'ASC NULLS LAST', 'DESC NULLS FIRST', 'DESC NULLS LAST'.
For every aggregate function, there is a window function.
-
SUM-WINDOW_SUM -
AVG-WINDOW_AVG -
MAX-WINDOW_MAX -
MIN-WINDOW_MIN -
COUNT-WINDOW_COUNT -
GROUP_CONCAT-WINDOW_GROUP_CONCAT -
EVERY-WINDOW_EVERY -
OR_AGG-WINDOW_OR_AGG
There also are the following window functions:
-
ROW_NUMBER -
RANK -
DENSE_RANK -
PERCENT_RANK -
CUME_DIST -
NTILE -
LEAD -
LAG -
FIRST_VALUE -
LAST_VALUE -
NTH_VALUE
Window functions are explained in more depth in the window functions chapter.
Example: WINDOW_AVG(c.age, 'FILTER', c.age > 10, 'PARTITION BY', c.name)
| This is an internal function which is not intended for direct use and might change without notice. |
| This function might not be supported by all DBMS, so make sure your target database does before using it |
17.2.14. SET functions
Syntax: SET_XXX ( subqueries+ (, 'ORDER BY' (, order_by_expression (, order_specification ) )+ )? (, 'LIMIT', limit_expression (, 'OFFSET', offset_expression )? )? )
| This function is used internally and no user should ever have the need for this! |
For every type of set operation, there is a function.
-
UNION-SET_UNION -
UNION_ALL-SET_UNION_ALL -
INTERSECT-SET_INTERSECT -
INTERSECT_ALL-SET_INTERSECT_ALL -
EXCEPT-SET_EXCEPT -
EXCEPT_ALL-SET_EXCEPT_ALL
Applies the DBMS native way of connecting the given subqueries with the requested set operation, ordering and limiting/skipping.
The function makes use of DbmsDialect.appendSet() for rendering.
| This is an internal function that is used to implement set operations for subqueries. It is not intended for direct use and might change without notice. |
For further information on DBMS support take a look at the set operations chapter.
17.2.15. COMPARE_ROW_VALUE function
Syntax: COMPARE_ROW_VALUE ( comparison_operator, CASE WHEN (1=NULLIF(1,1) AND row_value_1_1=row_value_2_1 AND row_value_1_2=nullif(1,1) ... AND row_value_1_n=row_value_2_n AND row_value_1_2=row_value_2_2 THEN 1 ELSE 0 END )
Produces a DBMS native row value comparison expression such as (row_value_1_1, row_value_1_2, ..., row_value_1_n) < (row_value_2_1, row_value_2_2, ..., row_value_2_n).
| This is an internal function that is used to implement optimized keyset pagination. It is not intended for direct use and might change without notice. |
17.2.16. COMPARE_ROW_VALUE_SUBQUERY function
Syntax: COMPARE_ROW_VALUE_SUBQUERY ( comparison_operator, expr1, expr2, ..., subquery )
Renders (expr1, expr2, ...) comparison_operator (subquery).
| This is an internal function that is used to implement inlining of an id query as subquery into the main query. It is not intended for direct use and might change without notice. |
17.2.17. SUBQUERY function
Syntax: SUBQUERY ( subquery )
Simply renders the subquery argument.
| This is an internal function that is used to bypass the Hibernate parser for rendering subqueries as aggregate function arguments. |
17.2.18. ENTITY_FUNCTION function
Syntax: ENTITY_FUNCTION ( subquery, entityName, valuesClause, valuesAliases, syntheticPredicate )
Rewrites the passed in query by replacing placeholder SQL parts with the proper SQL.
This is an internal function that is used to implement entity functions like the VALUES clause for subqueries. It is not intended for direct use and might change without notice.
|
17.2.19. ALIAS function
Syntax: ALIAS ( expr, alias )
Renders the expression argument with the given alias like expr as alias.
| This is an internal function that is used to assign SQL aliases for subquery select items. |
17.2.20. COLUMN_TRUNC function
Syntax: COLUMN_TRUNC ( subquery, number )
Renders (select col0, col1, ... from (subquery) tmp) until colX for X < number to truncate the subquery select items.
| This is an internal function that is used to implement ordering by select aliases of complex expression within subqueries. |
17.2.21. NULLFN function
Syntax: NULLFN ( ... )
Just renders null.
| This is an internal function that is used to implement inlining of CTEs or subqueries in the FROM clause. |
17.2.22. NULL_SUBQUERY function
Syntax: NULL_SUBQUERY ()
Just renders (select null).
| This is an internal function that is used to implement bounded counting for SQL Server. |
17.2.23. COUNT_WRAPPER function
Syntax: COUNT_WRAPPER ( subquery )
Just renders (select count(*) form (<subquery>).
| This is an internal function that is used to implement bounded counting. |
17.2.24. EXIST function
Syntax: EXIST ( subquery, (any)? )
When a second argument is given, renders case when not exists <subquery> then 1 else 0 end, otherwise case when exists <subquery> then 1 else 0 end.
This is an internal function that is used to implement inlining of CTEs or subqueries in the FROM clause for correlated subqueries in an EXISTS predicate.
|
17.2.25. PARAM function
Syntax: PARAM ( subquery, parameter )
Uses the first argument just to fake the type and renders only the second argument.
This is an internal function that is used to implement support for parameters in the SELECT clause.
|
17.2.26. COLLECTION_DML_SUPPORT function
Syntax: COLLECTION_DML_SUPPORT ( expression )
Renders through 1:1 which is then replaced later in the SQL.
| This is an internal function that is used to implement support for referring to the collection table alias used in DML statements. |
17.2.27. REPLACE function
Syntax: REPLACE ( string, search, replacement )
Returns a string with all occurrences of search within string replaced with replacement.
17.2.28. BASE64 function
Syntax: BASE64 ( bytes )
Returns a Base64 encoded string that represents the passed bytes.
17.2.29. JSON_GET
Sytax: JSON_GET(jsonDocument, pathSegment1, ..., pathSegmentN)
Where pathSegmentN is a quoted literal json key or array index.
Returns the json node (scalar, object or array) within the jsonDocument designated by the path segments.
Usage examples:
json_get('{ "owner": { "firstName": "John", "lastName": "Smith", hobbies: [ "football", "tennis" ] } }', 'owner', 'firstName')
--> John
json_get('{ "owner": { "firstName": "John", "lastName": "Smith", hobbies: [ "football", "tennis" ] } }', 'owner', 'hobbies', '1')
--> tennis
17.2.30. JSON_SET
Sytax: JSON_SET(jsonDocument, newValue, pathSegment1, ..., pathSegmentN)
Where newValue is a quoted json node (scalar, object or array) and pathSegmentN is a quoted literal json key or array index.
Returns the modified jsonDocument that results from replacing the json node designated by the path segments with newValue.
Setting JSON null is not supported for Oracle.
Usage examples:
json_set('{ "owner": { "firstName": "John", "lastName": "Smith", hobbies: [ "football", "tennis" ] } }', 'James', 'owner', 'firstName')
--> { "owner": { "firstName": "James", "lastName": "Smith", hobbies: [ "football", "tennis" ] } }
json_set('{ "owner": { "firstName": "John", "lastName": "Smith", hobbies: [ "football", "tennis" ] } }', 'table tennis', 'owner', 'hobbies', '1')
--> { "owner": { "firstName": "James", "lastName": "Smith", hobbies: [ "football", "table tennis" ] } }
17.2.31. STRING_JSON_AGG function
Syntax: STRING_JSON_AGG ( key1, value1, ..., keyN, valueN )
An aggregate function that aggregates to a JSON string containing only string values or null.
[
{
"key1": "value1",
...
"keyN": "valueN"
},...
]
17.2.32. STRING_XML_AGG function
Syntax: STRING_XML_AGG ( key1, value1, ..., keyN, valueN )
An aggregate function that aggregates to a XML string. A null value is omitted.
<e>
<key1>value1</key1>
...
<keyN>valueN</keyN>
</e>
<e>
...
</e>
...
17.2.33. TO_STRING_JSON function
Syntax: TO_STRING_JSON ( subquery, key1, ..., keyN )
Transforms the subquery into an expression that returns the results of the subquery as JSON string containing only string values or null.
The select items of the subquery are matched positionally against the key arguments i.e. the first select item of the subquery will be mapped to key1 and so on.
[
{
"key1": "value1",
...
"keyN": "valueN"
},...
]
17.2.34. TO_STRING_XML function
Syntax: TO_STRING_XML ( subquery, key1, ..., keyN )
Transforms the subquery into an expression that returns the results of the subquery as XML string. A null value is omitted.
The select items of the subquery are matched positionally against the key arguments i.e. the first select item of the subquery will be mapped to key1 and so on.
<e>
<key1>value1</key1>
...
<keyN>valueN</keyN>
</e>
<e>
...
</e>
...
17.3. Custom JPQL functions
Apart from providing many useful functions out of the box, Blaze Persistence also allows to implement custom JPQL functions that can be called just like any other non-standard function, via the JPA 2.1 function syntax. In addition to that, you can even override existing implementations. So if you need to workaround bugs or want to improve something, you don’t have to wait for a release.
Custom functions are registered via CriteriaBuilderConfiguration.registerFunction()
and expect an instance of a JpqlFunctionGroup. A JpqlFunctionGroup is a container for a custom function that defines the function name,
whether it is an aggregate function and the DBMS specific implementations of it as instances of JpqlFunction.
When a function is marked as being an aggregate function, it is treated like any other aggregate function regarding implicit group by generation. This means that the occurrence of the function invocation in a query builder, will trigger implicit group by generation.
During the building of a CriteriaBuilderFactory
the DBMS specific implementations of the registered JpqlFunctionGroup instances are selected. If there is no DBMS specific one available, it will fallback to the default.
If there is no default implementation available, a warning message is emitted, saying that no applicable function was found.
17.3.1. Implementing and registering a custom JPQL function
Let’s implement a simple function for illustration purposes. The function should calculate the sum of two arguments and be called CALCULATE_SUM.
public class SumFunction implements JpqlFunction {
@Override
public boolean hasArguments() {
return true; (1)
}
@Override
public boolean hasParenthesesIfNoArguments() {
return true; (2)
}
@Override
public Class<?> getReturnType(Class<?> firstArgumentType) {
return firstArgumentType; (3)
}
@Override
public void render(FunctionRenderContext context) {
context.addArgument(0); (4)
context.addChunk("+");
context.addArgument(1);
}
}
| 1 | Denotes if the function has arguments |
| 2 | Denotes whether the function will have parenthesis when no arguments are passed |
| 3 | The return type of the function, in our case, it’s going to be the same as the firstArgumentType |
| 4 | Adds the first argument to the resulting sql, then the plus operator and finally the second argument |
The getReturnType() method can only make use of the first argument type because Hibernate does not expose other argument types,
but that should be enough most of the time. In case you would need other argument types, you should create separately named functions to handle the return types.
The actual rendering of SQL is done with addArgument()
and addChunk of the FunctionRenderContext.
With addArgument(int index) you add the argument at the given index to the SQL output.
You can also get access to the SQL string of the argument by using getArgument().
To get the number of actual arguments, you can use getArgumentsSize().
Finally, it is also possible to add an arbitrary string to the SQL output with addChunk(String).
| The API is admittedly bad and will be reworked in the next major version. |
Using the TemplateRenderer will hopefully help mitigate the pain a bit.
|
In order to register the function, you only have to create a JpqlFunctionGroup with that JpqlFunction and register that on the configuration.
See the environment section for how to get access to the CriteriaBuilderConfiguration.
CriteriaBuilderConfiguration config = //...
JpqlFunctionGroup calculateSumFunction = new JpqlFunctionGroup("CALCULATE_SUM", new SumFunction());
config.registerFunction(calculateSumFunction);
If you want to register a JpqlFunction for a specific DBMS then use JpqlFunctionGroup.add().
CriteriaBuilderConfiguration config = //...
JpqlFunctionGroup calculateSumFunction = new JpqlFunctionGroup("CALCULATE_SUM", new SumFunction());
calculateSumFunction.add("h2", null);
config.registerFunction(calculateSumFunction);
Passing null like in the example above, will disable the function for the specified DBMS.
Currently you can register functions for the following DBMS
-
mysql
-
db2
-
postgresql
-
oracle
-
microsoft
-
sybase
-
h2
-
cubrid
-
hsql
-
informix
-
ingres
-
interbase
-
sqlite
-
firebird
The determination of the DBMS happens in implementations of EntityManagerFactoryIntegrator
that reside in the JPA provider integrations. The determination is provider specific and there is currently no way of overriding this behavior.
17.3.2. Parameters in JPQL functions
If one of the arguments of a JPQL function contains a parameter, you must render the arguments in the same order to the SQL. At the time of SQL rendering, there are only positional parameters, so rendering arguments in a different order might lead to wrong parameter bindings. Another possible problem might arise when you want to make use of an argument multiple times in the resulting SQL. Since the ORM doesn’t know of the new parameter, the value won’t be bound or worse, will be bound to a wrong value.
Here are some solutions to handling the problems with parameters
-
Disallow parameters by throwing a runtime exception
-
Change the function specification so that the argument order doesn’t have to be changed (doesn’t work when only few DBMS require a different order)
-
Render the arguments in the correct order into a SQL
VALUESclause or simpleSELECTstatement and use the aliases instead of the arguments directly
For an example on using the VALUES clause take a look at the implementation of e.g. PostgreSQLDayDiffFunction.
17.4. Custom JPQL macros
A JpqlMacro is a special kind of function that is evaluated at expression parse time and produces a JPQL expression.
Contrary to a JpqlFunction, a macro only needs to provide a render() method and does not suffer of the problems regarding parameters since it produces a JPQL expression rather than SQL.
One of the possible use cases for macros is to have user defined expression expansions to avoid boilerplate. Let’s implement a macro called ITEM_TOTAL.
public class ItemTotalMacro implements JpqlMacro {
@Override
public void render(FunctionRenderContext context) {
context.addChunk("(1 + ");
context.addArgument(0);
context.addChunk(".taxClass.taxValue / 100) * ");
context.addArgument(0);
context.addChunk(".quantity * ");
context.addArgument(0);
context.addChunk(".price");
}
}
When passing in an expression like alias, the macro will produce the expression (1 + alias.taxClass.taxValue / 100) * alias.quantity * alias.price.
The macro can be either globally registered in the configuration or on a case by case basis directly on the CriteriaBuilder.
See the environment section for how to get access to the CriteriaBuilderConfiguration.
CriteriaBuilderConfiguration config = //...
config.registerMacro("ITEM_TOTAL", new ItemTotalMacro());
Since macros aren’t actually functions and are pretty unique to Blaze Persistence, we decided to allow invoking them directly instead of having to use the JPA 2.1 function syntax.
Let’s see how the macro can be used to easily calculate the total amount of an order.
CriteriaBuilder<Long> cb = cbf.create(em, Long.class)
.from(Order.class, "o")
.select("SUM(ITEM_TOTAL(o.items))");
SELECT SUM((1 + taxClass_1.taxValue / 100) * items_1.quantity * items_1.price) FROM Order o LEFT JOIN o.items items_1 LEFT JOIN items_1.taxClass taxClass_1
To wrap it up, macros help to reuse expressions and avoid boilerplate!
Currently there are no built-in JPQL macros available in the core part of Blaze Persistence but only in the entity view module.
One of the use cases for JPQL macros is the VIEW_ROOT function of the Entity Views module.
|
18. Customize DBMS dialect
A DBMS dialect abstracts away some of the specifics of a DBMS like e.g. whether set operations are supported. Although Blaze Persistence tries very hard to make the DBMS dialects work on the most recent DBMS versions, it might sometimes be necessary to adapt the dialect to specific needs.
In general, you are well advised to extend the DBMS dialect that matches your DBMS best and override the methods you want in order to get the desired behavior.
A custom DBMS dialect must be registered on the configuration at boot time via registerDialect().
See the environment section for how to get access to the CriteriaBuilderConfiguration.
CriteriaBuilderConfiguration config = //...
config.registerDialect("h2", new MyH2DbmsDialect());
18.1. Custom SQL type mappings
Sometimes it might be necessary to adapt the Java type to SQL type mappings for your DBMS. In order to do so, introduce a new method getSqlTypes and extend the dialect like
public class MyH2DbmsDialect extends H2DbmsDialect {
public MyH2DbmsDialect() {
super(getSqlTypes());
}
private static Map<Class<?>, String> getSqlTypes() {
Map<Class<?>, String> types = new HashMap<Class<?>, String>();
types.put(String.class, "nvarchar");
return types;
}
}
18.2. Other customizations
There are many other customizations possible. Take a look at the DbmsDialect API for more information.
19. Configuration
Blaze Persistence can be configured by setting properties on a CriteriaBuilderConfiguration
object and creating a CriteriaBuilderFactory from it.
You can also set configuration properties on a per builder basis via the setProperty(String, String) method.
19.1. Configuration properties
19.1.1. COMPATIBLE_MODE
Enables JPA compatibility mode to disallow the usage of vendor specific extensions. This will result in higher portability.
| Key | com.blazebit.persistence.compatible_mode |
|---|---|
Type |
boolean |
Default |
false |
Applicable |
Configuration only |
19.1.2. RETURNING_CLAUSE_CASE_SENSITIVE
Defines whether column names should be used with the case in which they are given or as lower case when returning column values from a DML query.
This is mostly relevant for PostgreSQL which requires false to work properly.
| Key | com.blazebit.persistence.returning_clause_case_sensitive |
|---|---|
Type |
boolean |
Default |
true |
Applicable |
Always |
19.1.3. SIZE_TO_COUNT_TRANSFORMATION
Defines whether the SIZE to COUNT tranformation should be applied to queries or not. The transformation can be very beneficial especially for databases that can’t optimize subqueries properly within the context of a parent query. This property exists just so you can turn the transformation off if you encounter problems.
| Key | com.blazebit.persistence.size_to_count_transformation |
|---|---|
Type |
boolean |
Default |
true |
Applicable |
Always |
19.1.4. IMPLICIT_GROUP_BY_FROM_SELECT
Defines whether non-aggregate expressions from the SELECT clause should be automatically added to the GROUP BY. Some databases require that all non-aggregate expressions must be included in the GROUP BY clause which is pretty annoying. This feature can make writing queries a lot easier since it will implicitly copy expressions over to the GROUP BY clause.
| Key | com.blazebit.persistence.implicit_group_by_from_select |
|---|---|
Type |
boolean |
Default |
true |
Applicable |
Always |
19.1.5. IMPLICIT_GROUP_BY_FROM_HAVING
Defines whether non-aggregate expressions from the HAVING clause should be automatically added to the GROUP BY. Some databases require that all non-aggregate expressions must be included in the GROUP BY clause which is pretty annoying. This feature can make writing queries a lot easier since it will implicitly copy expressions over to the GROUP BY clause.
| Key | com.blazebit.persistence.implicit_group_by_from_having |
|---|---|
Type |
boolean |
Default |
true |
Applicable |
Always |
19.1.6. IMPLICIT_GROUP_BY_FROM_ORDER_BY
Defines whether non-aggregate expressions from the ORDER BY clause should be automatically added to the GROUP BY. Some databases require that all non-aggregate expressions must be included in the GROUP BY clause which is pretty annoying. This feature can make writing queries a lot easier since it will implicitly copy expressions over to the GROUP BY clause.
| Key | com.blazebit.persistence.implicit_group_by_from_order_by |
|---|---|
Type |
boolean |
Default |
true |
Applicable |
Always |
19.1.7. EXPRESSION_OPTIMIZATION
Defines whether expressions should be optimized.
| Key | com.blazebit.persistence.expression_optimization |
|---|---|
Type |
boolean |
Default |
true |
Applicable |
Configuration only |
19.1.8. EXPRESSION_CACHE_CLASS
The full qualified expression cache implementation class name.
| Key | com.blazebit.persistence.expression.cache_class |
|---|---|
Type |
String |
Default |
com.blazebit.persistence.parser.expression.ConcurrentHashMapExpressionCache |
Applicable |
Configuration only |
19.1.9. VALUES_CLAUSE_FILTER_NULLS
Defines whether tuples of a VALUES clause with all NULL values should be filtered out. The property can be changed for a criteria builder before using the VALUES clause.
| Key | com.blazebit.persistence.values.filter_nulls |
|---|---|
Type |
boolean |
Default |
true |
Applicable |
Always |
19.1.10. PARAMETER_AS_LITERAL_RENDERING
Defines whether parameters should be rendered as literals when the type can not be inferred, or always as parameter. The property can be changed for a criteria builder before constructing a query.
| Key | com.blazebit.persistence.parameter_literal_rendering |
|---|---|
Type |
boolean |
Default |
true |
Applicable |
Always |
19.1.11. OPTIMIZED_KEYSET_PREDICATE_RENDERING
Defines whether the keyset predicate should be rendered in an optimized form so that database optimizers are more likely to use indices. The property can be changed for a criteria builder before constructing a query.
| Key | com.blazebit.persistence.optimized_keyset_predicate_rendering |
|---|---|
Type |
boolean |
Default |
true |
Applicable |
Always |
19.1.12. INLINE_ID_QUERY
Defines whether the id query in a PaginatedCriteriaBuilder is inlined into the object query as subquery.
Valid values for this property are true, false or auto.
The property can be changed for a criteria builder before generating the query.
| Key | com.blazebit.persistence.inline_id_query |
|---|---|
Type |
String/boolean |
Default |
auto |
Applicable |
Always |
19.1.13. INLINE_COUNT_QUERY
Defines whether the count query in a PaginatedCriteriaBuilder is inlined into the id or object query as select item.
Valid values for this property are true, false or auto.
The property can be changed for a criteria builder before generating the query.
| Key | com.blazebit.persistence.inline_count_query |
|---|---|
Type |
String/boolean |
Default |
auto |
Applicable |
Always |
19.1.14. INLINE_CTES
Defines whether non-recursive CTEs should be inlined into the query by default.
Valid values for this property are true, false or auto.
The property can be changed for a criteria builder before adding a CTE.
| Key | com.blazebit.persistence.inline_ctes |
|---|---|
Type |
String/boolean |
Default |
true |
Applicable |
Always |
19.1.15. QUERY_PLAN_CACHE_ENABLED
Enables or disbales the caching and reuse of query plans.
Valid values for this property are true and false.
The property can be changed for a criteria builder before constructing a query.
| Key | com.blazebit.persistence.query_plan_cache_enabled |
|---|---|
Type |
String/boolean |
Default |
true |
Applicable |
Always |
19.2. Jpql functions
Custom functions that can be invoked via the JPA 2.1 function syntax FUNCTION('function_name', args...) or the non-standard function syntax function_name(args...) can be registered with registerFunction(JpqlFunctionGroup).
A JpqlFunctionGroup represents a logical function that can contain multiple implementations for various dbms and can be defined as being an aggregate function.
These functions are registered as native persistence provider functions and can therefore also be used with plain JPA APIs or the native persistence provider APIs. For more information refer to the JPQL functions section.
19.3. Dbms dialects
Dbms dialect implementations provide SQL-level abstractions for a specific dbms. Blaze Persistence comes with support for the following dbms:
-
h2
-
mysql
-
postgresql
-
db2
-
oracle
-
microsoft
By registering a custom implementation for a specific dbms via registerDialect(String, DbmsDialect) the default implementation will be overridden.
For more information refer to the Customize DBMS dialect section.
20. Window functions
Window functions provide the ability to perform aggregate calculations across sets of rows that are related to the current query row. Unlike regular aggregate functions, use of a window function does not cause rows to become grouped into a single output row.
| This function might not be supported by all DBMS, so make sure your target database does before using it |
20.1. Aggregate window functions
Any built-in aggregate function can be used as a window function. These are:
-
SUM- Returns the sum across the rows in the window -
AVG- Returns the average value across the rows in the window -
MAX- Returns the maximal across the rows in the window -
MIN- Returns the minimal across the rows in the window -
COUNT- Returns the count across the rows in the window
CriteriaBuilder<Tuple> criteria = cbf.create(em, Tuple.class)
.from(Person.class, "per")
.select("per.age")
.select("SUM(per.age) OVER (ORDER BY per.age ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)")
.orderByAsc("per.age")
select SUM(person0_.age) OVER (ORDER BY person0_.age DESC NULLS LAST ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) as col_1_0_ from person person0_ order by person0_.age ASC
20.2. General-Purpose Window Functions
The SQL standard defines the following window functions:
-
ROW_NUMBER- Returns the number of the current row within its partition, counting from1 -
RANK- Returns the rank of the current row considering gaps -
DENSE_RANK- Returns the rank of the current row disregarding gaps -
PERCENT_RANK- Returns the relative rank of the current row:(rank - 1) / (total rows - 1) -
CUME_DIST- Returns the relative rank of the current row:(number of rows preceding or peer with current row) / (total rows) -
NTILE- Returns an integer ranging from 1 to the argument value, dividing the partition as equally as possible -
LEAD- Returns the value evaluated at the row that is offset rows after the current row within the partition; if there is no such row, instead return the specifieddefaultvalue (which must be of the same type as value). Both theoffsetanddefaultvalue are evaluated with respect to the current row. If omitted, theoffsetdefaults to1and default tonull. -
LAG- Returns the value evaluated at the row that is offset rows before the current row within the partition; if there is no such row, instead return the specifieddefaultvalue (which must be of the same type as value). Both theoffsetanddefaultvalue are evaluated with respect to the current row. If omitted, theoffsetdefaults to1and default tonull. -
FIRST_VALUE- Returns the value evaluated at the row that is the first row of the window frame -
LAST_VALUE- Returns the value evaluated at the row that is the last row of the window frame -
NTH_VALUE- Returns the value evaluated at the row that is the nth row of the window frame
CriteriaBuilder<Tuple> criteria = cbf.create(em, Tuple.class)
.from(Person.class, "per")
.select("ROW_NUMBER() OVER (ORDER BY per.age)");
select ROW_NUMBER() OVER (ORDER BY person0_.age DESC NULLS LAST) as col_0_0_ from person person0_
20.3. Named Windows
Through the CriteriaBuilder API one can create named windows which can be reused between window function calls.
CriteriaBuilder<Tuple> criteria = cbf.create(em, Tuple.class)
.from(Person.class, "per")
.window("x").orderByAsc("per.age").rows().betweenUnboundedPreceding().andCurrentRow().end()
.select("MIN(per.age) OVER (x)")
.select("MAX(per.age) OVER (x)")
Named Windows can also be copied and modified in the OVER clause.
CriteriaBuilder<Tuple> criteria = cbf.create(em, Tuple.class)
.from(Person.class, "per")
.window("x").partitionBy("per.age").end()
.select("SUM(per.age) OVER (x ORDER BY per.id)")
| Note that the partition, order or range of a window definition can only be specified if the base window does not specify any partition, order or range. |
21. QueryDSL 4 integration
With the blaze-persistence-integration-querydsl-expressions features from Blaze Persistence can be used in existing QueryDSL code.
The blaze-persistence-integration-querydsl-expressions module implements an extended expression model for JPQL.Next, the query and expression language of Blaze Persistence.
The module provides a BlazeJPAQuery as a default implementation of JPQLNextQuery, which extends the all familiar JPQLQuery. BlazeJPAQuery is analog to JPAQuery.
Users can implement extensions on top of JPQLNextQuery by extending AbstractBlazeJPAQuery.
BlazeJPAQuery can be serialized using the JPQLNextSerializer, and may be rendered to a CriteriaBuilder using the BlazeCriteriaBuilderRenderer.
This allows for the queries to be executed through Blaze Persistence JPQL.Next query engine.
Be sure to use the JPQLNextTemplates or any Templates implementation that includes the extensions from JPQLNextTemplates when using JPQL.Next specific features (e.g. window functions, values clauses, set operations, common table expressions).
This module aims to be an API that is as close to the original QueryDSL API as possible.
Where features did not exist in querydsl-jpa, but did exist in querydsl-sql, we stayed as close to the existing SQL implementation as possible.
This includes the implementation for window functions, common table expressions (CTEs) and union queries which was the basis for all types of set expressions.
Staying close to QueryDSL’s API however, also means that the API is not as fluent as Blaze Persistence users are accustomed to. This means that creating common table expressions or complex set operations may lead to superfluous code.
As outlined in the setup section you need the following dependencies for the integration:
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-querydsl-expressions</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-hibernate-5.4</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
The dependencies for other JPA providers or other versions can be found in the setup section.
21.1. Features
The QueryDSL integration aims to make the full feature set from Blaze Persistence Core available. This includes:
-
Common Table Expressoins (CTEs) and recursive CTEs
-
Subquery joins
-
Lateral joins
-
Values clauses
-
Window functions and named windows
-
GROUP_CONCATsupport -
Utility methods for date/time
-
Set operations (
UNION,UNION ALL,INTERSECT,INTERSECT ALL,EXCEPTandEXCEPT ALL) -
LEAST/GREATESTfunctions -
Result set pagination
21.2. Examples
The following chapters demonstrate some of the possibilities of the blaze-persistence-integration-querydsl-expressions integration.
Assume we have the following entity:
@Entity
public class Cat {
@Id
private Long id;
private String name;
private Integer age;
}
21.2.1. Simple query
A very simple query might look like this:
QCat cat = QCat.cat;
BlazeJPAQuery<Tuple> query = new BlazeJPAQuery<Tuple>(entityManager, criteriaBuilderFactory).from(cat)
.select(cat.name.as("name"), cat.name.substring(2))
.where(cat.name.length().gt(1));
List<Tuple> fetch = query.fetch();
21.2.2. Regular association joins
QAuthor = QAuthor.author;
QBook book = QBook.book;
Map<Author, List<Book>> booksByAuthor = new BlazeJPAQuery<>(entityManager, criteriaBuilderFactory)
.from(author)
.innerJoin(author.books, book)
.transform(GroupBy.groupBy(author).as(GroupBy.list(book)));
21.2.3. Regular entity joins
QAuthor otherAuthor = new QAuthor("otherAuthor");
QBook otherBook = new QBook("otherBook");
Map<Author, List<Book>> booksByAuthor = new BlazeJPAQuery<Tuple>(entityManager, criteriaBuilderFactory)
.from(otherAuthor)
.innerJoin(otherBook).on(otherBook.author.eq(otherAuthor))
.transform(GroupBy.groupBy(otherAuthor).as(GroupBy.list(otherBook)));
21.3. Managed type value clause
Cat theCat = new Cat();
theCat.id = 1337L;
theCat.name = "Fluffy";
List<Book> fetch = new BlazeJPAQuery<Book>(entityManager, criteriaBuilderFactory)
.fromValues(QCat.cat, Collections.singleton(theCat))
.select(QCat.cat)
.fetch();
21.4. Managed attribute value clause
StringPath catName = Expressions.stringPath("catName");
List<String> fetch = new BlazeJPAQuery<>(entityManager, cbf)
.fromValues(QCat.cat.name, catName, Collections.singleton("Fluffy"))
.select(catName)
.fetch();
21.4.1. Window functions
Window functions are available through the various static utility methods in JPQLNextExpressions.
For convenience, its recommended to add a star-import to com.blazebit.persistence.querydsl.JPQLNextExpressions.*.
QCat cat = QCat.cat;
BlazeJPAQuery<Tuple> query = new BlazeJPAQuery<Tuple>(entityManager, criteriaBuilderFactory).from(cat)
.select(cat.name, JPQLNextExpressions.rowNumber(), JPQLNextExpressions.lastValue(cat.name).over().partitionBy(cat.id));
List<Tuple> fetch = query.fetch();
21.4.2. Named window functions
QCat cat = QCat.cat;
NamedWindow myWindow = new NamedWindow("myWindow").partitionBy(cat.id);
BlazeJPAQuery<Tuple> query = new BlazeJPAQuery<Tuple>(entityManager, criteriaBuilderFactory).from(cat)
.select(cat.name, JPQLNextExpressions.rowNumber().over(myWindow), JPQLNextExpressions.lastValue(cat.name).over(myWindow));
List<Tuple> fetch = query.fetch();
21.4.3. Common Table Expressions
First declare your CTE entity:
@CTE
@Entity
public class IdHolderCte {
@Id
Long id;
String name;
}
Next, it can be queried as such:
List<Long> fetch = new BlazeJPAQuery<TestEntity>(entityManager, cbf)
.with(idHolderCte, JPQLNextExpressions.select(
JPQLNextExpressions.bind(idHolderCte.id, book.id),
JPQLNextExpressions.bind(idHolderCte.name, book.name)).from(book))
.select(idHolderCte.id).from(idHolderCte)
.fetch();
Alternatively, you can use the convenience bind method on BlazeJPAQuery:
List<Long> fetch = new BlazeJPAQuery<TestEntity>(entityManager, cbf)
.with(idHolderCte, new BlazeJPAQuery()
.bind(idHolderCte.id, book.id),
.bind(idHolderCte.name, book.name)).from(book))
.select(idHolderCte.id).from(idHolderCte)
.fetch();
Recursive CTEs
Set operations are also allowed in CTEs, and through set operations it is also possible to write recursive CTEs.
QCatCte parentCat = new QCatCte("parentCat");
List<CatCte> result = new BlazeJPAQuery<CatCte>(entityManager, criteriaBuilderFactory)
.withRecursive(QCatCte.catCte, new BlazeJPAQuery().unionAll(
new BlazeJPAQuery()
.from(QCat.cat)
.bind(QCatCte.catCte.id, QCat.cat.id)
.bind(QCatCte.catCte.ancestor, QCat.cat.ancestor)
.where(QCat.cat.id.eq(someCatId)),
new BlazeJPAQuery()
.from(QCat.cat)
.from(QCatCte.catCte, parentCat)
.bind(QCatCte.catCte.id, QCat.cat.id)
.bind(QCatCte.catCte.ancestor, QCat.cat.ancestor)
.where(QCat.cat.id.eq(parentCat.ancestor.id)))
)
.select(QCatCte.catCte)
.from(QCatCte.catCte)
.fetch();
21.4.4. Subquery joins
A limitation of JPQL frequently stumbled opon, is that subqueries cannot be joined. With Blaze Persistence however, this is perfectly possible:
QRecursiveEntity recursiveEntity = new QRecursiveEntity("t");
List<RecursiveEntity> fetch = new BlazeJPAQuery<>(entityManager, cbf)
.select(recursiveEntity)
.from(select(recursiveEntity)
.from(recursiveEntity)
.where(recursiveEntity.parent.name.eq("root1"))
.orderBy(recursiveEntity.name.asc())
.limit(1L), recursiveEntity)
.fetch();
Subquery joins utilize Common Table Expressions. Therefore also CTE types are allowed for subquery results. In that case, the CTE attributes should be bound in a similar fashion as shown in the CTE examples. Whenever the subquery projects an entity path that is also a join target, all owned attributes will be bound implicitly if no different bindings are provided.
21.4.5. Lateral joins
Subquery joins may access outer query variables if a lateral join is used.
QRecursiveEntity t = new QRecursiveEntity("t");
QRecursiveEntity subT = new QRecursiveEntity("subT");
QRecursiveEntity subT2 = new QRecursiveEntity("subT2");
List<Tuple> fetch = new BlazeJPAQuery<>(entityManager, cbf)
.select(t, subT2)
.from(t)
.leftJoin(select(subT).from(t.children, subT).orderBy(subT.id.asc()).limit(1), subT2)
.lateral()
.fetch();