Preface
JPA applications that use the entity model in every layer often suffer from the infamous LazyInitializationException or N + 1 queries issues.
This is mainly due to the use of a too general model for a use case and is often solved by making use of a specialized DTO and adapting queries to that structure.
The use of DTOs normally requires adapting many parts of an application and a lot of boilerplate code which is why people tend to do the wrong thing like making use of
the open session in view anti-pattern. Apart from lazy loading issues, also the performance suffers due to selecting unnecessary data that a UI is never displaying.
Blaze Persistence entity views try to solve these and many more problems a developer faces when having to implement efficient model mapping in a JPA application.
It allows to define DTOs as interfaces and provides the mappings to the JPA model via annotations. It favors convention-over-configuration by providing smart defaults that allow to omit most mappings.
By applying DTOs to a query builder through the ObjectBuilder extension point it is possible to separate query logic from the projections while still enjoying high performance queries.
System requirements
Blaze Persistence entity views require at least Java 1.7 and at least a JPA 2.0 implementation. The entity view module depends on the core module and requires the use of the same versions for both modules.
1. Getting started
This is a step-by-step introduction about how to get started with the entity view module of Blaze Persistence.
The entity view module requires the Blaze Persistence core so if you have not read the getting started guide for the core yet, you might want to start your reading there.
1.1. Setup
As already described in the core module setup, every module depends on the core module. So if you haven’t setup the core module dependencies yet, get back here when you did.
To make use of the entity view module, you require all artifacts from the entity-view directory of the distribution. CDI and Spring users can find integrations in integration/entity-view that give a good foundation for configuring for these environments.
Spring Data users can find a special integration in integration/entity-view which is described in more detail in a later chapter. This integration depends on all artifacts of the jpa-criteria module.
1.1.1. Maven setup
We recommend you introduce a version property for Blaze Persistence which can be used for all artifacts.
<properties>
<blaze-persistence.version>1.2.1</blaze-persistence.version>
</properties>
The required dependencies for the entity view module are
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-entity-view-api</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-entity-view-impl</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Depending on the environment, there are some integrations that help you with configuration
CDI integration
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-entity-view-cdi</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
Spring integration
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-entity-view-spring</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
Spring Data integration
When you work with Spring Data you can additionally have first class integration by using the following dependencies.
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-spring-data-2.x</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
If you still work with Spring Data 1.x you will have to use a different integration as Spring Data 2.x changed quite a bit.
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-spring-data-1.x</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
| The Spring Data integration depends on the jpa-criteria module |
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-jpa-criteria-api</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-jpa-criteria-impl</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
If a JPA provider that does not implement the JPA 2.1 specification like Hibernate 4.2 or OpenJPA is used, the following compatibility dependency is also required.
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-jpa-criteria-jpa-2-compatibility</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
1.2. Environments
The entity view module of Blaze Persistence is usable in Java EE, Spring as well as in Java SE environments.
1.2.1. Java SE
In a Java SE environment the EntityViewConfiguration as well as the EntityViewManager must
be created manually as follows:
EntityViewConfiguration cfg = EntityViews.createDefaultConfiguration(); cfg.addEntityView(EntityView1.class); // Add some more cfg.addEntityView(EntityViewn.class); EntityViewManager evm = cfg.createEntityViewManager(criteriaBuilderFactory);
As you can see, the EntityViewConfiguration is used to register all the entity
view classes that you want to make accessible within the an EntityViewManager.
You may create multiple EntityViewManager instances with potentially different
configurations.
|
1.2.2. Java EE
For usage with CDI the integration module blaze-persistence-integration-entity-view-cdi provides a CDI
extension which takes over the task of creating and providing an EntityViewConfiguration
from which an EntityViewManager can be created like following example shows.
@Singleton // from javax.ejb
@Startup // from javax.ejb
public class EntityViewManagerProducer {
// inject the configuration provided by the cdi integration
@Inject
private EntityViewConfiguration config;
// inject the criteria builder factory which will be used along with the entity view manager
@Inject
private CriteriaBuilderFactory criteriaBuilderFactory;
private EntityViewManager evm;
@PostConstruct
public void init() {
// do some configuration
evm = config.createEntityViewManager(criteriaBuilderFactory);
}
@Produces
@ApplicationScoped
public EntityViewManager createEntityViewManager() {
return evm;
}
}
The CDI extension collects all the entity views classes and provides a producer for the pre-configured EntityViewConfiguration.
1.2.3. CDI
If EJBs aren’t available, the EntityViewManager can also be configured in a CDI 1.1 specific way similar to the Java EE way.
@ApplicationScoped
public class EntityViewManagerProducer {
// inject the configuration provided by the cdi integration
@Inject
private EntityViewConfiguration config;
// inject the criteria builder factory which will be used along with the entity view manager
@Inject
private CriteriaBuilderFactory criteriaBuilderFactory;
private volatile EntityViewManager evm;
public void init(@Observes @Initialized(ApplicationScoped.class) Object init) {
// do some configuration
evm = config.createEntityViewManager(criteriaBuilderFactory);
}
@Produces
@ApplicationScoped
public EntityViewManager createEntityViewManager() {
return evm;
}
}
1.2.4. Spring
You have to enable the Spring entity-views integration via annotation based config or XML based config and you can also mix those two types of configuration:
Annotation Config
@Configuration
@EnableEntityViews("my.entityviews.base.package")
public class AppConfig {
}
XML Config
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:ev="http://persistence.blazebit.com/view/spring"
xsi:schemaLocation="
http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans-4.3.xsd
http://persistence.blazebit.com/view/spring http://persistence.blazebit.com/view/spring/spring-entity-views-1.2.xsd">
<ev:entity-views base-package="my.entityviews.base.package"/>
</beans>
The Spring integration collects all the entity views classes in the specified base-package and provides the pre-configured EntityViewConfiguration for injection.
This configuration is then used to create a EntityViewManager which should be provided as bean.
@Configuration
public class BlazePersistenceConfiguration {
@Bean
@Scope(ConfigurableBeanFactory.SCOPE_SINGLETON)
@Lazy(false)
// inject the criteria builder factory which will be used along with the entity view manager
public EntityViewManager createEntityViewManager(CriteriaBuilderFactory cbf, EntityViewConfiguration entityViewConfiguration) {
return entityViewConfiguration.createEntityViewManager(cbf);
}
}
1.3. Supported Java runtimes
The entity view module like all other modules generally follows what has already been stated in the core moduel documentation.
Automatic module names for modules.
| Module | Automatic module name |
|---|---|
Entity View API |
com.blazebit.persistence.view |
Entity View Impl |
com.blazebit.persistence.view.impl |
1.4. Supported environments/libraries
Generally, we support the usage in Java EE 6+ or Spring 4+ applications.
The following table outlines the supported library versions for the integrations.
| Module | Automatic module name | Minimum version | Supported versions |
|---|---|---|---|
CDI integration |
com.blazebit.persistence.integration.view.cdi |
CDI 1.0 |
1.0, 1.1, 1.2 |
Spring integration |
com.blazebit.persistence.integration.view.spring |
Spring 4.3 |
4.3, 5.0 |
DeltaSpike Data integration |
com.blazebit.persistence.integration.deltaspike.data |
DeltaSpike 1.7 |
1.7, 1.8 |
Spring Data integration |
com.blazebit.persistence.integration.spring.data |
Spring Data 1.11 |
1.11, 2.0 |
Spring Data Rest integration |
com.blazebit.persistence.integration.spring.data.rest |
Spring Data 1.11, Spring MVC 4.3 |
Spring Data 1.11 + Spring MVC 4.3, Spring Data 2.0 + Spring MVC 5.0 |
1.5. First entity view query
This section is supposed to give you a first feeling of how to use entity views. For more detailed information, please see the subsequent chapters.
In the following we suppose cbf, em and evm to refer to an instance of CriteriaBuilderFactory,
JPA’s EntityManager and EntityViewManager, respectively.
Take a look at the environments chapter for how to obtain an EntityViewManager.
|
An entity view can be thought of as the ORM world’s dual to a database table view. It enables the user to query just a subset of an entity’s fields. This enables developers to only query what they actually need for their current use case, thereby reducing network traffic and improving performance.
Let’s start with a very simple example. Assume that in our application we want to display a list of the names of all the cats in our database. Using entity views we would first define a new view for this purpose:
@EntityView(Cat.class)
public interface CatNameView {
@IdMapping
public Long getId();
public String getName();
}
The usage of the CatNameView could look like this:
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class); CriteriaBuilder<CatNameView> catNameBuilder = evm.applySetting(EntityViewSetting.create(CatNameView.class), cb); List<CatNameView> catNameViews = catNameBuilder.getResultList();
Of course, you can apply further restrictions to your query by CriteriaBuilder means.
E.g. you could avoid duplicate names in the above example by calling groupBy() on the
CriteriaBuilder at any point after its creation.
By default the abstract getter methods in the view definition map to same named entity fields.
So the getName() getter in the above example actually triggers querying
of the name field. If we want to use a different name for the getter method we would
have to add an additional @Mapping annotation:
@EntityView(Cat.class)
public interface CatNameView {
@IdMapping
public Long getId();
@Mapping("name")
public String getCatName();
}
Of course, it is also possible to combine various views via inheritance.
@EntityView(Cat.class)
public interface CatKittens {
@IdMapping
public Long getId();
public List<Kitten> getKittens();
}
@EntityView(Cat.class)
public interface CatNameView {
@IdMapping
public Long getId();
@Mapping("name")
public String getCatName();
}
@EntityView(Cat.class)
public interface CombinedView extends CatKittens, CatNameView {
@Mapping("SIZE(kittens)")
public Integer getKittenSize();
}
| An entity view does not have to be an interface, it can be any class. |
Moreover you can see that it is possible to use whole expressions inside the @Mapping annotations.
The allowed expression will be covered in more detail in subsequent chapters.
Another useful feature are subviews which is illustrated in following example.
@EntityView(Landlord.class)
public interface LandlordView {
@IdMapping
public Long getId();
public String getName();
public Integer getAge();
@Mapping("ownedProperties")
public PropertyAddressView getHouses();
}
@EntityView(Property.class)
public interface PropertyAddressView {
@IdMapping
public Long getId();
public String getAddress();
}
The last feature we are going to cover here are filters and sorters in conjunction with EntityViewSetting which
allows the dynamic configuration of filters and sorters on your entity view and are
also usable together with pagination. This makes them ideal an ideal fit whenever you need to query data for display
in a filterable and/or sortable data table. Following example illustrates how this looks like:
@EntityView(Cat.class)
@ViewFilters({
@ViewFilter(name = "customFilter", value = FilteredDocument.CustomFilter.class)
})
public interface FilteredCatView {
@AttributeFilter(ContainsFilter.class)
public String getName();
public static class CustomFilter extends ViewFilterProvider {
@Override
public <T extends WhereBuilder<T>> T apply(T whereBuilder) {
return whereBuilder.where("doctor.name").like().expression("Julia%").noEscape();
}
}
}
In this example we once again define a view on our Cat entity and select the cat’s name only.
But in addition we applied a filter on the name attribute. In this case we chose the ContainsFilter, one
of the predefined filters. We also defined a custom filter where we check whether the cat’s doctor’s name
starts with the string Julia.
The next code snippet shows how we dynamically set the actual filter value by which the
query should filter and how we paginate the resulting query.
// Base setting
EntityViewSetting<FilteredCatView, PaginatedCriteriaBuilder<FilteredCatView>> setting =
EntityViewSetting.create(FilteredCatView.class, 0, 10);
// Query
CriteriaBuilder<Cat> cb = cbf.create(em, Cat.class);
setting.addAttributeFilter("name", "Kitty");
PaginatedCriteriaBuilder<FilteredCatView> paginatedCb = evm.applySetting(setting, cb);
PagedList<FilteredCatView> result = paginatedCb.getResultList();
2. Architecture
This is just a high level view for those that are interested about how Blaze Persistence entity view works.
2.1. Interfaces
A quick overview that presents the interfaces that are essential for users and how they are related.
Since entity views are mostly annotation driven and are about mapping attributes to entity attributes, there are not that many interfaces.
The two most important ones are the EntityViewManager and the EntityViewSetting.
A EntityViewManager is built once on startup during which it analyzes and validates the configured entity views.
It is responsible for building implementations for the interfaces and abstract classes from the metamodel and caching object builder instances for entity views.
The EntityViewSetting is a configuration that can be applied on a query builder through an EntityViewManager and contains information about
-
The entity view
-
Pagination
-
Filters and sorters
-
Parameters and properties
2.2. Core module integration
The entity view module builds on top of the ObjectBuilder integration point offered by query builders of the core module.
Every entity view is translated into a ObjectBuilder which is then applied on a query builder.
2.3. Object builder pipeline
During startup the metamodel is built which is then used for building an object builder pipeline.
For every entity view interface/class a ObjectBuilder template called ViewTypeObjectBuilderTemplate is created which is cached.
From these templates a normal ObjectBuilder is built that can be applied on any query builder. Depending on the features a entity view uses,
the resulting object builder might actually be a object builder pipeline i.e. it invokes multiple object builders in an ordered manner on tuples.
In general, a object builder for an entity view just takes in the tuple and passes it to the constructor of the entity view implementation.
As soon as subviews or collections are involved, it becomes a pipeline. The pipeline has two different forms, the abstract form represented by TupleTransformatorFactory and the concrete form TupleTransformator.
When a object builder is created from a template, the concrete form is created from the abstract one which might involve building object builders for subviews.
Every collection introduces a new transformation level i.e. elements of a collection must be materialized before the collection can be materialized.
So the result is processed from the leafs(i.e. the elements) upwards(i.e. a collection) until objects of the target entity view type are materialized.
2.4. Updatable entity views
Updatable entity views are still in flux and are not yet fully thought through, but here comes the essential idea.
Similar to the object builder pipeline, a EntityViewUpdater is composed of several possibly nested attribute flushers.
A EntityViewUpdater is built once and is responsible for flushing dirty attributes to the persistence context.
After flushing, attributes are considered to be non-dirty but they can become dirty again either through a change or a transaction rollback.
Dirty tracking is done either by remembering the initial state and comparing with changed state or not at all. Collections are tracked by using custom collection implementations that do action recording which is then replayed onto a collection of an entity reference.
3. Mappings
As already mentioned in the Getting started section, the entity view module builds up on the core module. Some of the basics like implicit joins and the basic expression structure should be known to understand all of the following mapping examples.
Entity views are to entities in ORM, what table views are to tables in an RDBMS. They represent projections on the entity model. In a sense you can say that entity views are DTOs 2.0 or DTOs done right.
One of the unique features of entity views is that it only imposes a structure and the projections, but the base query defines the data source. Blaze Persistence tried to reduce as much of the boilerplate as possible for defining the structure and the projections by employing a convention over configuration approach.
The result of these efforts is that entity views are defined as interfaces or abstract classes mostly containing just getter definitions that serve as attribute definitions. To declare that an interface or an abstract class as entity view, you have to annotate it and specify the entity class for which this entity view provides projections.
@EntityView(Cat.class)
interface CatView { ... }
So an entity view can be seen as a named wrapper for a bunch of attributes, where every attribute has some kind of mapping that is based on the attributes the entity type offers. An attribute is declared by defining a public abstract method in an entity view i.e. every abstract method is considered to be an attribute.
@EntityView(Cat.class)
interface CatView {
String getName();
}
Since every method of an interface is abstract and public, you can omit the abstract and public keywords.
In this simple example you can see that the CatView has an attribute named name. The implicit mapping for the attribute is the attribute name itself, so name.
This means that the entity view attribute name declared by the abstract method getName() is mapped to the entity attribute name.
| Since entity views and their mappings are validated during startup against the entity model, you should see any mapping related runtime errors and can be sure it works if it doesn’t fail to start |
One of the nice things about using interfaces is that you can have multiple inheritance. If you separate concerns in separate feature interfaces, you can effectively make use of multiple inheritance.
interface NameView {
String getName();
}
interface AgeView {
Long getAge();
}
@EntityView(Cat.class)
interface CatView extends NameView, AgeView {
}
In this example CatView has two attributes, name and age. Even though the interfaces are not entity views, they could have custom mappings.
3.1. Mapping types
So far, you have mostly seen basic attribute mappings in entity views, but there is actually support for far many mapping types.
-
Basic mappings - maps basic attributes from entities into entity views
-
Subview mappings - maps a *ToOne relation of an entity to an entity view
-
Flat view mappings - maps an embeddable of an entity to a flat entity view
-
Subquery mappings - maps the result of a subquery to a basic attribute into entity views
-
Parameter mappings - maps named query parameters into an entity view
-
Entity mappings - maps *ToOne or *ToMany relations of an entity as is into an entity view
-
Collection mappings - maps *ToMany relations of an entity into an entity view with support for basic, subview and embeddable types
-
Correlated mappings - correlates an entity type by some key and maps it or an attribute of it into an entity view as subview or basic type respectively
| In general we do not recommend to make extensive use of entity mappings as it defeats the purpose of entity views and can lead to lazy loading issues |
Apart from mapping attributes, it is also possible have a constructor and map parameters when using an abstract class. One of the biggest use cases for this is for doing further transformations on the data that can’t be pushed to the DBMS like e.g. money formatting.
3.2. Mapping defaults
As mentioned before, the entity view module implements a convention over configuration approach and thus has some smart defaults for mappings. Whenever an attribute(getter method) without a mapping annotation is encountered, a default mapping to the same named entity attribute will be created. If there is none, it will obviously report an error.
3.3. Id mappings
Id mappings declare that an attribute represents the identifier i.e. can be used to uniquely identify an entity view object.
The id mapping is declared by annotating the desired attribute with @IdMapping and optionally specifying the mapping path.
Having an id attribute allows an entity view to map collections, be mapped in collections and gives an entity view object a meaningful identity.
If an entity view has no id mapping, it is considered to be a flat view which probably only makes sense for scalar results or embedded objects.
| It is generally recommended to always declare an id mapping if possible. |
When an id mapping is present, the generated entity view implementation’s equals-hashCode implementation will be based on it. Otherwise it will consider all attributes in the equals-hashCode implementation.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
}
3.4. Flat view id mappings
A flat view id mapping is given when the type of the id attribute is a flat view type. This is the case when the view type has no id declared. It’s very similar to subview mappings and is mostly used when working with JPA embeddable types. Imagine the following model for illustration purposes.
@EntityView(Cat.class)
interface CatIdView {
String getName();
}
@EntityView(Cat.class)
interface CatView {
@IdMapping("this")
CatIdView getId();
}
This example already makes use of many concepts. It declares the CatIdView as flat view with a basic mapping and the CatView with a flat view id.
The mapping for the flat view id in CatView uses to the this expression extension to allow the flat view to be based on the same entity that is backing the CatView.
| Since flat view types will consider all attributes in the equals-hashCode implementation, the type shouldn’t contain unnecessary attributes if possible. |
3.5. Basic mappings
A basic mapping is declared by annotating the desired attribute with @Mapping and specifying the mapping expression.
An attribute that has no mapping annotations is only considered to have a basic mapping if it is of a basic type like e.g. Integer. Without a mapping annotation, the default mapping rules apply.
In general, every non-collection and non-managed type is considered to be basic. Managed types are JPA managed types and entity view types.
Although most example only use path expressions for the mapping, it is actually allowed to use any scalar expression that JPQL or Blaze Persistence allows.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
@Mapping("UPPER(name)")
String getUpperName();
}
As you might expect, the expression UPPER(name) will upper-case the name, so getUpperName() will return the upper-cased name.
Applying such an entity view on a simple query builder will show what happens behind the scenes.
List<CatView> result = evm.applySetting(
EntityViewSetting.create(CatView.class),
cbf.create(em, Cat.class)
).getResultList();
SELECT cat.id, UPPER(cat.name) FROM Cat cat
The expression in the mapping ends up as select item in the query just as expected.
3.6. Subview mappings
Subview and embeddable view mappings are similar to basic mappings in the sense that the same rules apply, except for the allowed mappings.
Since these mappings get their data from objects of managed types, only path expressions are allowed for their mappings.
Path expressions can have arbitrary depth i.e. multiple de-references like relation.subRelation.otherRelation and path elements can be of the following types:
-
Simple path elements that refer to entity type attributes
-
TREATexpression likeTREAT(..).subRelation -
Qualified expression like
KEY(..).subRelation -
Array expression like
relation[:param].subRelation
A subview mapping is given when the type of the attribute is a entity view type.
Since a entity view is always declared for a specific entity type, the target type of the subview mapping and the entity view’s entity type must be compatible.
This means that you could apply a AnimalView to a Cat if it extends Animal but can’t apply a PersonView since it’s not compatible i.e. Cat is not a subtype of Person.
@EntityView(Person.class)
interface PersonView {
@IdMapping
Long getId();
String getName();
}
@EntityView(Animal.class)
interface AnimalView {
@IdMapping
Long getId();
String getName();
}
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
AnimalView getFather();
}
As you might imagine, the CatView will additionally select attributes of the father relation since they are requested by the AnimalView.
In order to understand the following generated query, you should know what an implicit join does and how entity views make use of such implicit joins.
Behind the scenes, the entity views runtime will apply a select on the criteria builder for the expressions cat.id, father.id and father.name.
The expression father.name accesses an entity attribute is only accessible when actually joining the relation. This is why an implicit/default join is generated for the father relation.
SELECT cat.id, father_1.id, father_1.name FROM Cat cat LEFT JOIN cat.father father_1
Since the father relation is optional or nullable, a (default) left join is created due to the rules of model awareness in implicit joins.
This is a perfect fit for entity views as the subview object will be simply null if a cat has no father. If the implicit join worked like JPQL defines it, an inner join would have to be created.
An inner join would mean that cats without a father would get filtered out which is an undesirable effect since we only want a projection on top of a base query.
| Subviews can in turn have subviews again, so there is no limitation regarding the depth. The only requirement is that there is no cycle. |
3.6.1. Flat view mappings
A flat view mapping is given when the type of the attribute is a flat view type. This is the case when the entity view has no id declared. It’s very similar to subview mappings and is mostly used when working with JPA embeddable types.
Note that a flat view can be used like a normal view except when
-
it is used as view root i.e. the flat view is the entity view type used in
EntityViewSetting, -
it is embedded in a flat view which in turn is the view root i.e. the parent is a flat view that is used in
EntityViewSetting -
or it is used as subview for a non-indexed collection
then the flat view can’t have collection attributes with fetch strategy JOIN.
The reason is that the elements of the collection can’t be matched with the flat view as it has no identity it can use for matching.
Imagine the following model for illustration purposes.
@Embeddable
class Name {
String firstName;
String lastName;
}
@Entity
class Person {
@Id
@GeneratedValue
Long id;
@Embedded
Name name;
}
@EntityView(Name.class)
interface SimpleNameView {
String getFirstName();
}
@EntityView(Person.class)
interface PersonView {
@IdMapping
Long getId();
SimpleNameView getName();
}
Applying a PersonView would produce a query like
SELECT person.id, person.name.firstName FROM Person person
Such a flat view can also be used with the this expression which is similar to JPAs @Embedded.
| A limitation in Hibernate actually requires the use of flat entity views for mapping of element collections i.e. you can map the element collection 1:1 to the entity view. |
3.7. Subquery mappings
Subquery mappings allow to map scalar subqueries into entity views and are declared by annotating the desired attribute with @MappingSubquery and specifying a SubqueryProvider.
The following example should illustrate the usage:
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
@MappingSubquery(KittenCountSubqueryProvider.class)
Long getKittenCount();
class KittenCountSubqueryProvider implements SubqueryProvider {
@Override
public <T> T createSubquery(SubqueryInitiator<T> subqueryBuilder) {
return subqueryBuilder.from(Cat.class, "subCat")
.select("COUNT(*)")
.whereOr()
.where("subCat.father.id").eqExpression("OUTER(id)")
.where("subCat.mother.id").eqExpression("OUTER(id)")
.endOr()
.end();
}
}
}
This entity view already comes into contact with the core API for creating subqueries. It produces just what it defines, a subquery in the select clause.
SELECT
cat.id,
(
SELECT COUNT(*)
FROM Cat subCat
WHERE subCat.father.id = cat.id
OR subCat.mother.id = cat.id
)
FROM Cat cat
In the subquery provider before you saw the usage of OUTER which is gone in the final query.
This is because OUTER is a way to refer to attributes of the parent query root without having to refer to the concrete the query alias.
For more information on this check out the documentation of the OUTER function
The subquery was just used for illustration purposes and could be replaced with a basic mapping SIZE(kittens) which would also generate a more efficient query.
|
3.8. Parameter mappings
A parameter mapping is a convenient way to inject the values of query parameters or optional parameters into instances of an entity view.
Introducing a parameter mapping with @MappingParameter will introduce a fake select item. If a parameter is not used in a query, NULL will be injected into the entity view.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
@MappingParameter("myParam")
String getMyParam();
}
SELECT cat.id, NULLIF(1,1) FROM Cat cat
Parameter mappings are probably most useful in constructor mappings where they can be used for some transformation logic.
3.9. Entity mappings
Apart from having custom projections for entity or embeddable types through subviews, you can also map the JPA managed types directly.
You can use the @Mapping annotation if desired and map any path expression as singular or plural attribute(i.e. collection) with managed types.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
Cat getFather();
}
SELECT cat.id, father_1 FROM Cat cat LEFT JOIN cat.father father_1
Beware that when using managed types directly, you might run into lazy loading issues when accessing uninitialized/un-fetched properties of the entity.
You can however specify what properties should be fetched for such entity mappings by using the fetches configuration.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
@Mapping(fetches = "kittens")
Cat getFather();
}
This will fetch the kittens of the father.
SELECT cat.id, father_1 FROM Cat cat LEFT JOIN cat.father father_1 LEFT JOIN FETCH father_1.kittens kittens_1
3.10. Collection mappings
One of the most important features of the Blaze Persistence entity view module is the possibility to map collections. You can map collections defined in the entity model to collections in the entity view model in multiple ways.
3.10.1. Simple 1:1 collection mapping
The simplest possible mapping is a 1:1 mapping of e.g. a *ToMany collection.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
Set<Cat> getKittens();
}
This will simply join the kittens collection. During entity view construction the elements are collected and the result is flattened as expected.
SELECT cat.id, kittens_1 FROM Cat cat LEFT JOIN cat.kittens kittens_1
3.10.2. Subset basic collection mapping
Most of the time, only a subset of the properties of a relation is needed. In case only a single property is required,
the use of @Mapping to refer to the property within a collection can be used.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
@Mapping("kittens.name")
Set<String> getKittenNames();
}
This will join the kittens collection and only select their name.
SELECT cat.id, kittens_1.name FROM Cat cat LEFT JOIN cat.kittens kittens_1
3.10.3. Subview collection mapping
For the cases when multiple properties of a relation are needed, you can also use subviews.
@EntityView(Cat.class)
interface SimpleCatView {
@IdMapping
Long getId();
String getName();
}
@EntityView(Cat.class)
interface CatView extends SimpleCatView {
Set<SimpleCatView> getKittens();
}
Applying the CatView entity view will again join the kittens collection but this time select some more properties.
SELECT cat.id, kittens_1.id, kittens_1.name FROM Cat cat LEFT JOIN cat.kittens kittens_1
A subview within a collection can have subviews and collections of subviews again i.e. there is no limit to nesting.
3.10.4. Collection type re-mapping
Another nice feature of Blaze Persistence entity views is the ability to re-map a collection to a different collection type.
In the entity model one might for example choose to always use a java.util.Set for mapping collections,
but to be able to make use of the elements in a UI, you might require e.g. a java.util.List.
Although the kittens relation in the Cat entity uses a Set, you can map the kittens as List in the CatView.
As you might expect, the order of the elements will then depend on the order of the query result.
@EntityView(Cat.class)
interface SimpleCatView {
@IdMapping
Long getId();
String getName();
}
@EntityView(Cat.class)
interface CatView extends SimpleCatView {
List<SimpleCatView> getKittens();
}
By executing the query with a custom ORDER BY clause, the result order can be made deterministic.
List<CatView> result = entityViewManager.applySetting(
EntityViewSetting.create(CatView.class),
cb.create(Cat.class)
.orderByAsc("name")
.orderByAsc("kittens.name")
).getResultList();
SELECT cat.id, kittens_1.id, kittens_1.name
FROM Cat cat
LEFT JOIN cat.kittens kittens_1
ORDER BY cat.name ASC NULLS LAST,
kittens_1.name ASC NULLS LAST
| We do not recommend to rely on this behavior but instead make use of sorted collection mappings. |
3.10.5. Ordered collection mapping
Apart from changing the collection type to e.g. List it is also possible to get ordered results with sets.
By specifying ordered = true for the collection via the annotation @CollectionMapping you can force a set implementation that retains the insertion order like a LinkedHashSet.
@EntityView(Cat.class)
interface SimpleCatView {
@IdMapping
Long getId();
String getName();
}
@EntityView(Cat.class)
interface CatView extends SimpleCatView {
@CollectionMapping(ordered = true)
Set<SimpleCatView> getKittens();
}
The query doesn’t change, the only thing that does, is the implementation for the collection.
SELECT cat.id, kittens_1.id, kittens_1.name FROM Cat cat LEFT JOIN cat.kittens kittens_1
This oviously only makes sense when used along with an ORDER BY clause that orders the result set deterministically.
3.10.6. Sorted collection mapping
In addition to ordering, the following sorted collection types are supported
-
SortedSetandNavigableSet -
SortedMapandNavigableMap
You can specify the comparator for the collection via the annotation @CollectionMapping
@EntityView(Cat.class)
interface SimpleCatView {
@IdMapping
Long getId();
String getName();
static class DefaultComparator implements Comparator<SimpleCatView> {
@Override
public int compare(SimpleCatView o1, SimpleCatView o2) {
return String.CASE_INSENSITIVE_ORDER.compare(o1.getName(), o2.getName());
}
}
}
@EntityView(Cat.class)
interface CatView extends SimpleCatView {
@CollectionMapping(comparator = SimpleCatView.DefaultComparator.class)
SortedSet<SimpleCatView> getKittens();
}
This will ensure the correct ordering of the collection elements regardless of the query ordering. The query stays the same.
SELECT cat.id, kittens_1.id, kittens_1.name FROM Cat cat LEFT JOIN cat.kittens kittens_1
3.10.7. Indexed collection re-mapping
Mapping an indexed collection like a java.util.Map or java.util.List with an @OrderColumn can happen in multiple ways.
Let’s consider the following model.
@Entity
class Cat {
@Id
Long id;
@OneToMany
@OrderColumn
List<Cat> indexedKittens;
@ManyToMany
Map<Cat, Cat> kittensBestFriends;
}
@EntityView(Cat.class)
interface SimpleCatView {
@IdMapping
Long getId();
String getName();
}
- Indexed mapping
-
One way is to map the collections indexed again, i.e. a
Mapin the entity is mapped asMapin the entity view.
@EntityView(Cat.class)
interface CatView extends SimpleCatView {
List<SimpleCatView> getIndexedKittens();
Map<SimpleCatView, SimpleCatView> getKittensBestFriends(); (1)
}
| 1 | Careful when mapping the key to a subview. This is only supported in the latest JPA provider versions |
SELECT
cat.id,
INDEX(indexedKittens_1),
indexedKittens_1.id,
indexedKittens_1.name
KEY(kittensBestFriends_1).id,
KEY(kittensBestFriends_1).name,
kittensBestFriends_1.id,
kittensBestFriends_1.name
FROM Cat cat
LEFT JOIN cat.indexedKittens indexedKittens_1
LEFT JOIN cat.kittensBestFriends kittensBestFriends_1
- Map-Key only mapping
-
By using the qualified expression
KEY()you can map the keys of a map to a collection by using@Mapping
@EntityView(Cat.class)
interface CatView extends SimpleCatView {
@Mapping("KEY(kittensBestFriends)")
List<SimpleCatView> getKittens();
}
SELECT cat.id, KEY(kittensBestFriends_1).id, KEY(kittensBestFriends_1).name FROM Cat cat LEFT JOIN cat.kittensBestFriends kittensBestFriends_1
- Map-Value only mapping
-
Simply mapping a path expression for a
Mapto a normal collection, will result in only fetching the map values.
@EntityView(Cat.class)
interface CatView extends SimpleCatView {
@Mapping("kittensBestFriends")
List<SimpleCatView> getBestFriends();
}
SELECT cat.id, kittensBestFriends_1.id, kittensBestFriends_1.name FROM Cat cat LEFT JOIN cat.kittensBestFriends kittensBestFriends_1
- List-Value only mapping
-
Sometimes it might be required to ignore the index of an indexed
Listwhen mapping it to aListagain. To do so useignoreIndexon@CollectionMapping
@EntityView(Cat.class)
interface CatView extends SimpleCatView {
@Mapping("indexedKittens")
@CollectionMapping(ignoreIndex = true)
List<SimpleCatView> getKittens();
}
SELECT cat.id, indexedKittens_1.id, indexedKittens_1.name FROM Cat cat LEFT JOIN cat.indexedKittens indexedKittens_1
3.11. Singular collection type mappings
There are cases when the entity model defines a collection that is actually a singular entity attribute. This can happen when you use custom type implementations or JPA 2.1 attribute converters that produce collections.
A custom type or converter could map a DBMS array, json, xml or any other type to a collection. Since such an entity attribute is not a relation, it can only be a singular attribute.
By default Blaze Persistence entity views assume that an entity view attribute with a collection type is a plural attribute and the mapping refers to a plural entity attribute.
In order to be able to map such special singular attribute collections, you have to specifically use @MappingSingular.
@Entity
class Cat {
@Id
Long id;
@Basic
@Convert(converter = StringSetConverter.class)
Set<String> tags;
}
class StringSetConverter implements AttributeConverter<String, Set<String>> { ... }
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
@MappingSingular
Set<String> getTags();
}
Beware that you can’t re-map the collection type in this case although this might soon be possible. Also see #361 for further information.
The query will not generate a join but simply select the tags since it’s a singular attribute.
SELECT cat.id, cat.tags FROM Cat cat
3.12. Correlated mappings
In some entity models, not every relation between entities might be explicitly mapped. There are multiple possible reasons for that like e.g. not wanting to have explicit dependencies, to keep it simple etc. Apart from unmapped relations, there is sometimes the need to correlate entities based on some criteria with other entities which are more of an ad-hoc nature than explicit relations.
For these cases Blaze Persistence entity views introduces the concept of correlated mappings. These mappings can be used to connect entities through a custom criteria instead of through mapped entity relations. Correlated mappings can be used for any attribute type(basic, entity, subview, collection) although singular basic attributes can also be implemented as normal subqueries.
A correlation mapping is declared by annotating the desired attribute with @MappingCorrelated or @MappingCorrelatedSimple.
3.12.1. General correlated mappings
In order to map the correlation you need to specify some values
-
correlationBasis- An expression that maps to the so called correlation key -
correlator- TheCorrelationProviderto use for the correlation that introduces a so called correlated entity
By default, the correlated entity type is projected into the view. To map a specific property of the entity type, use the correlationResult attribute.
There is also the possibility to specify a fetch strategy that should be used for the correlation. By default, the SELECT strategy is used.
@EntityView(Cat.class)
public interface CatView {
@IdMapping
Long getId();
@MappingCorrelated(
correlationBasis = "age",
correlator = PersonAgeCorrelationProvider.class,
fetch = FetchStrategy.JOIN
)
Set<Person> getSameAgedPersons();
static class PersonAgeCorrelationProvider implements CorrelationProvider {
@Override
public void applyCorrelation(CorrelationBuilder builder, String correlationExpression) {
final String alias = builder.getCorrelationAlias(); (1)
builder.correlate(Person.class)
.on(alias + ".age").inExpressions(correlationExpression) (2)
.end();
}
}
}
| 1 | getCorrelationAlias() defines the alias for the correlated entity |
| 2 | correlationExpression represents the correlationBasis. We generally recommend to use the IN predicate through inExpressions() to be able to easily switch the fetch strategy |
Depending on the fetch strategy multiple other queries might be executed. Check out the different fetch strategies for further information.
In this case, the JOIN strategy was used, so the following query is generated.
SELECT cat.id, pers
FROM Cat cat
LEFT JOIN Person correlated_SameAgedPersons (1)
ON cat.age = correlated_SameAgedPersons.age (2)
| 1 | This makes use of the so called entity join feature which is only available in newer JPA provider versions |
| 2 | Note that the IN predicate which was used in the correlation provider was rewritten to a equality predicate |
Since entity joins are required for using the JOIN fetch strategy with correlation mappings you have to make sure your JPA provider supports them.
If your JPA provider does not support entity joins, you have to use a different fetch strategy instead.
| Entity joins are only supported in newer versions of JPA providers(Hibernate 5.1+, EclipseLink 2.4+, DataNucleus 5+) |
3.12.2. Simple correlated mappings
Since correlation providers are mostly static, Blaze Persistence also offers a way to define simple correlations in a declarative manner.
The @MappingCorrelatedSimple annotation only requires a few values
-
correlationBasis- An expression that maps to the so called correlation key -
correlated- The correlated entity type -
correlationExpression- The expression to use for correlating the correlated entity type to the view
@EntityView(Person.class)
public interface PersonView {
@IdMapping
Long getId();
String getName();
}
@EntityView(Cat.class)
public interface CatView {
@IdMapping
Long getId();
@MappingCorrelated(
correlationBasis = "age",
correlated = Person.class,
correlationExpression = "age IN correlationKey" (1)
fetch = FetchStrategy.JOIN
)
Set<PersonView> getSameAgedPersons(); (2)
}
| 1 | The expression uses the default name for the correlation key but could use a different name by specifying the attribute correlationKeyAlias |
| 2 | As you see here, it is obviously also possible to map subviews for correlated entity types |
Just like the general correlation, by default, the correlated entity type is projected into the view. To map a specific property of the entity type, use the correlationResult attribute.
There is also the possibility to specify a fetch strategy that should be used for the correlation. By default, the SELECT strategy is used.
3.13. Special method attributes
There are some special methods that can be declared abstract in an entity view type which have special runtime support.
3.13.1. EntityViewManager getter
An abstract method that returns EntityViewManager will not be considered to be an attribute.
Such a method has special runtime support as it will always return the associated EntityViewManager.
@EntityView(Person.class)
public abstract class PersonView {
@IdMapping
public abstract Long getId();
abstract EntityViewManager getEntityViewManager();
public void someMethod() {
// ... use getEntityViewManager()
}
}
This is especially useful for Updatable Entity Views when a method wants to create a new instance of a subview or get a reference to a subview.
3.14. Mapping expression extensions
Blaze Persistence entity views generally supports the full set of expressions that JPQL and Blaze Persistence core module supports, but in addition to that, also offers some expression extensions.
3.14.1. THIS
Similar to the this expression in Java, in a mapping expression within entity views the this expression can be used to refer to the entity type backing the entity view.
The expression can be used to implement embedded objects that are able to refer to the entity type of the entity view.
@EntityView(Cat.class)
interface EmbeddedCatView {
@IdMapping
Long getId();
String getName();
}
@EmbeddableEntityView(Cat.class)
interface ExternalInterfaceView {
@Mapping("name")
String getExternalName();
}
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
@Mapping("this")
EmbeddedCatView getEmbedded();
@Mapping("this")
ExternalInterfaceView getAdapter();
}
Both EmbeddedCatView and ExternalInterfaceView refer to the same Cat as their parent CatView.
The query looks as if the types were directly embedded into the entity view.
SELECT
cat.id,
cat.id,
cat.name,
cat.name
FROM Cat cat
3.14.2. OUTER
In Blaze Persistence core the OUTER function can be used to refer to the query root of a parent query from within a subquery.
This is still the same with Blaze Persistence entity views but might lead to unintuitive behavior when the subquery provider uses OUTER and is used in a subview.
The following example shows the unintuitive behavior.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
Set<KittenCatView> getKittens();
}
@EntityView(Cat.class)
interface KittenCatView {
@IdMapping
Long getId();
@MappingSubquery(KittenCountSubqueryProvider.class)
Long getKittenCount();
class KittenCountSubqueryProvider implements SubqueryProvider {
@Override
public <T> T createSubquery(SubqueryInitiator<T> subqueryBuilder) {
return subqueryBuilder.from(Cat.class, "subCat")
.select("COUNT(*)")
.whereOr()
.where("subCat.father.id").eqExpression("OUTER(id)")
.where("subCat.mother.id").eqExpression("OUTER(id)")
.endOr()
.end();
}
}
}
When applying the KittenCatView directly, everything works as expected.
SELECT
cat.id,
(
SELECT COUNT(*)
FROM Cat subCat
WHERE subCat.father.id = cat.id
OR subCat.mother.id = cat.id
)
FROM Cat cat
But when using KittenCatView as subview within CatView, it starts to break.
SELECT
cat.id,
kittens_1.id,
(
SELECT COUNT(*)
FROM Cat subCat
WHERE subCat.father.id = cat.id (1)
OR subCat.mother.id = cat.id
)
FROM Cat cat
LEFT JOIN cat.kittens kittens_1
| 1 | OUTER resolved to cat instead of kittens_1 |
The OUTER function doesn’t know about the entity view structure and will remain to refer to the query root.
In the future, a function EMBEDDING_VIEW will be introduced to be able to refer to the embedding entity view. Also see #367 for more information on this.
3.14.3. VIEW_ROOT
The VIEW_ROOT function can be used to refer to the relation for which the main entity view is applied.
Normally this will resolve to the query root, but beware that the entity view root might not always be the query root.
One of the main use cases for this function is when using correlated subview mappings.
| For further information on applying a different entity view root take a look into the querying chapter. |
The VIEW_ROOT function can be used in a correlation provider to additionally refer to a view root.
@EntityView(Cat.class)
public interface CatView {
@IdMapping
Long getId();
@MappingCorrelated(
correlationBasis = "age",
correlator = CatAgeCorrelationProvider.class
)
Set<Cat> getSameAgedCats();
static class CatAgeCorrelationProvider implements CorrelationProvider {
@Override
public void applyCorrelation(CorrelationBuilder builder, String correlationExpression) {
final String correlatedCat = builder.getCorrelationAlias();
builder.correlate(Cat.class)
.on(correlatedCat + ".age").inExpressions(correlationExpression)
.on(correlatedCat + ".id").notInExpressions("VIEW_ROOT(id)") (1)
.end();
}
}
}
| 1 | We generally recommend to use the IN predicate through inExpressions() or notInExpressions() to be able to easily switch the fetch strategy |
The VIEW_ROOT function is usable with every fetch strategy. In case of the JOIN fetch strategy the result is just as expected.
SELECT cat.id, correlatedCat
FROM Cat cat
LEFT JOIN Cat correlatedCat
ON correlatedCat.age = cat.age
AND correlatedCat.id <> cat.id (1)
| 1 | Again, the IN predicate was rewritten to an equality predicate |
Make sure you understand the <<anchor-select-fetch-strategy-view-root,implication> of the VIEW_ROOT function when using the batched SELECT fetch strategy as this might affect performance.
|
3.15. Entity View constructor mapping
So far, all mapping examples used interfaces for entity views, but as outlined in the beginning, Blaze Persistence entity views also has support for abstract classes. There are multiple use cases for using abstract classes for entity views, but in general we recommend to use an interface as often as possible. The biggest advantage of using abstract classes is that you can have a custom constructor which can further apply transformations on data.
3.15.1. Abstract class Entity View with custom equals-hashCode
Abstract classes, contrary to interfaces, can define an implementation for the equals and hashCode methods which is normally generated for the runtime implementations of Entity Views. If you decide to have a custom implementation you have to fulfill the general requirement, that the equals and hashCode methods use
-
Only the attribute mapped with
@IdMappingif there is one -
Otherwise use all attributes of the Entity View
Not following these requirements could lead to unexpected results so it is generally best to rely on the default implementation. For every custom implementation that is detected during the bootstrap a warning message will be logged.
3.15.2. Map external data model with view constructor
One of those use cases for a view constructor is integrating with an existing external data model.
class CatRestDTO {
private final Long id;
private final String name;
public MyOldCatDTO(Long id, String name) {
this.id = id;
this.name = name;
}
public Long getId() {
return id;
}
public String getName() {
return name;
}
}
In general we recommend to use the entity view types directly instead of an external data model, because of the additional boilerplate code needed. Note that the creators of Blaze Persistence are not generally against external data models since it is reasonable to have them e.g. in API projects that shouldn’t expose a library dependency.
@EntityView(Cat.class)
public abstract class CatView extends CatRestDTO {
public CatView(
@Mapping("id") Long id,
@Mapping("name") String name
) {
super(id, name);
}
}
Now you can use the CatView for efficient querying but still have objects that are an instance of CatRestDTO and can thus be used like normal CatRestDTO instances.
To decouple the actual entity view CatView from the data access or service one normally uses method signatures like
interface CatDAO {
<T> List<T> findAll(Class<T> entityViewClass); (1)
<T> List<T> findAll(EntityViewSetting<T, CriteriaBuilder<T>> entityViewSetting); (2)
}
| 1 | Create the EntityViewSetting within the implementation |
| 2 | Supply a custom EntityViewSetting which can also have filters, sorts, optional parameters and pagination information |
By using one of these approaches you can have a projection independent implementation for CatDAO and let the consumer i.e. a REST endpoint decide about the representation.
3.15.3. Additional data transformation in view constructor
Another use case for view constructors is the transformation of data. Sometimes it is just easier to do the transformation in Java code instead of through a JPQL expression, but then there are also times when there is no other way than doing it in Java code.
Let’s assume you want to have an attribute that contains different text based on the age.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
@Mapping("CASE WHEN age = 0 THEN 'newborn' WHEN age < 10 THEN 'child' WHEN age < 18 THEN 'teenager' ELSE 'adult' END")
String getText();
}
As you can see, the CASE WHEN expression can be used to implement that, but if the text is only static, there is no need to use that kind of expression.
You can instead just inject the age as constructor parameter and do the mapping to the text in Java code.
@EntityView(Cat.class)
public abstract class CatView {
private final String text;
public CatView(@Mapping("age") long age) {
if (age == 0) {
this.text = "newborn";
} else if (age < 10) {
this.text = "child";
} else if (age < 18) {
this.text = "teenager";
} else {
this.text = "adult";
}
}
@IdMapping
public abstract Long getId();
public String getText() {
return text;
}
}
Since that kind of mapping logic is normally externalized, Blaze Persistence entity views also offers a way to inject external services. You can provide services to entity views via optional parameters like
EntityViewSetting<CatView, CriteriaBuilder<CatView>> setting
= EntityViewSetting.create(CatView.class);
setting.addOptionalParameter("ageMapper", new AgeToTextMapper());
List<CatView> result = entityViewManager.applySetting(setting, cbf.create(em, Cat.class))
.getResultList();
The services, or optional parameters in general can be consumed either as attributes or as constructor parameters with @MappingParameter.
If the parameter is not supplied, null is injected.
@EntityView(Cat.class)
public abstract class CatView {
private final String text;
public CatView(
@Mapping("age") long age,
@MappingParameter("ageMapper") AgeToTextMapper mapper
) {
this.text = ageMapper.map(age);
}
@IdMapping
public abstract Long getId();
public String getText() {
return text;
}
}
3.15.4. Multiple named constructors
So far, the example always used no or just a single constructor, but it is actually possible to have multiple constructors.
Every constructor in an entity view must have a name defined via @ViewConstructor. The default name is init and is used for constructors that have no @ViewConstructor annotation.
@EntityView(Cat.class)
public abstract class CatView {
private final String text;
public CatView(
@Mapping("age") long age,
@MappingParameter("ageMapper") AgeToTextMapper mapper
) {
this.text = ageMapper.map(age);
}
@ViewConstructor("special")
public CatView(@Mapping("age") long age) {
this.text = age > 80 ? "oldy" : "normal";
}
@IdMapping
public abstract Long getId();
public String getText() {
return text;
}
}
The constructor name can be chosen when constructing a EntityViewSetting via create().
EntityViewSetting.create(CatView.class, "special");
3.15.5. Using attribute getters in constructor
Since mapping constructor parameters can become very cumbersome and oftentimes you need a value not only in the constructor but also accessible directly via a getter, Blaze Persistence came up with a solution that allows you to use the getters of attributes in the constructor.
It might not be immediately obvious why this is a special thing. Since entity views are declared as abstract classes you can imagine that the runtime has to actually create concrete classes.
These concrete classes normally initialize fields after calling the super constructor, thus making it impossible for the super constructor to actually retrieve values by using the attribute getters.
The JVM enforces that fields can only be accessed after the super constructor has been called, so normally there is no way that the getter implementations that serve the fields can return non-null values in the super constructor.
Fortunately, Blaze Persistence entity views found a way around this limitation of the JVM by making use of the infamous sun.misc.Unsafe to define a class that would normally fail bytecode verification.
The trick is, that the implementations that are generated will set the fields before calling the super constructor thus making the values available to the super constructor.
By default, all abstract classes will be defined through sun.misc.Unsafe.
If you don’t want that behavior and instead want bytecode verifiable implementations to be generated, you can always disable this strategy by using a configuration property.
@EntityView(Cat.class)
public abstract class CatView {
private final String text;
public CatView(@MappingParameter("ageMapper") AgeToTextMapper mapper) {
this.text = ageMapper.map(getAge()); (1)
}
@IdMapping
public abstract Long getId();
public abstract Long getAge();
public String getText() {
return text;
}
}
| 1 | If the unsafe proxy is used, getAge() will return the actual value, otherwise it will return null |
3.16. Inheritance mapping
Entity views can have an inheritance relationship to subtypes via an inheritance mapping. This relationship allows instances of an entity view subtype to be materialized when a selection predicate defined by an inheritance mapping is satisfied.
The inheritance feature for an entity view is activated by annotating @EntityViewInheritance on an entity view.
By default, all subtypes of the entity view are considered as inheritance subtypes and thus require a so called inheritance mapping.
An inheritance mapping is defined by annotating the subtype with @EntityViewInheritanceMapping and defining
a selection predicate that represents the condition on which decides the instantiation of that subtype. The predicate is a normal JPQL predicate expression
and can refer to all attributes of the mapped entity type.
Consider the following example
@EntityView(Cat.class)
@EntityViewInheritance
public interface BaseCatView {
String getName();
}
@EntityView(Cat.class)
@EntityViewInheritanceMapping("age < 18")
public interface YoungCatView extends BaseCatView {
@Mapping("mother.name")
String getMotherName();
}
@EntityView(Cat.class)
@EntityViewInheritanceMapping("age > 18")
public interface OldCatView extends BaseCatView {
@Mapping("kittens.name")
List<String> getKittenNames();
}
When querying for entity views of the type BaseCatView, the selection predicates age < 18 and age > 18 are merged into a type discriminator expression that returns a type index.
The type index refers to the entity view type into which a result should be materialized. The resulting JPQL query for such an entity view looks like the following
SELECT
CASE
WHEN age < 18 THEN 1
WHEN age > 18 THEN 2
ELSE 0
END,
cat.name,
mother_1.name,
kittens_1.name
FROM Cat cat
LEFT JOIN cat.mother mother_1
LEFT JOIN cat.kittens kittens_1
The type index 0 refers to the base type BaseCatView, hence instances of BaseCatView are materialized when the age of a result equals 18.
Since it might not be desirable to use all entity view subtypes for the inheritance relationship, it is possible to explicitly declare the subtypes in the @EntityViewInheritance annotation on the super type.
@EntityView(Cat.class)
@EntityViewInheritance({ YoungCatView.class })
public interface BaseCatView {
String getName();
}
This has the effect, that only BaseCatView or YoungCatView instances are materialized for a result.
3.17. Inheritance subview mapping
Similarly to specifying the entity view inheritance subtypes at the declaration site, i.e. BaseCatView, it is also possible to define subtypes at the use site, i.e. at the subview attribute.
By annotating the subview attribute with @MappingInheritance, it is possible to delimit and override the entity view subtype mappings that are considered for materialization from the result.
When using the @MappingInheritance annotation, it is required to list all desired subtypes via @MappingInheritanceSubtype annotations that can optionally override the inheritance mapping.
@EntityView(Person.class)
interface PersonView {
String getName();
@MappingInheritance({
@MappingInheritanceSubtype(mapping = "age <= 18", value = YoungCatView.class)
})
Set<BaseCatView> getCats();
}
@EntityView(Cat.class)
@EntityViewInheritance
public interface BaseCatView {
String getName();
}
@EntityView(Cat.class)
@EntityViewInheritanceMapping("age < 18")
public interface YoungCatView extends BaseCatView {
@Mapping("mother.name")
String getMotherName();
}
@EntityView(Cat.class)
@EntityViewInheritanceMapping("age > 18")
public interface OldCatView extends BaseCatView {
@Mapping("kittens.name")
List<String> getKittenNames();
}
When querying for PersonView, YoungCatView instances will be materialized if the cat’s age is lower or equal to 18 and otherwise instances of BaseCatView will be created.
By setting the annotation property onlySubtypes to true, instances of the base type BaseCatView aren’t materialized but a null is propagated.
Apart from skipping the base type, it is also possible to define the base type via @MappingInheritanceSubtype which allows to specify the inheritance mapping for the base type.
When no @MappingInheritanceSubtype elements are given, only the base type is materialized which can be used to disable the inheritance feature for an attribute.
|
It is illegal to set onlySubtypes to true and have an empty set of subtype mappings as that would always result in a null object.
|
3.17.1. Inheritance mapping with constructors
Entity view inheritance is not limited to interface types but can also be used with custom constructors.
If a view constructor is used, all entity view inheritance subtypes must have a view constructor with the same name.
In case of just a single constructor the @ViewConstructor does not have to be applied, as the name init is chosen by default as name.
@EntityView(Cat.class)
@EntityViewInheritance
public abstract class BaseCatView {
private final String parentName;
public BaseCatView(@Mapping("father.name") String parentName) {
this.parentName = parentName;
}
public abstract String getName();
}
@EntityView(Cat.class)
@EntityViewInheritanceMapping("age < 18")
public abstract class YoungCatView extends BaseCatView {
public YoungCatView(@Mapping("mother.name") String parentName) {
super(parentName);
}
@Mapping("mother.name")
public abstract String getMotherName();
}
@EntityView(Cat.class)
@EntityViewInheritanceMapping("age > 18")
public abstract class OldCatView extends BaseCatView {
public OldCatView() {
super("None");
}
@Mapping("kittens.name")
public abstract List<String> getKittenNames();
}
3.17.2. Inheritance mapping and JPA inheritance
The most obvious use case for entity view inheritance is mapping JPA entities that use an inheritance relationship.
Blaze Persistence supports this and also makes use of defaults for the inheritance mapping in case a entity view subtype uses an entity subtype in the @EntityView annotation.
@EntityView(Animal.class)
@EntityViewInheritance
public interface AnimalView {
String getName();
}
@EntityView(Cat.class)
@EntityViewInheritanceMapping
public interface CatView extends AnimalView {
String getKittyName();
}
@EntityView(Dog.class)
@EntityViewInheritanceMapping
public interface DogView extends AnimalView {
String getDoggyName();
}
The DogView uses the entity Dog and CatView the entity Cat which are both subtypes of Animal. In this case no inheritance mapping needs to be provided as Blaze Persistence will
generate a type constraint like TYPE(this) = Dog or TYPE(this) = Cat for the respective entity view subtypes DogView and CatView.
The resulting JPQL query when using AnimalView might look like the following
SELECT
CASE
WHEN TYPE(animal) = Cat THEN 1
WHEN TYPE(animal) = Dog THEN 2
ELSE 0
END,
animal.name,
TREAT(animal AS Cat).kittyName,
TREAT(animal AS Dog).doggyName
FROM Animal animal
As can be seen, the expressions for the access of the subtype properties rightfully make use of the TREAT operator.
An entity view could also be modelled flat i.e. not mirroring the entity inheritance relationship as entity views, but just put the desired properties on a single entity view type.
This can be done by making use of the TREAT operator and the this expression in the entity view mappings just as expected.
@EntityView(Animal.class)
@EntityViewInheritance
public interface MyAnimalView {
String getName();
@Mapping("TREAT(this AS Cat).kittyName")
String getKittyName();
@Mapping("TREAT(this AS Dog).doggyName")
String getDoggyName();
}
The generated query looks approximately like this
SELECT
animal.name,
TREAT(animal AS Cat).kittyName,
TREAT(animal AS Dog).doggyName
FROM Animal animal
and in case an animal is not of the treated type, a null value will be produced.
4. Fetch strategies
There are multiple different fetch strategies available for fetching. A fetch strategy can be applied to all kinds of mappings,
except for @MappingParameter and @MappingSubquery. These mappings will always use a JOIN strategy, i.e. the mapping will be put into the main query.
Any attribute in an entity view can be fetched separately by specifying a fetch strategy other than JOIN.
Every fetch strategy has some pros and cons but most of the time, the JOIN fetch strategy is a good choice.
Unless you can’t use the JOIN strategy because your JPA provider doesn’t support entity joins, you should always stick with it by default
and only change the strategy on a case by case basis.
4.1. Join fetch strategy
If your JPA provider supports entity joins, the JOIN strategy usually makes sense most of the time.
In case of correlated mappings it will result in a LEFT JOIN entity join of the correlated entity type.
The correlation expression created by the CorrelationProvider will be used in the ON condition.
For an example query that is generated by this strategy take a look at the correlation mappings chapter.
| Entity joins are only supported in newer versions of JPA providers(Hibernate 5.1+, EclipseLink 2.4+, DataNucleus 5+) |
4.2. Select fetch strategy
In general, the SELECT strategy will create a separate query for every attribute that uses it.
It will collect up to N distinct correlation basis values and then will execute that query to actually fetch the values for the attributes of the instances.
The parameter N is the batch size that can be configured at multiple levels.
Let’s look at an example that shows what happens
@EntityView(Cat.class)
public interface CatView {
@IdMapping
Long getId();
@BatchFetch(20) (1)
@MappingCorrelated(
correlationBasis = "age",
correlator = PersonAgeCorrelationProvider.class,
fetch = FetchStrategy.SELECT
)
Set<Person> getSameAgedPersons();
static class PersonAgeCorrelationProvider implements CorrelationProvider {
@Override
public void applyCorrelation(CorrelationBuilder builder, String correlationExpression) {
final String pers = builder.getCorrelationAlias();
builder.correlate(Person.class)
.on(pers + ".age").inExpressions(correlationExpression)
.end();
}
}
}
| 1 | Defines the batch size to use for loading |
When using this entity view, there are 2 queries that are generated.
SELECT cat.id, cat.age FROM Cat cat
The main query will fetch the correlationBasis and all the other attributes.
SELECT
TREAT_LONG(correlationParams.value),
correlated_SameAgedPersons
FROM Person correlated_SameAgedPersons,
VALUES ((?), (?), ...) correlationParams (1)
WHERE correlated_SameAgedPersons.age = TREAT_LONG(correlationParams.value)
| 1 | Actually there will be 20 question marks here because of the defined batch size of 20 |
The correlation query on the other hand will select the correlation value and the Person instances with an age matching any of the correlationParams values.
What you see here is the use of the VALUES clause for making multiple values available like a table for querying which is required when wanting to select the correlation value.
Selecting the actual correlation value via TREAT_LONG(correlationParams.value) along with the Person is necessary to be able to correlate the instances to the instance of the main query.
Depending on how many different values for age there are(cardinality), the correlation query might get executed multiple times.
In general, the runtime will collect up to batch size different values and then execute the correlation query for these values.
Results for a correlation value are cached during the querying to avoid querying the same correlation values multiple times in different batches.
This strategy works best when the cardinality of the correlationBasis is low i.e. there are only a few distinct values.
If the cardinality is high and the batch size is too low, this can lead to something similar as an N + 1 select known from lazy loading of collection elements.
You could theoretically choose a very big batch size to be able to handle more correlation values per query, but beware that there are limits to the efficiency of this approach.
Also beware that the amount of possible parameters might be limited by the DBMS. A value of 1000 for the batch size shouldn’t generally be a problem for a DBMS,
but before you configure such a high value, look into the subselect strategy which might be more appropriate for higher cardinalities.
4.2.1. Select fetch strategy with batching
Apart from using the @BatchFetch annotation, there are some other ways to define a batch size for fetching of an attribute.
Batch size default per entity view
A default batch size can be defined by setting the property com.blazebit.persistence.view.batch_size via EntityViewSetting.setProperty().
The value serves as default value and can be overridden on a per attribute basis.
Batch size per entity view attribute
The batch size for a specific attribute can be defined either by using the @BatchFetch annotation or by setting the com.blazebit.persistence.view.batch_size property suffixed with the attribute name.
In order to set the batch size for an attribute named someAttribute you have to set the property com.blazebit.persistence.view.batch_size.someAttribute via EntityViewSetting.setProperty().
The path to the attribute is based on the entity view which is queried and can also be deep i.e. someSubview.someAttribute.
4.2.2. Select fetch strategy with VIEW_ROOT
One possible problem with this strategy might arise when using the VIEW_ROOT function. The use of two correlation keys i.e. the view root and the correlation basis,
will affect the way the batching can be done. Before querying for the correlated date, the runtime will determine the cardinality of the view root ids and the correlation basis values.
After that, it will group the values with higher cardinality by the values with lower cardinality to be able to do efficient batching.
Let’s see what that means
@EntityView(Cat.class)
public interface CatView {
@IdMapping
Long getId();
Set<KittenCatView> getKittens();
}
@EntityView(Cat.class)
public interface KittenCatView {
@IdMapping
Long getId();
@BatchFetch(20)
@MappingCorrelated(
correlationBasis = "age",
correlator = CatAgeCorrelationProvider.class,
fetch = FetchStrategy.SELECT
)
Set<Cat> getSameAgedCats();
static class CatAgeCorrelationProvider implements CorrelationProvider {
@Override
public void applyCorrelation(CorrelationBuilder builder, String correlationExpression) {
final String correlatedCat = builder.getCorrelationAlias();
builder.correlate(Cat.class)
.on(correlatedCat + ".age").inExpressions(correlationExpression)
.on(correlatedCat + ".id").notInExpressions("VIEW_ROOT(id)")
.end();
}
}
}
In this example the batching might happen either for view roots or correlation basis values depending on the data. If the number of distinct view root ids is lower than the number of distinct correlation basis values, the correlation basis values are grouped by view root ids. The runtime will then execute a batched query for every view root id.
The good thing is, the runtime will adapt based on the data to minimize the number of queries, but still, if the cardinality is high, this can result in many queries being executed.
Batching expectation fine tuning
By default the runtime assumes that the VIEW_ROOT function is not used and generates a query that batches correlation basis values.
If this assumption fails because the VIEW_ROOT function is used and the batching is done based on view root ids, a new query has to be built.
The way the VIEW_ROOT function is implemented requires to invoke the CorrelationProvider again for building the new query.
To avoid this unnecessary rebuilding of the query, you can specify the batch expectation for all attributes by setting the property
com.blazebit.persistence.view.batch_correlation_values via EntityViewSetting.setProperty()
to false if batching is expected to be done on a view root id basis. The value serves as default value and can be overridden on a per attribute basis by suffixing the property name with the attribute name.
In order to set the batch expectation for an attribute named someAttribute you have to set the property com.blazebit.persistence.view.batch_correlation_values.someAttribute via EntityViewSetting.setProperty().
The path to the attribute is based on the entity view which is queried and can also be deep i.e. someSubview.someAttribute.
4.3. Subselect fetch strategy
The SUBSELECT strategy will create one query for every attribute that uses it and is especially efficient for bigger collections.
It creates a separate query based on the outer query and applies the CorrelationProvider to it.
Correlating subviews that contain collections when using firstResult/maxResults or applying an entity view on queries that use ORDER BY select aliases does not yet work. For more information also see #370
|
Let’s look at an example that shows what happens
@EntityView(Cat.class)
public interface CatView {
@IdMapping
Long getId();
@MappingCorrelated(
correlationBasis = "age",
correlator = PersonAgeCorrelationProvider.class,
correlationResult = "pers",
fetch = FetchStrategy.SUBSELECT
)
Set<Person> getSameAgedPersons();
static class PersonAgeCorrelationProvider implements CorrelationProvider {
@Override
public void applyCorrelation(CorrelationBuilder builder, String correlationExpression) {
final String pers = builder.getCorrelationAlias();
builder.correlate(Person.class)
.on(pers + ".age").inExpressions(correlationExpression)
.end();
}
}
}
When using this entity view, there are 2 queries that are generated.
SELECT cat.id, cat.age FROM Cat cat
The main query will fetch the correlationBasis and all the other attributes.
SELECT
cat.age,
correlated_SameAgedPersons
FROM Cat cat,
Person correlated_SameAgedPersons
WHERE correlated_SameAgedPersons.age = cat.age
The correlation query looks very similar since it’s based on the main query, but has a custom select clause. It selects the correlation key as well as the attributes for the target representation in the main entity view.
5. Filter and Sorter API
Apart from mapping projections, Blaze Persistence entity views also provides support for filtering and sorting on attribute-level. Implementing the filtering and sorting based on attributes allows to completely encapsulate the entity model behind an entity view. The structure of an entity view is driven by the consumer and basing the filtering and sorting aspects on that very same structure is only natural for a consumer.
The filter and sorter API is provided via com.blazebit.persistence.view.EntityViewSetting and allows filtering and sorting to be applied to entity views dynamically.
Dynamic in this context means that the filters and sorters can be added/enabled without the need to explicitly modify the entity view type itself
or the criteria builder which the entity view is based on.
Let’s consider the following data access method for an example
<V, C extends CriteriaBuilder<V>> getHungryCats(EntityViewSetting<V, C> settings) { ... }
It implements the basic business logic of how to obtain all hungry cats via a CriteriaBuilder from the database. The method supports
entity views to allow fetching only the fields which are needed for a concrete use cases. For example when displaying the
cats in a dropdown, their names might be sufficient but when displaying them in a table it might be desirable to include more details.
Likewise, one might want to retrieve the cats sorted by name or by age depending on the use case. Having to introduce 2 new methods for this purpose would be painful:
<V, C extends CriteriaBuilder<V>> getHungryCatsSortedByName(EntityViewSetting<V, C> settings); <V, C extends CriteriaBuilder<V>> getHungryCatsSortedByAge(EntityViewSetting<V, C> settings);
The above approach does not even account for different sort orders so in reality we might rather go for parameterizing the original method which is painful nevertheless:
<V, C extends CriteriaBuilder<V>> getHungryCats(EntityViewSetting<V, C> settings, String sortField, String sortOrder);
Instead it is possible to apply the sorting to the EntityViewSetting instance that is passed to
your data access layer:
settings.addAttributeSorter("name", com.blazebit.persistence.view.Sorters.ascending());
dataAccess.getHungryCats(settings);
| All attribute names specified using the filter or sorter API refer to the entity view attribute names rather than entity attribute names. |
5.1. Filter API
The filter API allows to enable and parameterize a filter for entity view attributes.
Entity view filters are defined by annotating respective entity view attributes with @AttributeFilter
or @AttributeFilters for multiple named filters.
In the annotation you can supply an optional filter name and a filter provider class which needs to extend
AttributeFilterProvider. An attribute filter’s name must be unique for the
attribute it is annotated on. The attribute filter without a filter name is the default filter. Only a single default attribute filter per attribute is allowed.
Example:
@EntityView(Cat.class)
public interface CatView {
@IdMapping
Integer getId();
@AttributeFilters({
AttributeFilter(ContainsIgnoreCaseFilter.class),
AttributeFilter(name = "containsCaseSensitive", value = ContainsFilter.class)
})
String getName();
}
Default attribute filters are enabled by calling addAttributeFilter(String attributeName, Object filterValue)
whereas named filters require calling addAttributeFilter(String attributeName, String filterName, Object filterValue).
The supplied object values are used by the filter provider to append the appropriate restrictions to the query builder.
EntityViewSetting<CatView, CriteriaBuilder<CatView>> setting = EntityViewSetting.create(CatView.class);
setting.addAttributeFilter("name", "kitty"); (1)
setting.addAttributeFilter("name", "containsCaseSensitive", "kitty"); (2)
| 1 | Enables the default filter ContainsIgnoreCaseFilter, so e.g. KITTY matches |
| 2 | Enables the named filter ContainsFilter, so e.g. KITTY doesn’t match |
| At most one attribute filter can be enabled per attribute. |
Blaze Persistence provides a number of built-in filter providers in the com.blazebit.persistence.view.filter package:
| Built-in filters | Supported filter value types |
|---|---|
GreaterOrEqualFilter |
Number, Date |
LessOrEqualFilter |
Number, Date |
GreaterThanFilter |
Number, Date |
LessThanFilter |
Number, Date |
EqualFilter |
Any |
StartsWithFilter |
String |
EndsWithFilter |
String |
ContainsFilter |
String |
StartsWithIgnoreCaseFilter |
String |
EndsWithIgnoreCaseFilter |
String |
ContainsIgnoreCaseFilter |
String |
NullFilter |
Boolean - |
It is also possible to filter by subview attributes. The following example illustrates this:
@EntityView(Cat.class)
public interface CatView {
@IdMapping
Integer getId();
ChildCatView getChild();
}
@EntityView(Cat.class)
public interface ChildCatView {
@IdMapping
Integer getId();
@AttributeFilter(LessOrEqualFilter.class)
Integer getAge();
}
CriteriaBuilderFactory cbf = ...;
EntityViewManager evm = ...;
EntityViewSetting<CatView, CriteriaBuilder<CatView>> setting = EntityViewSetting.create(CatView.class);
// by adding this filter, only cats with a child of age <= 10 will be selected
setting.addAttributeFilter("child.age", "10");
| Currently there is no support for collection filters like "has at least one" semantics. This is planned for a future version. When applying an attribute filter on a collection attribute or a subview attribute contained in a collection, the collection’s elements will currently be filtered. In the meantime, collection filters can be implemented by creating a custom attribute filter, applying restrictions directly on the entity view’s base query or by using a view filter. |
5.1.1. View filters
View filters allow filtering based on attributes of the view-backing entity as opposed to attribute filters which relate to entity view attributes.
For example, the following entity view uses a view filter to filter by the age entity attribute of the
Cat entity without this attribute being mapped in the entity view.
@EntityView(Cat.class)
@ViewFilter(name = "ageFilter", value = AgeFilterProvider.class)
public interface CatView {
@IdMapping
Integer getId();
String getName();
class AgeFilterProvider implements ViewFilterProvider {
@Override
public <T extends WhereBuilder<T>> T apply(T whereBuilder) {
return whereBuilder.where("age").gt(2L);
}
}
}
View filters need to be activated via the EntityViewSetting:
setting.addViewFilter("ageFilter");
5.1.2. Custom filters
If the built-in filters do not satisfy your requirements you are free to implement custom attribute filters by
extending AttributeFilterProvider with either one constructor accepting
-
Class<?>- The attribute type -
Object- The filter value -
Class<?>andObject- The attribute type and the filter value
Have a look at how a range filter could be implemented:
public class MyCustomFilter extends com.blazebit.persistence.view.AttributeFilterProvider {
private final Range range;
public EndsWithFilterImpl(Object value) {
this.value = (Range) value;
}
protected <T> T apply(RestrictionBuilder<T> restrictionBuilder) {
return restrictionBuilder.between(range.lower).and(range.upper);
}
public static class Range {
private final Number lower;
private final Number upper;
public Range(Number lower, Number upper) {
this.lower = lower;
this.upper = upper;
}
}
}
The filter implementation only uses the filter value in the constructor and assumes it to be of the Range type.
By accepting the attribute type, a string to object conversion for the filter value can be implemented.
5.2. Sorter API
The sorter API allows to sort entity views by their attributes.
A sorter can be applied for an attribute by invoking addAttributeSorter(String attributeName, Sorter sorter)
For an example of how to use the sorter API refer to the introductory example.
Blaze Persistence provides default sorters via the static methods in the Sorters class.
These methods allow to easily create any combination of ascending/descending and nulls-first/nulls-last sorter.
| At most one attribute sorter can be enabled per attribute. |
| Sorting by subquery attributes (see ??) is problematic for some DBs. |
| Currently, sorting by correlated attribute mappings (see ??) is also not fully supported. |
5.2.1. Custom sorter
If the built-in sorters do not satisfy your requirements you are free to create a custom sorter by
implementing the Sorter interface.
An example for a custom sorter might be a case insensitive sorter
public class MySorter implements com.blazebit.persistence.view.Sorter {
private final Sorter sorter;
private MySorter(Sorter sorter) {
this.sorter = sorter;
}
public static Sorter asc() {
return new MySorter(Sorters.ascending());
}
public static Sorter desc() {
return new MySorter(Sorters.descending());
}
public <T extends OrderByBuilder<T>> T apply(T sortable, String expression) {
return sorter.apply(sortable, "UPPER(" + expression + ")");
}
}
6. Querying and Pagination API
The main entry point to entity views is via the EntityViewSetting.create() API.
There are multiple different variants of the static create() method that allow to construct a EntityViewSetting.
create(Class<?> entityViewClass)-
Creates a simple entity view setting without pagination.
create(Class<T> entityViewClass, int firstResult, int maxResults)-
Creates a entity view setting that will apply pagination to a
CriteriaBuilderviapage(int firstResult, int maxResults)-
create(Class<T> entityViewClass, Object entityId, int maxRows)Creates a entity view setting that will apply pagination to aCriteriaBuilderviapage(Object entityId, int maxResults)
-
Every of the variants also has an overload that additionally accepts a viewConstructorName to be able to construct entity views via named constructors.
A EntityViewSetting essentially is configuration that can be applied to a CriteriaBuilder and contains the following aspects
-
Projection and DTO construction based on the entity view class
-
Entity view attribute based filtering
-
Entity view attribute based sorting
-
Query pagination
Allowing the actual data consumer i.e. the UI to specify these aspects is essential for efficient and easy to maintain data retrieval.
For a simple lookup by id there is also a convenience EntityViewManager.find() method available
that allows you to skip some of the CriteriaBuilder ceremony and that works analogous to how EntityManager.find() works, but with entity views.
6.1. Querying entity views
Code in the presentation layer is intended to create an EntityViewSetting via the create() API and pass the entity view setting to a data access method.
The data access method then applies the setting onto a CriteriaBuilder instance which it created to build a query.
We know that the current state of the EntityViewSetting API requires some verbose generics and we are going to fix that in 2.0. For further information also see #371
|
6.1.1. Normal CriteriaBuilder use
Depending on the need for pagination, an EntityViewSetting object is normally created like this
EntityViewSetting<CatView, CriteriaBuilder<CatView>> setting; // Use this if no pagination is required setting = EntityViewSetting.create(CatView.class); // Apply filters and sorters on setting List<CatView> list = catDataAccess.findAll(setting);
The implementation of the catDataAccess is quite simple. It creates a query with the CriteriaBuilder API as usual,
and finally applies the setting on the builder through the EntityViewManager.applySetting() method.
// Inject these somehow
CriteriaBuilderFactory criteriaBuilderFactory;
EntityViewManager entityViewManager;
public <V, Q extends CriteriaBuilder<V>> List<V> findAll(EntityViewSetting<V, Q> setting) {
CriteriaBuilder<Cat> criteriaBuilder = criteriaBuilderFactory.create(Cat.class);
// Apply business logic filters
criteriaBuilder.where("deleted").eq(false);
return entityViewManager.applySetting(setting, criteriaBuilder)
.getResultList();
}
6.1.2. Paginating entity view results
When data pagination is required, the firstResult and maxResults parameters are required to be specified when creating the EntityViewSetting object
EntityViewSetting<CatView, PaginatedCriteriaBuilder<CatView>> setting; // Paginate and show only the 10 first records by doing this setting = EntityViewSetting.create(CatView.class, 0, 10); // Apply filters and sorters on setting PagedList<CatView> list = catDataAccess.findAll(setting);
To actually be able to get the PagedList instead of a normal list, the following data access implementation is required
// Inject these somehow
CriteriaBuilderFactory criteriaBuilderFactory;
EntityViewManager entityViewManager;
public <V, Q extends PaginatedCriteriaBuilder<V>> PagedList<V> findAll(EntityViewSetting<V, Q> setting) {
CriteriaBuilder<Cat> criteriaBuilder = criteriaBuilderFactory.create(Cat.class);
// Apply business logic filters
criteriaBuilder.where("deleted").eq(false);
return entityViewManager.applySetting(setting, criteriaBuilder)
.getResultList();
}
The only difference to the former implementation is that this method uses the PaginatedCriteriaBuilder as upper bound for the type variable and a different return type.
By using a different type variable bound, the EntityViewManager.applySetting() will return an instance of PaginatedCriteriaBuilder. It’s getResultList() returns a PagedList instead of a normal list.
6.1.3. Keyset pagination with entity views
The EntityViewSetting API also comes with an integration with the keyset pagination feature.
A EntityViewSetting that serves for normal offset based pagination, can be additionally enriched with a KeysetPage
by invoking withKeysetPage(KeysetPage keysetPage).
Supplying a keyset page allows the runtime to choose keyset pagination instead of offset pagination based on the requested page and the supplied keyset page.
To be able to use keyset pagination, it is required to remember the last known keyset page.
When using a server side UI technology, this can be done very easily by simply saving the keyset page in the HTTP session.
With e.g. CDI the KeysetPage could simply be declared as field of a session-like scoped bean.
EntityViewSetting<CatView, PaginatedCriteriaBuilder<CatView>> setting; int maxResults = ...; // elements per page int firstResult = ...; // (pageNumber - 1) * elementsPerPage setting = EntityViewSetting.create(CatView.class, firstResult, maxResults); // Apply filters and sorters on setting setting.withKeysetPage(previousKeysetPage); PagedList<CatView> list = catDataAccess.findAll(setting); previousKeysetPage = list.getKeysetPage();
When using a more stateless approach like it is often the case with RESTful backends, the keyset page has to be serialized to the client and deserialized back when reading from the client.
Depending on your requirements, you can serialize the KeysetPage directly into e.g. a JSON object and should be able to deserialize it with the most common serialization libraries.
Another possible way to integrate this, is to generate URLs that contain the keyset in some custom format which should then be used by the client to navigate to the next or previous page.
Any of these approaches will require custom implementations of the KeysetPage and Keyset interfaces.
| We are working on a more easy integration with REST technologies. For further information see #373 |
6.1.4. Entity page navigation with entity views
Sometimes it is necessary to navigate to a specific entry with a specific id. When required to also display the entry in a paginated table marked as selected,
it is necessary to determine the page at which an entry with an id is located. This feature is implemented by the navigate to entity page feature
and can be used by creating an EntityViewSetting via create(Class<T> entityViewClass, Object entityId, int maxResults).
EntityViewSetting<CatView, PaginatedCriteriaBuilder<CatView>> setting; setting = EntityViewSetting.create(CatView.class, catId, maxResults); // Apply filters and sorters on setting // Use this to activate keyset pagination setting.withKeysetPage(null); PagedList<CatView> list = catDataAccess.findAll(setting); previousKeysetPage = list.getKeysetPage();
6.2. Optional parameters and configuration
Apart from the already presented aspects, a EntityViewSetting also contains so called optional parameters and configuration properties.
Optional parameters are set on a query if no value is set and also injected into entity views if requested by a parameter mapping
and are a very good integration point for dependency injection into entity views.
They can be set with the addOptionalParameter(String parameterName, Object value) method.
Configuration properties denoted as being always applicable can be set via setProperty(String propertyName, Object value)
and allow to override or fine tune configuration time behavior for a single query.
6.3. Applying entity views on specific relations
Up until now, an entity view setting has always been applied on the query root of a CriteriaBuilder which might not always be doable because of the way relations are mapped or how the query is done.
Fortunately, Blaze Persistence entity views also allow to apply a setting on a relation of the query root via
EntityViewManager.applySetting(EntityViewSetting setting, CriteriaBuilder criteriaBuilder, String entityViewRoot).
Let’s consider the following example.
@EntityView(Cat.class)
interface CatView {
@IdMapping
Long getId();
String getName();
}
Mapping this entity view on e.g. the father relation like
CriteriaBuilderFactory criteriaBuilderFactory = ...;
EntityViewManager entityViewManager = ...;
CriteriaBuilder<Cat> criteriaBuilder = criteriaBuilderFactory.create(Cat.class);
criteriaBuilder.where("father").isNotNull();
List<CatView> list = entityViewManager.applySetting(
EntityViewSetting.create(CatView.class),
criteriaBuilder,
"father"
);
This will map all fathers of cats to the CatView and roughly produce a query like the following
SELECT father_1.id, father_1.name FROM Cat cat LEFT JOIN cat.father father_1 WHERE father_1 IS NOT NULL
7. Updatable Entity Views
Updatable entity views represent DTOs for the write concern of an application. Updatable entity views are like a normal entity views, except that changes to attributes are tracked and can be inspected through the Change Model API or flushed to the backing data store.
Updatable entity views are also a lot like normal entities and can be thought of being similar to what is sometimes referred to as sub-entities. The main idea is to model use-case specific representations with a limited scope of attributes that can change. Usually, when using an entity type, many more attributes are exposed as being changable to the consumer of the type, although they might not even need to be updatable. Updatable entity views allows for perfect reuse of attribute declarations thanks to it’s use of interfaces but also brings a lot more to the table than using plain entities.
Apart from a concept for updating existing objects, Blaze Persistence also has a notion for creating new objects. With only JPA, a developer is often left with some open question like e.g. how to implement equals-hashCode for entities. Thanks to the first class notion of creatable entity views, this question and others can be easily answered as discussed below.
7.1. Update mapping
To declare an entity view as being updatable, it is required to additionally annotate it with @UpdatableEntityView.
By default an updatable entity view will do full updates i.e. always update all (owned) updatable attributes if at least one (owned) attribute is dirty.
Owned attributes are ones that belong the the backing entity type like e.g. basic typed attributes. Inverse attributes aren’t owned and are thus independent.
This behavior can be configured by setting the mode attribute on the @UpdatableEntityView:
-
PARTIAL- The mode will only flush values of actually changed attributes -
LAZY- The default, will flush all updatable values if at least one attribute is dirty -
FULL- Always flushes all updatable attributes, regardless of dirtyness
The flushing, by default, is done by executing JPQL DML statements, but can be configured to use entities instead by setting the strategy attribute on the @UpdatableEntityView:
-
QUERY- The default, will flush changes by executing JPQL DML statements. Falling back to entity flushing if necessary -
ENTITY- Will flush changes by loading the dirty entity graph and applying changes onto it
7.2. Create mapping
To declare an entity view as being creatable, it is required to additionally annotate it with @CreatableEntityView.
Note that updatable entity views for embeddable types are implicitly also creatable, yet the @CreatableEntityView annotation can still be applied for further configuration.
By default, a creatable entity view is validated against the backing model regarding it’s persistability i.e. it is checked if an instance could be successfully persisted regarding the non-null constraints of the entity model.
This allows to catch errors early that occur when adding new attributes to the entity model but forgetting to do so in the entity view.
The validation can be disabled by setting the validatePersistability attribute on the @CreatableEntityView to false
but can also be controlled in a fine grained manner by excluding specific entity attributes from the validation via the excludedEntityAttributes attribute.
The latter is useful for attributes that are known to be set on the entity model through entity listeners or entity view listeners.
Creatable views are converted to their context specific declaration type after persisting. This mean that if a creatable entity view is used as value for an attribute of an updatable entity view, the instance is replaced by an equivalent instance of the type that is declared for the attribute. Consider the following example model for illustration.
@UpdatableEntityView
@EntityView(Cat.class)
interface CatUpdateView {
@IdMapping
Long getId();
OwnerView getOwner();
void setOwner(OwnerView owner);
}
@EntityView(Person.class)
interface OwnerView {
@IdMapping
Long getId();
String getName();
}
@CreatableEntityView
@EntityView(Person.class)
interface OwnerCreateView extends OwnerView {
void setName(String name);
}
When flushing an instance of the type CatUpdateView that contains an owner of the creatable entity view type OwnerCreateView the following happens
-
A
Personentity is created with the defined properties -
The
Personentity is persisted viaEntityManager.persist() -
The generated identifier is set on the
OwnerCreateViewobject -
The
OwnerCreateViewobject is converted to the context specific declared typeOwnerView -
The
OwnerCreateViewobject is replaced by theOwnerViewobject
The same replacing happens for creatable entity views that are contained in a collection, thus developers don’t need to think about possible problems related to primary key based equals-hashCode implementations. Since the object is properly replaced, the assignment of a generated primary key, which would change the object regarding equals-hashCode, is not problematic. Still, the object can safely make use of the primary key based equals-hashCode implementation that is generated for all entity views by default.
7.3. API usage
An updatable as well as an creatable entity view is flushed by invoking EntityViewManager.update(EntityManager em, Object view)
and will flush changes according to the flush strategy and mode. Changes to collections are flushed depending on the collection mapping.
If the entity for which a collection is mapped owns the collection i.e. no use of mappedBy, the changes will be applied to an entity reference. For collections that are not owned by the containing entity i.e. use a mappedBy, changes will be applied by creating/updating/deleting the target entities.
Creatable entity views are constructed via EntityViewManager.create(Class type) and
always result in a persist when being flushed directly or through an updatable attribute having the CascadeType.PERSIST enabled.
Deletion of entities through view types works either by supplying an existing view object to EntityViewManager.remove(EntityManager em, Object view)
or by entity id via EntityViewManager.remove(EntityManager em, Class viewType, Object id).
7.4. Lifecycle and listeners
An entity view similar to a JPA entity also has something like a lifecycle, though within entity views, the states correspond to different entity view java types, rather than a transaction state. There are essentially 3 different kinds of entity views:
- new
-
An instance of a creatable entity view type(
@CreatableEntityView) that is created viaEntityViewManager.create(Class). After flushing of such an instance, the instance transitions to the updatable state if the entity view java type is also updatable(@UpdatableEntityView) otherwise to the read-only state. If it is used within an updatable view, it is then converted to the context specific type which replaces the creatable entity view instance. - read-only
-
A normal entity view without updatable or creatable configuration(
@UpdatableEntityView,@CreatableEntityView). - updatable
-
An entity view with updatable configuration(
@UpdatableEntityView).
| This is still in development, so not all features might be available yet. Also see https://github.com/Blazebit/blaze-persistence/issues/433 for more information. |
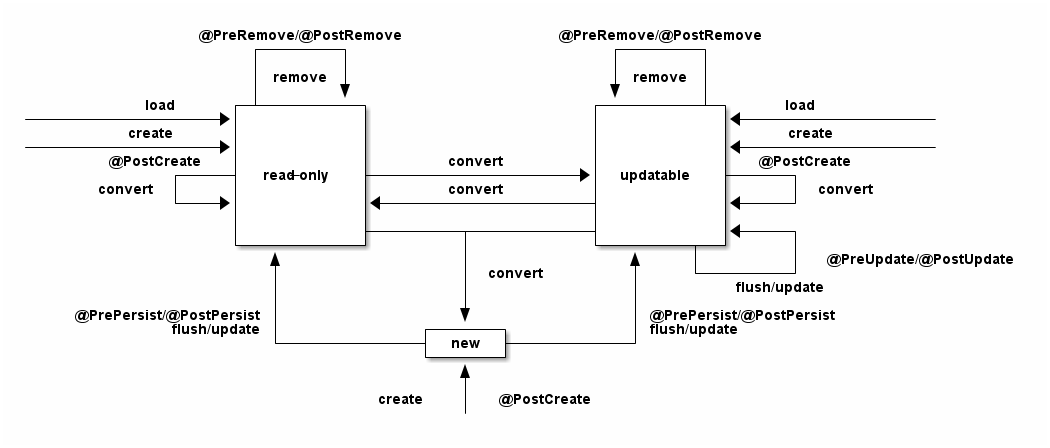
- load
-
An entity view is loaded by applying an
EntityViewSettingto aCriteriaBuilderwhich also happens implicitly when usingEntityViewManager.find(). Another way to load is to get a reference for an entity view viaEntityViewManager.getReference(). - remove
-
Removing is done explicitly by calling
EntityViewManager.remove()or implicitly when delete cascading or orphan removal is activated. - create
-
Creating of entity view instances is done by calling
EntityViewManager.create(). - flush/update
-
Flushing/Updating happens when invoking
EntityViewManager.update()orEntityViewManager.updateFull()as well as implicitly forCascadeType.UPDATEenabled attributes. - convert
-
Conversion happens when calling
EntityViewManager.convert()which implicitly happens for creatable entity views within a context after persisting.
For most of the operations it is possible to register a listener which is invoked before or after an operation. The listeners can react to specific events but in some cases also alter the state of the corresponding object.
A listener can be defined within an entity view class but within a class hierarchy there may only be one listener. If multiple listeners from e.g. super interfaces are inherited, the entity view type must declare a listener to disambiguate the situation. The listener then can invoke other listener methods or skip them.
Most listeners can be defined for a specific update or remove operation to react to change events in a particular manner for a specific use case,
but it is also possible to register listeners globally. The globally registered listeners can be used to implement cross cutting concerns like soft-deletion, auditing, etc.
Global listeners are registered via one of the EntityViewConfiguration.registerListener methods.
7.4.1. Post create listener
Within an entity view type a concrete method annotated with @PostCreate is considered to be a post create listener.
It may optionally define a parameter of the type EntityViewManager and must have a return type of void.
Such a listener is usually used for creatable entity view types to setup default values.
enum LifeState {
ALIVE,
DEAD;
}
@CreatableEntityView
@EntityView(Cat.class)
interface CatUpdateView {
@IdMapping
Long getId();
String getName();
void setName(String name);
LifeState getState();
void setState(LifeState state);
@PostCreate
default void init() {
setState(LifeState.ALIVE);
}
}
7.5. Attribute mappings
When an entity view has @UpdatableEntityView annotated, every attribute for which a setter method exists, is considered to be updatable.
For an attribute to be updatable means that changes done to the attribute of an entity view, can be flushed to the attribute they map to of an entity.
There is also a notion of mutable attributes which means that an attribute is updatable and/or the type of the attribute’s value might be mutable.
An unknown type is mutable by default and needs to be configured by registering a basic user type.
Entity view types are only considered being mutable if they are updatable(@UpdatableEntityView) or creatable(@CreatableEntityView).
Entity types are always considered to be mutable.
Singular attributes with an updatable flat view type are also considered updatable even without a setter method.
The mappings for updatable attributes must follow some rules
-
May not use complex expressions like arithmetic or functions
-
May not access elements or attributes of elements through a collection e.g.
kittens.name
The general understanding is that mappings should be bi-directional i.e. it should be possible to map a value back to a specific entity attribute.
To prevent an attribute being considered updatable, it can be annotated with @UpdatableMapping(updatable = false).
Sometimes, it’s also useful to annotate plural attributes i.e. collection attributes with @UpdatableMapping(updatable = true) when a setter is inappropriate.
Note that updatable and creatable entity view types require an id mapping to work properly, which is validated during the building of the metamodel. The getters and setters of abstract entity view classes may use the protected or default visibility setting which allows to encapsulate the access to these attributes properly.
7.5.1. Basic type mappings
Singular attributes with a basic type i.e. all types except entity view types, entity types or collection types, do not have a nested domain structure since they are basic. Values of such types usually change by setting a different value, though there are some mutable types as well. Basic types in general are handled by registered basic user types and define the necessary means to safely handle values of such types.
Values set for a basic type entity view attribute are only flushed to the entity attribute it refers to, if the entity view attribute is updatable.
This means that even if the type is mutable, a basic type attribute is never considered to be updatable as long as there is no setter or an explicit @UpdatableMapping(updatable = true) present.
If a type is immutable, an attribute with such a type obviously needs a setter to be considered updatable as there would otherwise be no way to change a value.
@UpdatableEntityView
@EntityView(Cat.class)
interface CatUpdateView {
@IdMapping
Long getId();
String getName();
void setName(String name);
}
Changes made via calls to e.g. setName() can be flushed later in a different persistence context.
The following shows a simple example
// Load the updatable entity view
CatUpdateView view = entityViewManager.find(entityManager, CatUpdateView.class, catId);
// Update the name of the view
view.setName("newName");
// Flush the changes to the persistence context
eventityViewManager.update(entityManager, view);
Depending on the configured flush strategy, this will either load the Cat entity and apply changes to it
or create an update query that set’s the updatable attributes.
UPDATE Cat cat SET cat.name = :name WHERE cat.id = :id
7.5.2. Subview mappings
Just like *ToOne relationships can be mapped in entities, it is possible to map these relationships as subviews. It is not required for such subview type to be updatable, in fact, it is encouraged to use a subview type that best fits the modeled use case.
In general, Blaze Persistence distinguishes between two concepts regarding updatability
-
Updatability of the relationship role i.e. the attribute
owneror more specifically theowner_idcolumn -
Updatability of the relation type represented by the entity view
PersonViewor more specifically the row in thepersontable
The following example illustrates a case where the relation type PersonView is not updatable,
but the relationship represented by the attribute owner is updatable.
@EntityView(Person.class)
interface PersonView {
@IdMapping
Long getId();
String getName();
}
@UpdatableEntityView
@EntityView(Cat.class)
interface CatUpdateView {
@IdMapping
Long getId();
String getName();
PersonView getOwner();
void setOwner(PersonView owner);
}
Even if the PersonView had a setName() method, changes done to that attribute would not be flushed, since PersonView is not updatable(@UpdatableEntityView).
Having only an updatable relationship role is very common, because it is rarely necessary to do cascading updates.
Note that it is also possible to just make the entity view type PersonView updatable(annotate @UpdatableEntityView) without the setter setOwner().
That way, the relationship role wouldn’t be allowed to change, but the changes to the underlying Person would be cascaded.
When the subview type is updatable(@UpdatableEntityView), updates are by default cascaded. If the subview type is also creatable(@CreatableEntityView), persists are also cascaded.
To disable or fine tune this behavior, it is possible to annotate the attribute getter with @UpdatableMapping and specify the cascade attribute.
Apart from defining which CascadeType is enabled, it is also possible to restrict the allowed subtypes via the attributes subtypes, persistSubtypes and updateSubtypes.
By default, instances of the declared type i.e. the compile time attribute type, are allowed to be set as attribute values.
Subtypes that are non-updatable and non-creatable are also allowed.
If the attribute defines UPDATE cascading or the declared type is updatable(@UpdatableEntityView), all updatable subtypes are also allowed.
If the attribute defines PERSIST cascading or the declared type is creatable(@CreatableEntityView), all creatable subtypes are also allowed.
In case of immutable or non-updatable subview types the method EntityViewManager.getReference(Class viewType, Object id) might come in handy.
This method allows to retrieve an instance of the given view type having the defined identifier. This is very useful for cases when just a relationship role like e.g. owner should be set without the need to query PersonView objects.
A common use case might be to set the tenant which owns an object. There is no need to query the tenant as the information is unnecessary for simply setting the relationship role, but the tenant’s identity is known.
To be able to encapsulate the creation of subviews or the access to references for subviews it is recommended to make use of the special EntityViewManager getter method.
The idea is to define an abstract getter method with protected or default visibility returning an EntityViewManager. Methods that create subviews or want a reference to a subview by id can then invoke the getter to get access to the EntityViewManager.
7.5.3. Flat view mappings
Updatable flat view mappings are currently only supported for embeddable types. An updatable flat view type is also always creatable. Flat views are always flushed as whole objects, which means that an updatable flat view should always at least map all attributes as read-only. Read-only i.e. non-updatable attributes are passed-through to the embeddable object when recreating it.
Apart from that, a flat view is just like a normal subview.
7.5.4. Subquery & parameter mappings
Since subqueries and parameter mappings aren’t bidirectional, attributes using these kinds of mappings are never considered to be updatable.
7.5.5. Entity mappings
Entity types are similar to subview types as they have an identity and are specially handled when loading and merging data.
Since entity types are mutable by design, PERSIST and UPDATE cascading are by default enabled for attributes that use entity types.
The cascading can be overridden by defining the cascade type via a @UpdatableMapping annotation on the attribute.
Note that the handling of entity types can be fine tuned by registering a basic user type.
@UpdatableEntityView
@EntityView(Cat.class)
interface CatUpdateView {
@IdMapping
Long getId();
@UpdatableMapping(cascade = { CascadeType.UPDATE }) (1)
Cat getFather();
void setFather(Cat father);
}
| 1 | Defines that only updates are cascaded. Unknown i.e. new Cat instances aren’t persisted |
Changes that are done via setFather() will update the father attribute in the entity model when flushed.
If query flushing is configured, a query like the following will be generated when updating the father relation.
UPDATE Cat cat SET cat.father = :father WHERE cat.id = :id
7.5.6. Collection mappings
Updatable collection mappings must be simple paths referring to a collection of the backing entity type. Paths to a nested collection like e.g. owner.kittens are not allowed.
Currently, a collection attribute is considered to be updatable if a setter for the attribute exists, or @UpdatableMapping is declared on the getter method of an attribute.
| At this point, collections can not be remapped automatically yet, so you have to use the same collection type as in the entity model. |
Updates to owned collection are currently simply replayed on the collection of an entity reference. Note that currently only inverse collections are considered not owned i.e. don’t require loading the real collection for doing updates.
@UpdatableEntityView
@EntityView(Cat.class)
interface CatUpdateView {
@IdMapping
Long getId();
Set<Cat> getKittens();
void setKittens(Set<Cat> kittens);
}
Any modification done to a collection
CatUpdateView view = ...; // Update the view Cat newKitten = entityManager.find(Cat.class, 2L); view.getKittens().add(newKitten); // Flush the changes to the persistence context entityViewManager.update(entityManager, view);
Will be applied on the collection of an entity reference during update() as if the following was done.
CatUpdateView view = ...; // Actually a query that loads the graph being dirty is issued Cat cat = entityManager.find(Cat.class, view.getId()); cat.getKittens().add(newKitten);
Since the kittens collection is dirty i.e. a new kitten was added and the collection is owned by the Cat entity, it will be loaded along with the Cat.
If kittens were an inverse collection, it wouldn’t need loading during flushing as adding the new kitten would be a matter of issuing an update query or persisting an entity.
7.5.7. Inverse mappings
Changes to inverse relations like OneToOne’s and *ToMany collections are flushed by persisting, updating or removing the inverse relation objects. There is no special mapping required. If the entity model defines that an attribute is an inverse mapping by specifying a mappedBy, updatable entity view attributes mapping to such attributes automatically discover the mappedBy configuration and will cause the attribute being maintained by managing inverse relation objects.
There are several strategies that can be configured to handle the removal of elements via the removeStrategy attribute of @MappingInverse
-
IGNORE- The default. Ignores elements that have been removed i.e. does not maintain the relationship automatically. -
REMOVE- Removes the inverse relation object when determined to be removed from the inverse relationship. -
SET_NULL- Sets the mappedBy attribute toNULLon the inverse relation object when found to be removed from the inverse relationship.
@UpdatableEntityView
@EntityView(Person.class)
interface PersonUpdateView {
@IdMapping
Long getId();
// mappedBy = "owner"
@MappingInverse(removeStrategy = InverseRemoveStrategy.REMOVE)
Set<Cat> getKittens();
void setKittens(Set<Cat> kittens);
}
A modification of the kittens collection…
PersonUpdateView view = ...; // Update the view view.getKittens().remove(someKitten); // Flush the changes to the persistence context entityViewManager.update(entityManager, view);
will cause the Cat someKitten to be removed.
DELETE Cat c WHERE c.id = :someKittenId
If the SET_NULL strategy were used, the owner would be set to NULL
UPDATE Cat c SET owner = NULL WHERE c.id = :someKittenId
7.6. Locking support
Blaze Persistence entity views by default automatically makes use of a version field mapped in the entity type for optimistic locking.
This is controlled by the lockMode attribute on the @UpdatableEntityView annotation which by default is set to AUTO.
-
LockMode.AUTO- The default. Uses the version field of the entity type the entity view is referring to for optimistic locking -
LockMode.OPTIMISTIC- Forces the use of optimistic locking based on the entity version field -
LockMode.PESSIMISTIC_READ- Acquires a JPAPESSIMISTIC_READlock when reading the entity view -
LockMode.PESSIMISTIC_WRITE- Acquires a JPAPESSIMISTIC_WRITElock when reading the entity view -
LockMode.NONE- Don’t use any locking even if a version attribute is available
By default, all updatable attributes in an entity view are protected by optimistic locking.
This means that if the value of an attribute was changed, the change will be flushed with the optimistic lock condition.
Attribute changes that should be excluded from optimistic locking can be annotated with @OptimisticLock(exclude = true) to prevent the optimistic lock condition
when only such attributes are changed.
The entity type for which the optimistic lock condition is asserted is called the lock owner.
If the entity type of an entity view does not have a version field and the LockMode.AUTO is used, the parent entity view type is considered being the lock owner.
If the parent has no version field, it’s parent is considered and so forth. If no lock owner can be found, no optimistic locking is done.
When specifying a lock mode other than LockMode.AUTO, the entity object for an entity view becomes the lock owner.
By annotating @LockOwner on an updatable entity view type, a custom lock owner can be defined.
| This is still in development, so not all features might be available yet. Also see https://github.com/Blazebit/blaze-persistence/issues/439 and https://github.com/Blazebit/blaze-persistence/issues/438 for more information. |
7.7. Persist and Update cascading
The cascade types defined in Blaze Persistence entity views have different semantics than what JPA offers and should not be mixed up.
JPA defines cascade types for logical operations whereas Blaze Persistence entity views defines cascade types for state changes.
In a JPA entity, one can define for which operations the changes done to an attribute should be flushed.
For example the JPA CascadeType.PERSIST will cause a flush of an attributes affected values only if the owning entity is about to be persisted.
Blaze Persistence entity views cascade types define whether a value of an attribute may do a specific state transition.
If an attribute defines CascadeType.PERSIST, it means that new objects i.e. the ones created via EntityViewManager.create(),
are allowed to be used as values and that these object should be persisted during flushing.
Updates done to mutable values of an attribute are only flushed if the CascadeType.UPDATE is enabled.
Normally, the update or persist cascading is enabled for all subtypes of the declared attribute type,
but can be restricted by specifying specific subtypes for which to allow updates or persists.
This can be done via the subtypes attribute of the @UpdatableMapping or the updateSubtypes or persistSubtypes attributes for the corresponding cascade types.
7.8. Cascading deletes and orphan removal
Delete cascading and orphan removal have the same semantics as in JPA. If you delete an entity A that refers to entity B through an attribute that defines delete cascading, entity B is going to be deleted as well. When removing a reference from entity A to entity B through an attribute that defines orphan removal, entity B is going to be deleted. Orphan removal also implies delete cascading, so entity B is also deleted when deleting entity A.
Most JPA implementations only support cascading deletes and orphan removal for managed entities whereas DML statements for the entity types do not consider this configuration. Blaze Persistence respects the settings all the way, even for the removal by id action done via EntityViewManager.remove(EntityManager, Class, Object). When an entity graph for an entity view type has an arbitrary depth relationship, Blaze Persistence still has to do some entity data loading, but it tries to reduce the executed statements as much as possible.
| At some point, DML statements might be grouped together via Updatable CTEs for DBMS that support that. For more information about that, see https://github.com/Blazebit/blaze-persistence/issues/500 |
To enable delete cascading for an attribute, the CascadeType.DELETE has to be added to the cascade attribute of a @UpdatableMapping
@UpdatableEntityView
@EntityView(Cat.class)
interface CatUpdateView {
@IdMapping
Long getId();
@UpdatableMapping(cascade = { CascadeType.DELETE })
Person getOwner();
}
When deleting a Cat like the following
entityViewManager.remove(entityManager, CatUpdateView.class, catId);
the owner is going to be deleted along with the Cat. The delete cascading even works for attributes that are only defined to do delete cascading in the entity.
Assuming Cat does not have the arbitrary depth relationship kittens, the removal might trigger the following logical JPQL statements.
DELETE Cat(nickNames) cat WHERE cat.id = :catId DELETE Cat cat WHERE cat.id = :catId RETURNING owner.id DELETE Person person WHERE person.id = :ownerId
First, the cascading delete enabled collections like e.g. the nickNames collection is deleted.
Then the Cat is deleted and while doing that, the ids of the *ToOne relations with enabled cascading deletes like e.g. the owner’s id are returned.
For DBMS not supporting the RETURNING clause for DML statements, a SELECT statement is issued before the DELETE to extract the ids of the *ToOne relations.
Finally, the cascading deletes for the *ToOne relations are done e.g. the Person is deleted.
| A future strategy for deletion might facilitate temporary tables if the DBMS supports it rather than selecting. For more information see https://github.com/Blazebit/blaze-persistence/issues/220 |
If the entity type for an updatable entity view uses delete cascading or orphan removal for an attribute, an updatable mapping for that attribute must use these configurations as well.
So if the entity type uses delete cascading for the owner of Cat, it would be an error to omit the delete cascading configuration.
@UpdatableEntityView
@EntityView(Cat.class)
interface CatUpdateView {
@IdMapping
Long getId();
@UpdatableMapping(cascade = { }) (1)
Person getOwner();
}
| 1 | Can’t omit delete cascading if entity attribute uses delete cascading |
The same goes for orphan removal and the idea behind this is, that it makes delete cascading and orphan removal configurations visible in every updatable view, thus making it less surprising. It would make no sense to allow disabling delete cascading or orphan removal configurations because then the entity flush strategy would produce different results than the query flush strategy. Obviously the other way around i.e. enabling delete cascading or orphan removal if the entity attribute does not use these configurations, is very valid. Sometimes there are cases where delete cascading or orphan removal shouldn’t be done which means the cascading can’t be configured on the entity type attributes. This where Blaze Persistence entity views show their strength as they allow to control these configurations on a per-use case basis.
7.9. Conversion support
As explained in the beginning, the vision for updatable entity views is to support the modelling of use case specific write models. Although most of the data that is generally updatable is mostly loaded once when starting a conversation it is rarely necessary to make it updatable right away. Some use cases might require only a subset of the data to be updatable, while others require a different subset. To support modelling this appropriately it is possible to convert between entity views types.
Imagine the following model for illustration purposes.
@EntityView(Cat.class)
interface KittenView {
@IdMapping
Long getId();
}
@EntityView(Cat.class)
interface CatBaseView extends KittenView {
PersonView getOwner();
Set<KittenView> getKittens();
}
@UpdatableEntityView
@EntityView(Cat.class)
interface CatOwnerUpdateView extends CatBaseView {
@UpdatableMapping
PersonView getOwner();
void setOwner(PersonView owner);
}
@UpdatableEntityView
@EntityView(Cat.class)
interface CatKittenUpdateView extends CatBaseView {
@UpdatableMapping
Set<KittenView> getKittens();
}
When navigating to the detail UI for a Cat the CatBaseView would be loaded.
If the UI had a special action to initiate a transfer to a different owner, doing that action would lead to the conversion of the CatBaseView to the CatOwnerUpdateView.
CatBaseView catBaseView = //... CatOwnerUpdateView catOwnerUpdate = entityViewManager.convert(CatOwnerUpdateView.class, catBaseView);
After setting the new owner and flushing the changes via EntityViewManager.update(EntityManager, Object) the view is converted back to the base view by invoking EntityViewManager.convert(Class, Object, ConvertOption…) again.
CatOwnerUpdateView catOwnerUpdate = //... catBaseView = entityViewManager.convert(CatBaseView.class, catBaseView);
When initiating the kitten update action the conversion would be done to CatKittenUpdateView.
Keep in mind that most UIs do not necessarily work this way and that the added complexity might not be beneficial in all cases. Although this mechanism enables a clear separation for use cases, it might just as well be the case, that use cases are so small that it is better to have just a single write model. In some special cases like e.g. when simply changing a status of an object, it might not even be necessary to have an explicit write model. For such cases it is often more appropriate to have a specialized service method.
Note that internally, the conversion feature is used for converting successfully persisted creatable entity views to their context specific declaration type.
There are of course other possible use cases for this feature like e.g. conversion from a more detailed view to a view containing only a subset of the information, though it is recommended to query the view with the subset of information rather than querying more if possible/practical to not do unnecessary data loading.
8. BasicUserType SPI
Just like JPA providers offer an SPI to make use of custom types for basic values, Blaze Persistence also does.
For read models, the type isn’t very important as the JPA provider handles the construction of the values and only provides entity views with object instance.
Since write models need to handle change detection and mutability aspects of basic types i.e. non-subview type, the BasicUserType interface SPI is needed.
8.1. Supported types
There are several well known types registered out of the box.
-
boolean,java.lang.Boolean -
char,java.lang.Character -
byte,java.lang.Byte -
short,java.lang.Short -
int,java.lang.Integer -
long,java.lang.Long -
float,java.lang.Float -
double,java.lang.Double -
java.lang.String -
java.math.BigInteger,java.math.BigDecimal -
java.util.Date,java.sql.Time,java.sql.Date,java.sql.Timestamp -
java.util.Calendar,java.util.GregorianCalendar -
java.util.TimeZone,java.lang.Class -
java.util.UUID,java.net.URL -
java.util.Locale,java.util.Currency -
byte[],java.lang.Byte[] -
char[],java.lang.Character[] -
java.io.InputStream,java.sql.Blob -
java.sql.Clob,java.sql.NClob
If found on the classpath, types for the following classes are registered
-
java.time.LocalDate,java.time.LocalDateTime,java.time.LocalTime -
java.time.OffsetTime,java.time.OffsetDateTime,java.time.ZonedDateTime -
java.time.Duration,java.time.Instant -
java.time.MonthDay,java.time.Year,java.time.YearMonth,java.time.Period -
java.time.ZoneId,java.time.ZoneOffset
If you miss a type you can register it via EntityViewConfiguration.registerBasicUserType(Class type, BasicUserType userType).
8.2. Type support for write models
When a basic type is used in a write model, it is very important that an appropriate BasicUserType is registered.
If no basic user type is registered for a type, by default the com.blazebit.persistence.view.spi.type.MutableBasicUserType is used.
This basic user type assume the type is mutable which will cause values of that type to always be assumed being dirty.
Updatable entity views containing values of such a type are thus always considered being dirty which has the effect, that every call to
EntityViewManager.update(Object view)
will cause a flush of attributes containing that value.
The updatable-entity-view-change-model-api is also affected of this by always reporting such attributes as being dirty.
Immutable types, like e.g. java.lang.String already does, can use the basic user type implementation com.blazebit.persistence.view.spi.type.ImmutableBasicUserType
which assumes objects of the type are immutable.
A proper basic user type implementation for mutable types, when based on the provided type com.blazebit.persistence.view.spi.type.AbstractMutableBasicUserType
only needs an implementation for cloning a value. The cloned value is used to e.g. keep the initial state so that later changes can be detected by checking equality.
8.3. Type support for JPA managed types
JPA managed types are also considered mutable by default, and since no dirty tracking information is available by default, objects of that such types are always considered dirty thus also always flushed. An integration with the native dirty tracking mechanism of the JPA provider might improve performance and will be considered in future versions. Entity types that handle change tracking manually, can implement a custom basic user type to improve the performance for usages of that entity type within updatable entity views, but are generally recommended to switch to subviews instead.
For further information on the possible SPI methods consult the JavaDoc of the BasicUserType interface
8.4. Optimistic locking version type support
To allow an attribute to be used as version for optimistic locking, the registered basic type also needs to implement the com.blazebit.persistence.view.spi.type.VersionBasicUserType interface.
This type additionally requires to provide an implementation for returning the next version based on a given current version.
9. TypeConverter API
The TypeConverter API is similar to the JPA AttributeConverter API as it allows to convert between an entity view model type and an underlying type.
This is similar to the BasicUserType SPI but can also be used to convert view types to custom types.
All this might sound very generic, but it is the foundation for the support of wrapping a type in a java.util.Optional.
A TypeConverter is responsible for figuring out the actual underlying type of an entity view attribute type.
In case of an attribute like e.g. Optional<Integer> getId() the TypeConverter for the java.util.Optional support determines the underlying type which is Integer.
Apart from this, the TypeConverter must also implement the conversion from the view type to the underlying type and the other way around.
9.1. Builtin TypeConverters
There are several TypeConverters registered out of the box.
-
Converters for
java.sql.Blob,java.sql.Clob,java.sql.NClobto implement dirty tracking in coordination with a customBasicUserType.
If found on the classpath, TypeConverters for the following types are registered
-
java.util.Optionalfor all Object types -
java.util.OptionalIntforjava.lang.Integer -
java.util.OptionalLongforjava.lang.Long -
java.util.OptionalDoubleforjava.lang.Double -
java.time.LocalDatefor entity types-
java.util.Date -
java.sql.Date -
java.sql.Timestamp -
java.util.Calendar -
java.util.GregorianCalendar
-
-
java.time.LocalDateTimefor entity types-
java.util.Date -
java.sql.Timestamp -
java.util.Calendar -
java.util.GregorianCalendar
-
-
java.time.LocalTimeforjava.sql.Time
If you miss a TypeConverter you can register it via EntityViewConfiguration.registerTypeConverter(Class entityModelType, Class viewModelType, TypeConverter typeConverter).
10. Updatable Entity View Change Model
Updatable entity views are not only better write model DTOs, but also allow to retrieving logical changes via the ChangeModel API. Using updatable entity views allows the persistence model to be efficiently updated, but the cost for doing that is hiding the persistent/initial state from the user. Oftentimes part of the persistent/initial state is compared with values that are about to be written to detect logical changes. Since updatable entity views handle the persistent state behind the scenes, such a manual comparison isn’t possible. Thanks to the ChangeModel API it is unnecessary.
The ChangeModel API entry point is
EntityViewManager.getChangeModel(Object view)
and returns the change model for a given updatable entity view.
A change model instance provides access to the initial and current state of an object and the ChangeKind of a change model.
Singular change models also give access to the change models of the respective attributes of an entity view type.
Plural change models additionally give access to the added, removed and mutated element change models.
A map change model also allows to distinguish between element and key change models.
10.1. Change Model API overview
To detect if a model or one of it’s child models is dirty, one can use the ChangeModel.isDirty() method.
The actual change models of dirty elements within a SingularChangeModel can be retrieved via SingularChangeModel.getDirtyChanges().
Only attributes of the queried object are reported as change models i.e. only a single level.
The singular change models allow access to the attributes change models either via attribute path or via the metamodel attribute objects by using one of the overloaded
SingularChangeModel.get(String attributePath) methods.
The term path implicates a nested attribute access is possible, which is the case, but beware that accessing attributes of collection elements will result in an exception
unless the SingularChangeModel.getAll(String attributePath) variant is used
which returns a list of change models instead of a single one.
Another notable feature the singular change model provides is the checking for dirtyness of a specific attribute path. Instead of materializing every change model
along the path, the SingularChangeModel.isDirty(String attributePath) method
only reports the dirtyness of the object accessible through the given attribute path.
A variant of this method SingularChangeModel.isChanged(String attributePath)
will return early if one of the parent attributes was updated i.e. the identity was changed.
The plural change model is similar in the respect that it provides analogous methods that simply return a list of change models instead of a single one.
It also allows to access the change models of the added, removed or mutated elements separately.
To access all dirty changes similar to what is possible with SingularChangeModel#getDirtyChanges(), plural change models provide the method
PluralChangeModel.getElementChanges() for doing the same.
The map change model additionally allows to differentiate between changes to key objects and element objects. It offers methods to access the key changes
as well as the overall object changes with analogously named methods getAddedObjects(), getAddedKeys() etc.
10.2. Transaction support
The change model implementation gains it’s insights by inspecting the dirty tracking information of the actual objects. Since a transaction commit will flush dirty changes i.e. the dirtyness is resetted, change model objects won’t report any dirty changes after a commit. If information about the change models should be retained after a transaction commit, it must be serialized with a custom mechanism. When a rollback occurs, the dirtyness is restored to be able to commit again after doing further changes which also means that change models will work as expected.
10.3. User type support
The Change Model API builds on top of the BasicUserType foundation and it is thus essential to have a correct implementation for the type.
Unknown types are considered mutable which has the effect, that objects of that type are always considered dirty. Provide a deepClone implementation or mark the type as immutable to avoid this.
|
11. Spring Data integration
Apart from a plain Spring integration which is handy for configuring and providing an EntityViewManager for injection,
there is also a Spring Data integration module which tries to make using entity views with Spring Data as convenient as using entities.
11.1. Setup
To setup the project for Spring Data you have to add dependencies as described in the Setup section
and make beans available for CriteriaBuilderFactory and EntityViewManager instances as laid out in the Spring environment section.
In short, the following Maven dependencies are required
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-spring-data-2.x</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-hibernate-5.2</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
If you still work with Spring Data 1.x you will have to use a different integration as Spring Data 2.x changed quite a bit.
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-spring-data-1.x</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
The dependencies for other JPA providers or other versions can be found in the core module setup section.
A possible bean configuration for the required beans CriteriaBuilderFactory and EntityViewManager in short might look like this.
@Configuration
public class BlazePersistenceConfiguration {
@PersistenceUnit
private EntityManagerFactory entityManagerFactory;
@Bean
@Scope(ConfigurableBeanFactory.SCOPE_SINGLETON)
@Lazy(false)
public CriteriaBuilderFactory createCriteriaBuilderFactory() {
CriteriaBuilderConfiguration config = Criteria.getDefault();
// do some configuration
return config.createCriteriaBuilderFactory(entityManagerFactory);
}
}
@Configuration
public class BlazePersistenceConfiguration {
@Bean
@Scope(ConfigurableBeanFactory.SCOPE_SINGLETON)
@Lazy(false)
// inject the criteria builder factory which will be used along with the entity view manager
public EntityViewManager createEntityViewManager(CriteriaBuilderFactory cbf, EntityViewConfiguration entityViewConfiguration) {
return entityViewConfiguration.createEntityViewManager(cbf);
}
}
When enabling JPA repositories, make sure you configure BlazePersistenceRepositoryFactoryBean as repositoryFactoryBeanClass.
Optionally specify a custom basePackage for repository class scanning and a custom entityManagerFactoryRef.
@EnableJpaRepositories(repositoryFactoryBeanClass = BlazePersistenceRepositoryFactoryBean.class)
11.2. Features
The integration comes with a convenience base interface com.blazebit.persistence.spring.data.repository.EntityViewRepository
that you can use for your repository definitions.
Assume we have the following entity view:
@EntityView(Cat.class)
public interface SimpleCatView {
@IdMapping
public getId();
String getName();
@Mapping("LOWER(name)")
String getLowerCaseName();
Integer getAge();
}
A very simple repository might look like this:
@Transactional(readOnly = true)
public interface SimpleCatViewRepository extends EntityViewRepository<SimpleCatView, Long> {
List<SimpleCatView> findByLowerCaseName(String lowerCaseName);
}
Since we use EntityViewRepository as a base interface we inherit the most commonly used repository methods. You can now use this repository as any other Spring Data repository:
@Controller
public class MyCatController {
@Autowired
private SimpleCatViewRepository simpleCatViewRepository;
public Iterable<SimpleCatView> getCatDataForDisplay() {
return simpleCatViewRepository.findAll();
}
public SimpleCatView findCatByName(String name) {
return simpleCatViewRepository.findByLowerCaseName(name.toLowerCase());
}
}
Spring Data Specifications can be used without restrictions. There is also the convenience base interface com.blazebit.persistence.spring.data.repository.EntityViewSpecificationExecutor that can be extended from.
@Transactional(readOnly = true)
public interface SimpleCatViewRepository extends EntityViewRepository<SimpleCatView, Long>, EntityViewSpecificationExecutor<SimpleCatView, Cat> {
}
@Controller
public class MyCatController {
@Autowired
private SimpleCatViewRepository simpleCatViewRepository;
public Iterable<SimpleCatView> getCatDataForDisplay(final int minAge) {
return simpleCatViewRepository.findAll(new Specification<Cat>() {
@Override
public Predicate toPredicate(Root<Cat> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
return criteriaBuilder.ge(root.<Integer>get("age"), minAge);
}
});
}
The integration handles ad-hoc uses of @EntityGraph by adapting the query generation through call of CriteriaBuilder.fetch() rather than passing the entity graphs as hints.
Another notable feature the integration provides is the support for the return type KeysetAwarePage as a replacement for Page.
By using KeysetAwarePage the keyset pagination feature is enabled for the repository method.
@Transactional(readOnly = true)
public interface KeysetAwareCatViewRepository extends Repository<Cat, Long> {
KeysetAwarePage<SimpleCatView> findAll(Pageable pageable);
}
Note that the Pageable should be an instance of KeysetPageable if keyset pagination should be used. A KeysetPageable can be retrieved through the KeysetAwarePage or manually
by constructing a KeysetPageRequest. Note that constructing a KeysetPageRequest or actually the contained KeysetPage manually is not recommended. When working with Spring MVC,
the Spring Data Rest integration might come in handy. For stateful server side frameworks, it’s best to put the KeysetAwarePage into a session like storage
to be able to use the previousOrFirst() and next() methods for retrieving KeysetPageable objects.
All other Spring Data repository features like restrictions, pagination, slices and ordering are supported as usual. Please consult the Spring Data documentation for further information.
11.3. Spring Data Rest integration
The Spring Data Rest integration offers similar pagination features for keyset pagination to what Spring Data already offers for normal pagination. First, a keyset pagination enabled repository is needed.
@Transactional(readOnly = true)
public interface KeysetAwareCatViewRepository extends Repository<Cat, Long> {
KeysetAwarePage<SimpleCatView> findAll(Pageable pageable);
}
A controller can then use this repository like the following:
@Controller
public class MyCatController {
@Autowired
private KeysetAwareCatViewRepository simpleCatViewRepository;
@RequestMapping(path = "/cats", method = RequestMethod.GET)
public Page<SimpleCatView> getCats(@KeysetConfig(Cat.class) KeysetPageable pageable) {
return simpleCatViewRepository.findAll(pageable);
}
Note that Blaze Persistence imposes some very important requirements that have to be fulfilled
-
There must always be a sort specification
-
The last sort specification must be the entity identifier
For the keyset pagination to kick in, the client has to remember the values by which the sorting is done of the first and the last element of the result.
The values then need to be passed to the next request as JSON encoded query parameters. The values of the first element should use the parameter lowest and the last element the parameter highest.
The following will illustrate how this works.
First, the client makes an initial request.
GET /cats?page=0&size=3&sort=id,desc
{
content: [
{ id: 10, name: 'Felix', age: 10 },
{ id: 9, name: 'Robin', age: 4 },
{ id: 8, name: 'Billy', age: 7 }
]
}
It’s the responsibility of the client to remember the attributes by which it sorts of the first and last element.
In this case, {id: 10} will be remembered as lowest and {id: 8} as highest. The client also has to remember the page and size which was used to request this data.
When the client then wants to switch to the next page, it has to pass lowest and highest as parameters as well as prevPage representing the page that was used before.
Note that the following is just an example for illustration. Stringified JSON objects in JavaScript should be encoded view encodeURI() before being used as query parameter.
GET /cats?page=1&size=3&sort=id,desc&prevPage=0&lowest={id:10}&highest={id:8}
{
content: [
{ id: 7, name: 'Kitty', age: 1 },
{ id: 6, name: 'Bob', age: 8 },
{ id: 5, name: 'Frank', age: 14 }
]
}
This will make use of keyset pagination as can be seen by looking at the generated JPQL or SQL query.
Note that the client should drop or forget the lowest, highest and prevPage values when
-
the page size changes
-
the sorting changes
-
the filtering changes
For a full AngularJS example see the following example project.
12. DeltaSpike Data integration
Blaze Persistence provides an integration with DeltaSpike Data to create entity view based repositories.
12.1. Setup
To setup the project for DeltaSpike Data you have to add the entity view and CDI integration dependencies as described in the getting started section along with the integration dependencies for your JPA provider as described in the core module setup section.
In addition, the following Maven dependencies are required:
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-deltaspike-data-api</artifactId>
<version>${blaze-persistence.version}</version>
<scope>compile</scope>
</dependency>
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-deltaspike-data-impl-1.8</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
If you still work with DeltaSpike Data 1.7 you will have to use a different integration as DeltaSpike Data 1.8 changed quite a bit.
<dependency>
<groupId>com.blazebit</groupId>
<artifactId>blaze-persistence-integration-deltaspike-data-impl-1.7</artifactId>
<version>${blaze-persistence.version}</version>
<scope>runtime</scope>
</dependency>
You also need to make beans available for CriteriaBuilderFactory and EntityViewManager as laid out in the
CDI environment section.
12.2. Features
To mark a class or an interface as repository, use the DeltaSpike org.apache.deltaspike.data.api.Repository annotation.
@Repository(forEntity = Cat.class)
public interface CatViewRepository {
List<SimpleCatView> findByLowerCaseName(String lowerCaseName);
}
The integration provides the following base interfaces that you may optionally extend to define entity view repositories:
-
com.blazebit.persistence.deltaspike.data.api.EntityViewRepositoryprovides simple base methods. -
com.blazebit.persistence.deltaspike.data.api.FullEntityViewRepositoryadds JPA criteria support to thecom.blazebit.persistence.deltaspike.data.api.EntityViewRepositoryinterface.
@Repository
public abstract class CatViewRepository extends FullEntityViewRepository<Cat, SimpleCatView, Long> {
public List<SimpleCatView> findByAge(final int minAge) {
return criteria().gt(Cat_.age, minAge)
.select(SimpleCatView.class).orderAsc(Cat_.id).getResultList();
}
}
Similar to what Spring Data offers, it is also possible to make use of a Specification which essentially is a callback that allows to refine a query.
@Repository(forEntity = Cat.class)
public interface SimpleCatViewRepository {
List<SimpleCatView> findAll(Specification spec);
}
@Path("cats")
public class MyCatController {
@Inject
private SimpleCatViewRepository simpleCatViewRepository;
@GET
public List<SimpleCatView> getCatDataForDisplay(@QueryParam("minage") final int minAge) {
return simpleCatViewRepository.findAll(new Specification<Cat>() {
@Override
public Predicate toPredicate(Root<Cat> root, CriteriaQuery<?> criteriaQuery, CriteriaBuilder criteriaBuilder) {
return criteriaBuilder.ge(root.<Integer>get("age"), minAge);
}
});
}
The integration handles ad-hoc uses of @EntityGraph by adapting the query generation through call of CriteriaBuilder.fetch() rather than passing the entity graphs as hints.
Another notable feature the integration provides is the support for a Pageable object with Page return type similar to what Spring Data offers.
The integration also supports the return type KeysetAwarePage. By using KeysetAwarePage the keyset pagination feature is enabled for the repository method.
@Repository(forEntity = Cat.class)
public interface KeysetAwareCatViewRepository {
KeysetAwarePage<SimpleCatView> findAll(Pageable pageable);
}
Note that the Pageable should be an instance of KeysetPageable if keyset pagination should be used. A KeysetPageable can be retrieved through the KeysetAwarePage or manually
by constructing a KeysetPageRequest. Note that constructing a KeysetPageRequest or actually the contained KeysetPage manually is not recommended. When working with JAX-RS,
the DeltaSpike Data Rest integration might come in handy. For stateful server side frameworks, it’s best to put the KeysetAwarePage into a session like storage
to be able to use the previousOrFirst() and next() methods for retrieving KeysetPageable objects.
All other DeltaSpike Data repository features like restrictions, explicit offset pagination, returning QueryResult and others are supported as usual.
Please consult the DeltaSpike Data documentation for further information.
12.3. DeltaSpike Data Rest integration
The DeltaSpike Data Rest integration offers similar pagination features for normal and keyset pagination to what Spring Data offers for normal pagination. First, a keyset pagination enabled repository is needed.
@Repository(forEntity = Cat.class)
public interface KeysetAwareCatViewRepository {
KeysetAwarePage<SimpleCatView> findAll(Pageable pageable);
}
A controller can then use this repository like the following:
@Path("cats")
public class MyCatController {
@Inject
private KeysetAwareCatViewRepository simpleCatViewRepository;
@GET
public Page<SimpleCatView> getCats(@KeysetConfig(Cat.class) KeysetPageable pageable) {
return simpleCatViewRepository.findAll(pageable);
}
Note that Blaze Persistence imposes some very important requirements that have to be fulfilled
-
There must always be a sort specification
-
The last sort specification must be the entity identifier
For the keyset pagination to kick in, the client has to remember the values by which the sorting is done of the first and the last element of the result.
The values then need to be passed to the next request as JSON encoded query parameters. The values of the first element should use the parameter lowest and the last element the parameter highest.
The following will illustrate how this works.
First, the client makes an initial request.
GET /cats?page=0&size=3&sort=id,desc
{
content: [
{ id: 10, name: 'Felix', age: 10 },
{ id: 9, name: 'Robin', age: 4 },
{ id: 8, name: 'Billy', age: 7 }
]
}
It’s the responsibility of the client to remember the attributes by which it sorts of the first and last element.
In this case, {id: 10} will be remembered as lowest and {id: 8} as highest. The client also has to remember the page and size which was used to request this data.
When the client then wants to switch to the next page, it has to pass lowest and highest as parameters as well as prevPage representing the page that was used before.
Note that the following is just an example for illustration. Stringified JSON objects in JavaScript should be encoded view encodeURI() before being used as query parameter.
GET /cats?page=1&size=3&sort=id,desc&prevPage=0&lowest={id:10}&highest={id:8}
{
content: [
{ id: 7, name: 'Kitty', age: 1 },
{ id: 6, name: 'Bob', age: 8 },
{ id: 5, name: 'Frank', age: 14 }
]
}
This will make use of keyset pagination as can be seen by looking at the generated JPQL or SQL query.
Note that the client should drop or forget the lowest, highest and prevPage values when
-
the page size changes
-
the sorting changes
-
the filtering changes
For a full AngularJS example see the following example project.
13. Metamodel
The metamodel for entity views is very similar to the JPA metamodel and the entry point is ViewMetamodel
which can be acquired through EntityViewManager.getMetamodel()
It allows access to views(ViewType) and flat views(FlatViewType) which both are subtypes of managed views(ManagedViewType).
The only difference between the two is that a flat view has no id mapping, so it’s identity is composed of all attributes
which results in some limitations as described in the flat view mapping section.
A view can have multiple named constructors that have parameter attributes. Additionally, a view can also have multiple named view filters. Every managed view has attributes which are structured based on the arity(singular or plural), the mapping type(parameter or method) and correlation type(normal, subquery or correlated).
An attribute is always either an instance of ParameterAttribute or MethodAttribute depending on whether it is defined on a constructor as parameter or as getter method.
A parameter attribute is defined by it’s index and it’s declaring MappingConstructor.
Method attributes have a name, may have multiple named attribute filters and might possibly be updatable.
A singular attribute is always an instance of SingularAttribute and is given if isCollection() returns false.
If it is a subquery i.e. isSubquery() returns true, it is also an instance of SubqueryAttribute.
If it is correlated i.e. isCorrelated() returns true, it is also an instance of CorrelatedAttribute.
If it is neither a subquery nor correlated, it is going to be an instance of MappingAttribute.
A plural attribute is always an instance of PluralAttribute and is given if isCollection() return true.
Since plural attributes can’t be defined via a subquery mapping, it is never an instance of SubqueryAttribute.
If it is correlated i.e. isCorrelated() returns true, it is also an instance of CorrelatedAttribute, otherwise it is going to be an instance of MappingAttribute.
Depending on the collection type returned by getCollectionType a plural attribute is also an instance of
-
CollectionAttributeifCollectionType.COLLECTION -
ListAttributeifCollectionType.LIST -
SetAttributeifCollectionType.SET -
MapAttributeifCollectionType.MAP
14. Configuration
Blaze Persistence can be configured by setting properties on a com.blazebit.persistence.view.spi.EntityViewConfiguration object and creating a EntityViewManager from it.
14.1. Configuration properties
14.1.1. PROXY_EAGER_LOADING
Defines whether proxy classes for entity views should be created eagerly when creating the EntityViewManager or on demand.
To improve startup performance this is deactivated by default. When using entity views in a clustered environment you might want to enable this!
| Key | com.blazebit.persistence.view.proxy.eager_loading |
|---|---|
Applicable |
Configuration only |
Type |
boolean |
Default |
false |
14.1.2. TEMPLATE_EAGER_LOADING
Defines whether entity view template objects should be created eagerly when creating the EntityViewManager or on demand.
To improve startup performance this is deactivated by default. In a production environment you might want to enable this so that templates don’t have to be built on-demand but are retrieved from a cache.
| Key | com.blazebit.persistence.view.eager_loading |
|---|---|
Applicable |
Configuration only |
Type |
boolean |
Default |
false |
14.1.3. PROXY_UNSAFE_ALLOWED
Defines whether proxy classes that support using the getter methods in a constructor should be allowed.
These proxy classes have to be defined via sun.misc.Unsafe to avoid class verification errors.
Disabling this property makes the use of the getter in the constructor return the default value for the property instead of the actual value.
| Key | com.blazebit.persistence.view.proxy.unsafe_allowed |
|---|---|
Applicable |
Configuration only |
Type |
boolean |
Default |
true |
14.1.4. EXPRESSION_VALIDATION_DISABLED
Defines whether the expressions of entity view mappings should be validated.
| Key | com.blazebit.persistence.view.expression_validation_disabled |
|---|---|
Applicable |
Configuration only |
Type |
boolean |
Default |
true |
14.1.5. DEFAULT_BATCH_SIZE
Defines the default batch size to be used for attributes that are fetched via the SELECT fetch strategy.
To specify the batch size of a specific attribute, append the attribute name after the "batch_size" like
e.g. com.blazebit.persistence.view.batch_size.subProperty
| Key | com.blazebit.persistence.view.batch_size |
|---|---|
Applicable |
Always |
Type |
int |
Default |
1 |
14.1.6. EXPECT_BATCH_CORRELATION_VALUES
Defines whether by default batching of correlation values or view root ids is expected for attributes that are fetched via the SELECT fetch strategy.
To specify the batch expectation of a specific attribute, append the attribute name after the "batch_correlation_values" like
e.g. com.blazebit.persistence.view.batch_correlation_values.subProperty
| Key | com.blazebit.persistence.view.batch_correlation_values |
|---|---|
Applicable |
Always |
Type |
boolean |
Default |
true |
14.1.7. UPDATER_EAGER_LOADING
Defines whether entity view updater objects should be created eagerly when creating the EntityViewManager or on demand.
To improve startup performance this is deactivated by default. In a production environment you might want to enable this so that updaters don’t have to be built on-demand but are retrieved from a cache.
| Key | com.blazebit.persistence.view.updater.eager_loading |
|---|---|
Applicable |
Configuration only |
Type |
boolean |
Default |
false |
14.1.8. UPDATER_FLUSH_MODE
Defines the flush mode the entity view updater objects should be using which is normally defined via @UpdatableEntityView(mode = ...).
This is a global override. To override the flush mode of a specific class, append the fully qualified class name after the "flush_mode" part like
e.g. com.blazebit.persistence.view.updater.flush_mode.com.test.MyUpdatableCatView.
| Key | com.blazebit.persistence.view.updater.flush_mode |
|---|---|
Applicable |
Configuration only |
Type |
String |
Values |
partial, lazy or full |
Default |
none |
14.1.9. UPDATER_FLUSH_STRATEGY
Defines the flush strategy the entity view updater objects should be using which is normally defined via @UpdatableEntityView(strategy = ...).
This is a global override. To override the flush strategy of a specific class, append the fully qualified class name after the "flush_strategy" part like
e.g. com.blazebit.persistence.view.updater.flush_strategy.com.test.MyUpdatableCatView.
| Key | com.blazebit.persistence.view.updater.flush_strategy |
|---|---|
Applicable |
Configuration only |
Type |
String |
Values |
entity or query |
Default |
none |